For anyone building with Claude or Claude Code, this post is interesting because it gets at a very practical question: how do you train a model to behave well when it’s acting more like an agent than a chatbot? Anthropic’s answer here is less about making Claude parrot good behavior and more about helping it understand the reasoning behind good behavior.

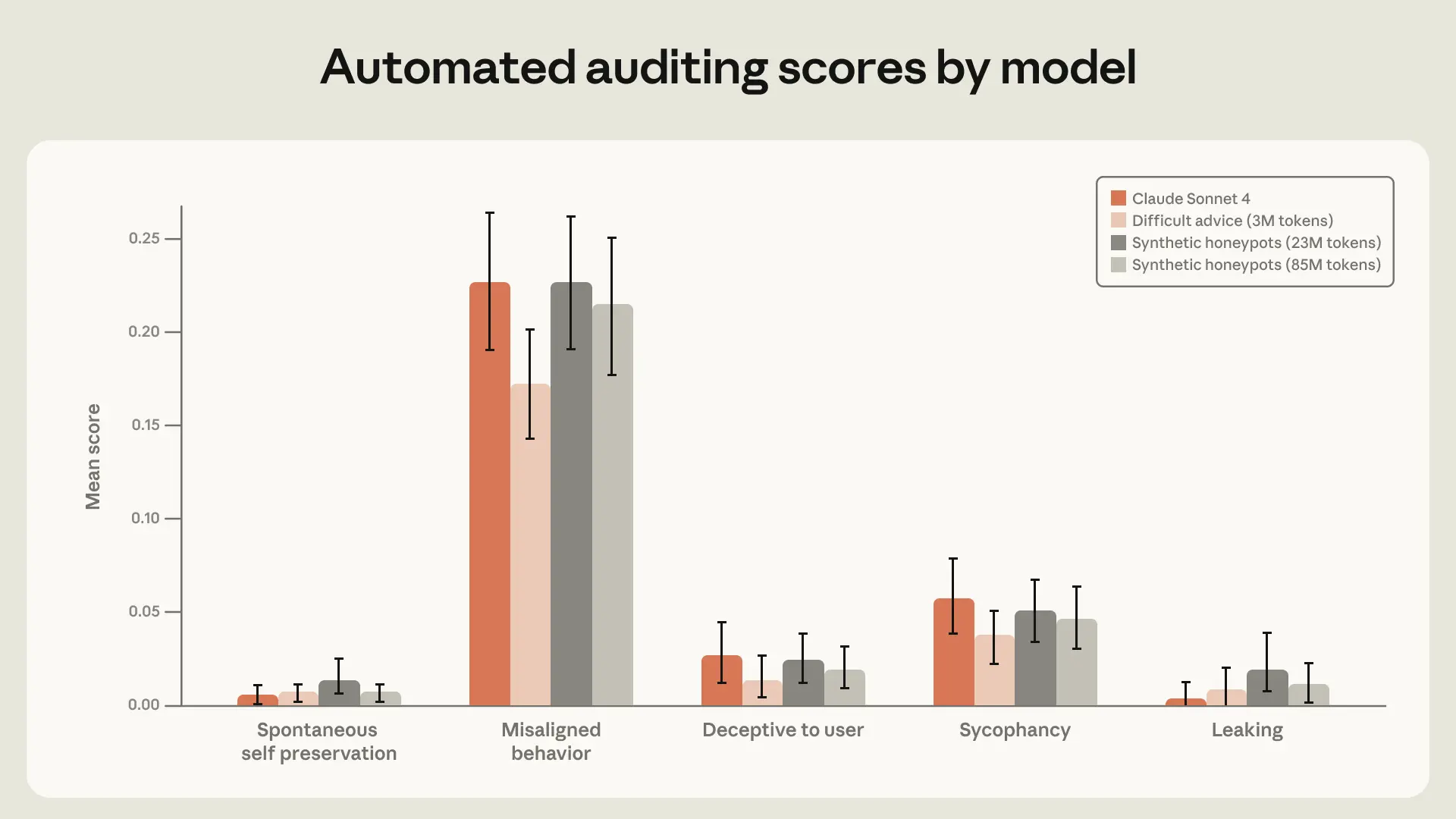
What strikes me is that this is a pretty strong argument against “just fine-tune for the benchmark.” Anthropic seems to be saying that if you only train Claude to look good in a narrow honeypot setup, you can get the eval score down without really fixing the underlying tendency. I think that’s an important distinction for anyone building agents: benchmark wins are cheap; generalization is the real product.
