If you build with Claude or Claude Code, this Semgrep write-up is the kind of benchmark result that should make you pause. It’s not because open-weight models suddenly “won the future,” but because the gap between a naked prompt and a purpose-built security harness looks bigger than a lot of people probably wanted to admit.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
What strikes me is not “open models beat Claude,” because that’s too shallow a reading. The more interesting part is that Semgrep is basically showing how much security work is a systems problem, not just a raw-model problem. A model with no scaffolding can look surprisingly strong, but a purpose-built harness still wins by a lot. That feels right to me.
![]()
![]()
![]()
![]()
I think this is especially relevant for Claude Code users. A lot of people treat the model as the product, when in practice the workflow around it decides whether you get a clever autocomplete toy or something that can actually reason about a codebase. If you’re doing security work, the endpoint discovery, context selection, and loop design may matter more than whether the model scored a few points higher on some coding leaderboard.


![]()
The GLM 5.2 numbers are still genuinely interesting, though. An open-weight model getting into the same conversation as Claude on a security benchmark is not nothing. For teams with data sensitivity, self-hosting needs, or cost pressure, that’s the part I’d actually test. I’d be curious whether GLM 5.2 holds up on real internal repos the way it does in Semgrep’s benchmark, especially once the tasks get messy and the auth logic stops being tidy.




At the same time, I think people may overread the “beats Claude” headline. This wasn’t a fully equal product-to-product bakeoff. Semgrep is clear that its own multimodal pipeline has extra structure, and the open models got a much thinner harness. That makes the result useful, but also very specific. It tells you where the leverage is, not who has magically solved security agents.


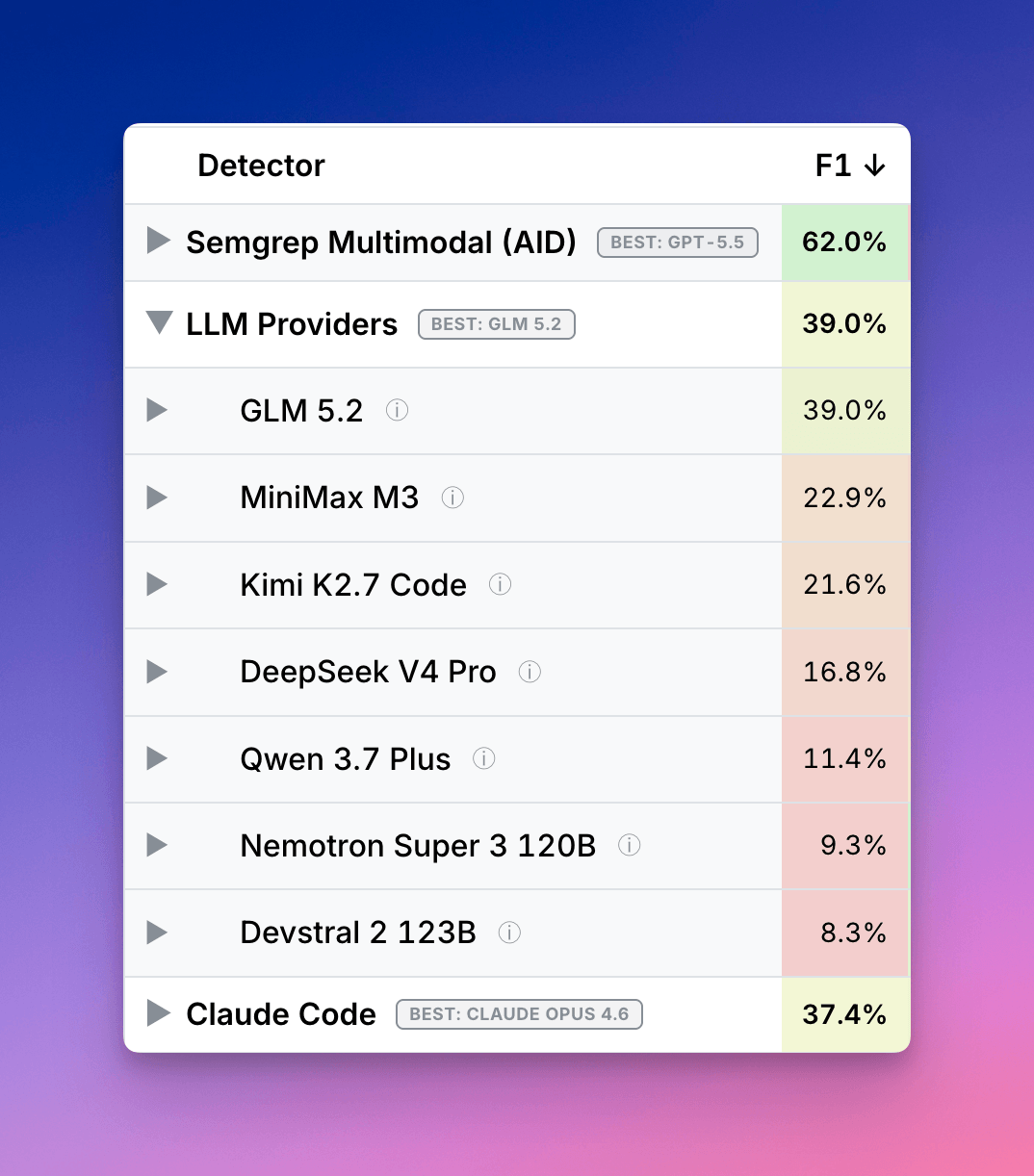

If I were building with Claude Code, I’d take this as a reason to invest more in retrieval, task shaping, and static-analysis hooks rather than obsessing over model swaps alone. The model matters. The wrapper matters more than most people want to believe.
![]()
![]()

.jpg)
![]()
![]()
![]()

Reference: We have Mythos at Home: GLM 5.2 beats Claude in our Cyber Benchmarks
![]()
![]()
![]()
