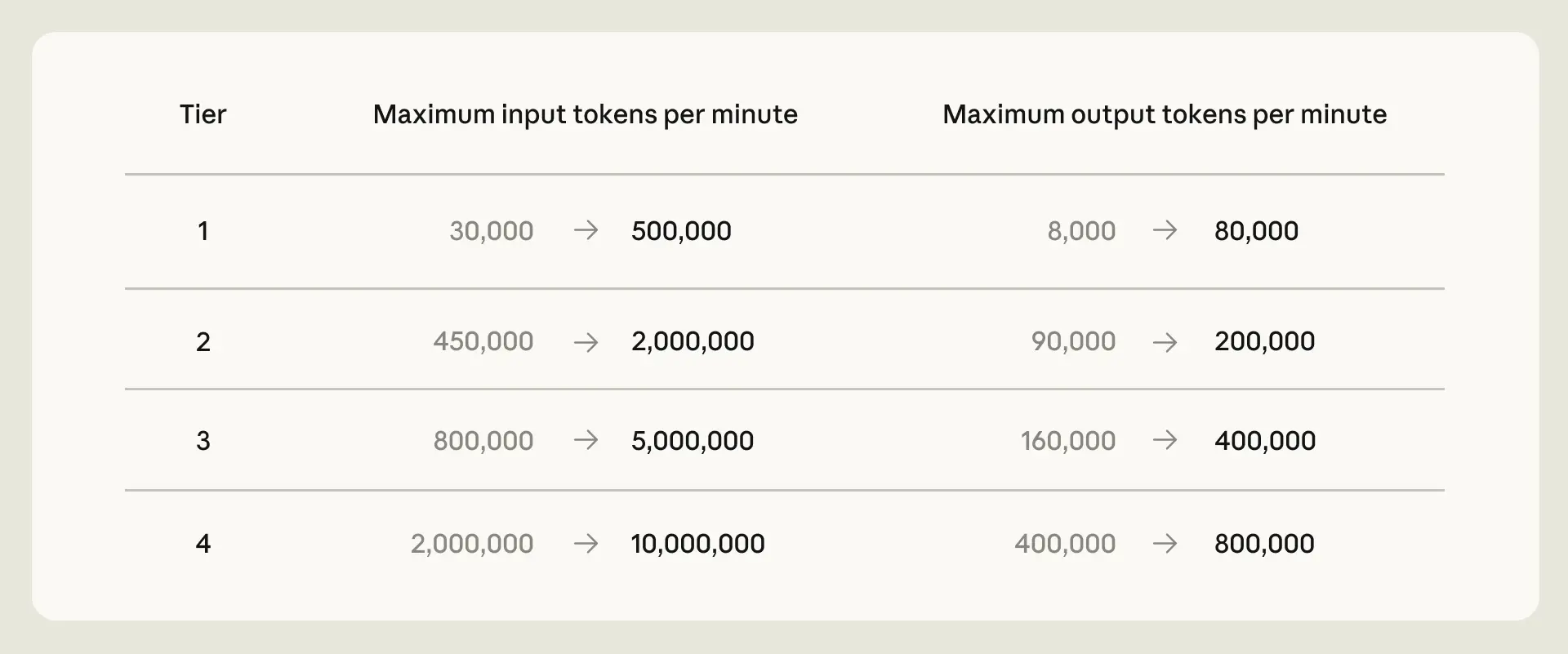
For Claude and Claude Code users, this is one of those announcements that matters less as marketing and more as infrastructure. Anthropic is clearly saying: if you’ve been hitting limits, especially on Opus-heavy API workflows or Claude Code usage, there’s more headroom now — and a lot more may be coming as new compute comes online.

What strikes me is how much of this reads like the practical side of scaling an LLM product that’s actually being used hard. Doubling Claude Code limits and removing peak-hour throttling for Pro/Max users is the kind of change developers will notice immediately, unlike vague “capacity improvements” language that sounds nice but changes nothing in your day.
I think the compute story is the bigger signal, though. SpaceX is an eye-catching partner, but the real story is Anthropic’s attempt to secure enough infrastructure from as many angles as possible — AWS, Google, Microsoft, NVIDIA, Fluidstack, and now SpaceX. That tells me the bottleneck for frontier model products is still very much raw compute, not just model quality or product polish.
The orbital AI compute idea feels more speculative to me. It’s interesting, and maybe even strategically sensible long term, but right now it reads like a moonshot in the literal sense. I’d be curious whether this is a serious near-term plan or more of an ambition designed to signal just how far Anthropic is thinking ahead.
As a Claude Code user, what I’d actually do is test whether the new limits materially change my workflow: longer agentic sessions, fewer interruptions during peak times, and less need to ration Opus calls in API-heavy builds. If those improvements hold up, that’s far more valuable than the headline number of GPUs.
The bottom line: this is mostly an infrastructure story, but it has immediate consequences for power users. More compute should mean fewer limits, and for Claude developers, that’s the part that matters most.
Reference: Higher usage limits for Claude and a compute deal with SpaceX