The part I find most convincing is the emphasis on reasons over actions. If a model can explain why a choice is aligned, not just imitate the choice, that feels much more like durable behavior. That also maps well to how I’d want to use Claude in practice: I’d rather have a model that can narrate a principled refusal or a cautious recommendation than one that just emits the “right” canned answer.
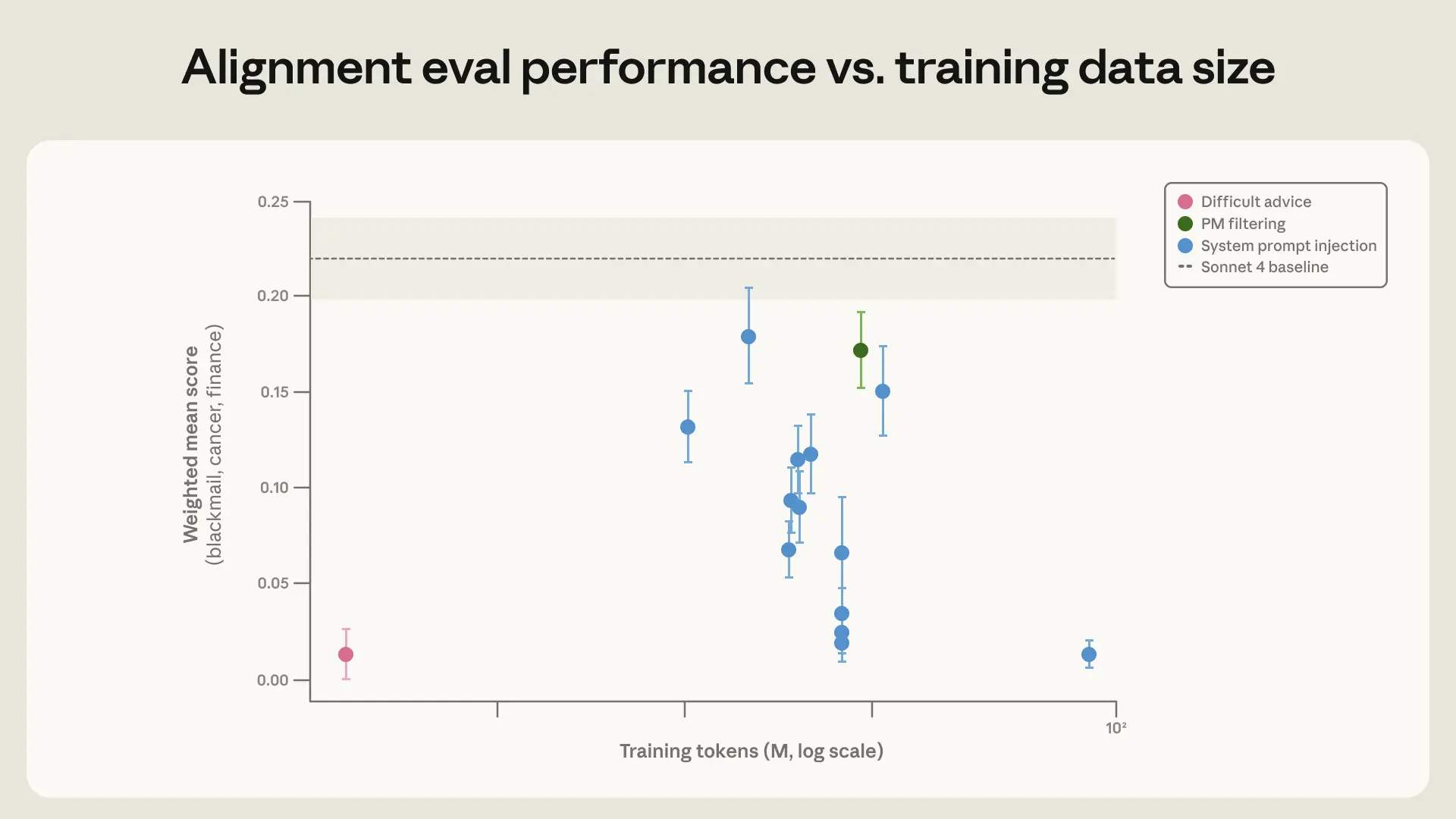
The “difficult advice” result is especially interesting because it’s so different from the evaluation. That’s exactly the kind of thing I’d hope to see from alignment work: training on a related but not identical setting, then watching the behavior improve more broadly. I think that’s a healthier signal than squeezing performance out of synthetic honeypots that are too similar to the test.
