What makes this story interesting from a Claude Code perspective is not the medicine itself, but the workflow: a user takes a messy real-world artifact, a DICOM MRI export, and asks Claude to reason over it with code execution, package installs, and an arbitration pass. That is exactly the kind of task where Claude Code can feel magical and unnerving at the same time. The blog post captures both sides very honestly.
![]()
What strikes me is how cleanly this post exposes the real product question around Claude Code: not “can the model answer?” but “can the model hold up inside a workflow that looks like actual work?” The author didn’t just paste in a summary and ask for a vibe check. He gave Claude a DICOM dump, let it reason with code, and then asked it to arbitrate against another interpretation. That is the interesting part. It’s a very Claude Code-shaped experiment.

I think the most important detail here is not that Claude “won” the comparison, but that the whole exercise produced a sharp trust problem. A tool that sounds confident, structured, and methodical can still be wrong on something high-stakes. And when it disagrees with a human clinician, you don’t get clarity for free. You get a second uncertainty. That feels familiar to anyone building with LLMs: the model can produce a polished answer long before you’ve earned the right to believe it.
I also think the post is a good reminder that code execution does not equal clinical validity. Claude Code can install packages, inspect files, and generate a report. That’s powerful. But in medicine, the hard part is not only parsing data; it’s calibrating interpretation, domain assumptions, and the consequences of being wrong. I’d be excited to see more AI-assisted radiology workflows, but I’d be much more excited about systems that quantify uncertainty and show their work in a way a clinician can actually audit. A confident PDF alone is not enough.
What I’d actually do, as a Claude user, is use this kind of setup for exploration and triage, not diagnosis. If I had a DICOM export or a confusing report, I’d want Claude to help me understand the terminology, identify questions to ask, and maybe surface inconsistencies. I would not want it to be the final word. The author’s instinct here is right: this is useful, but it also makes the old human fallback harder to ignore.
The real takeaway is that Claude Code is already capable of doing impressively deep, multi-step analysis on real files. The part that is still missing is trust. And in a domain like MRI interpretation, trust is the whole game.
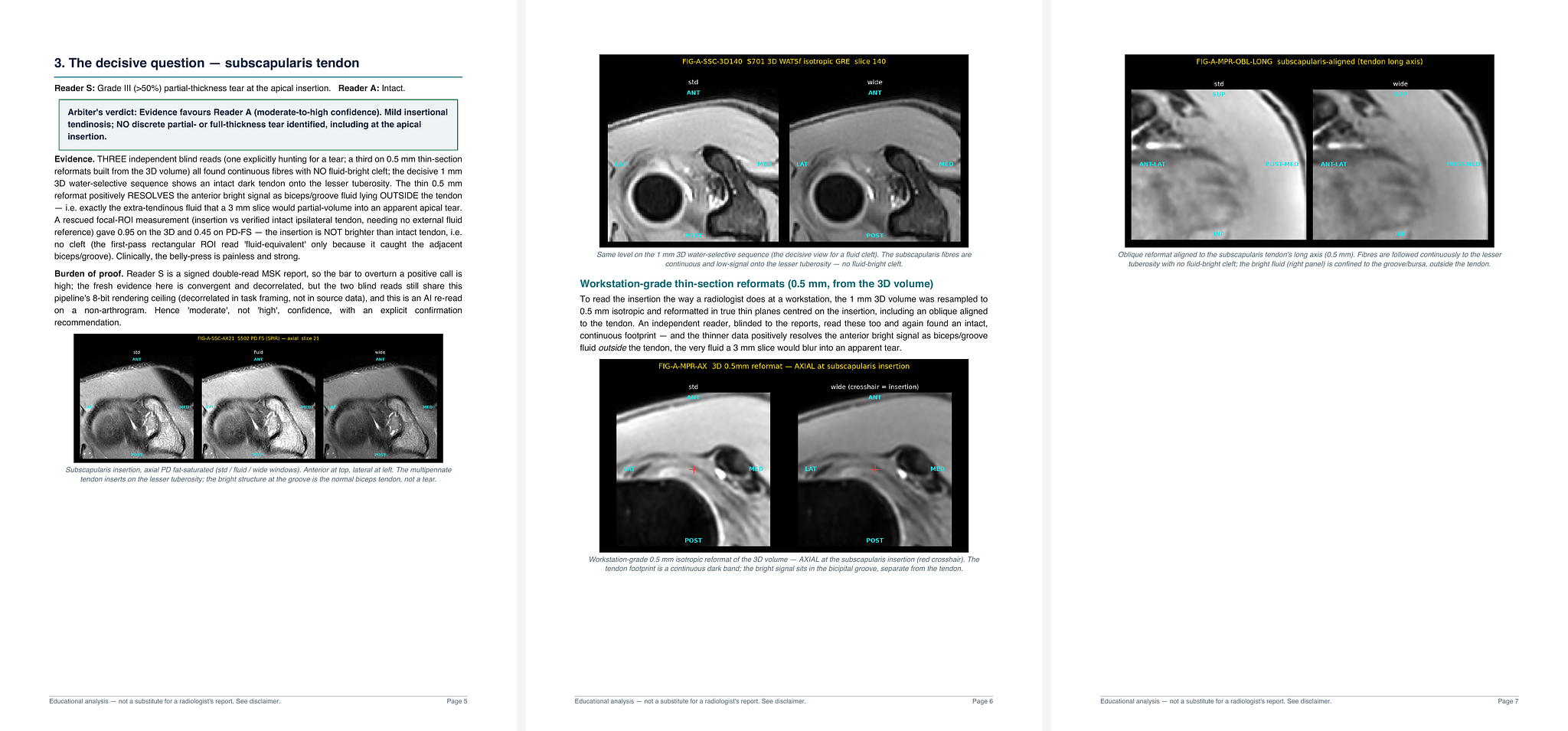
Reference: Using Opus 4.8 to get a second opinion on an MRI and where it leaves me