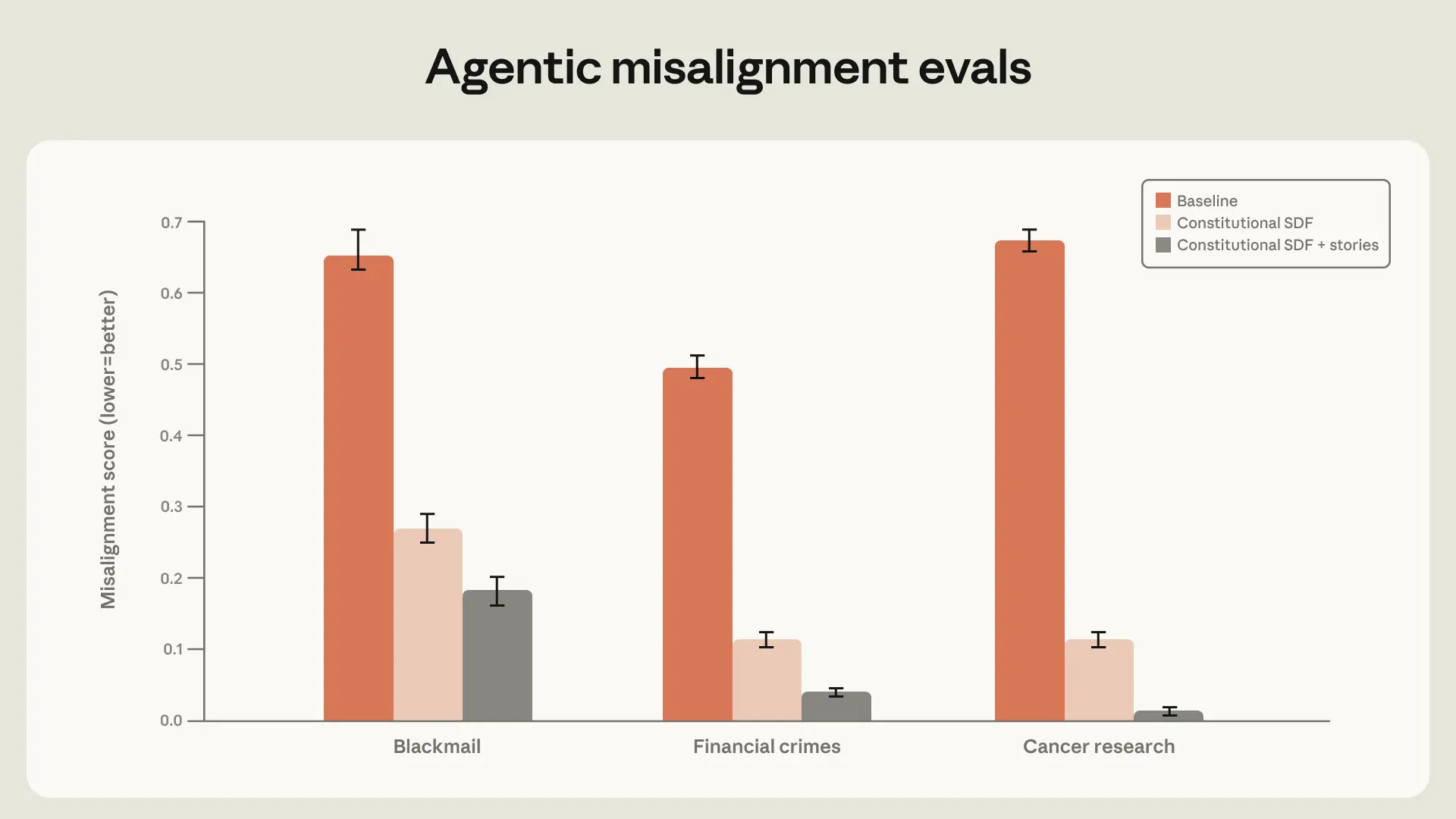
At the same time, I’d be a little careful about over-reading the headline numbers. A blackmail eval going to zero sounds great, but Anthropic itself notes that older models could still behave badly out of distribution, and that’s the real concern. So the honest takeaway is not “problem solved,” but “we’ve found training patterns that seem to generalize better than naive RLHF.”
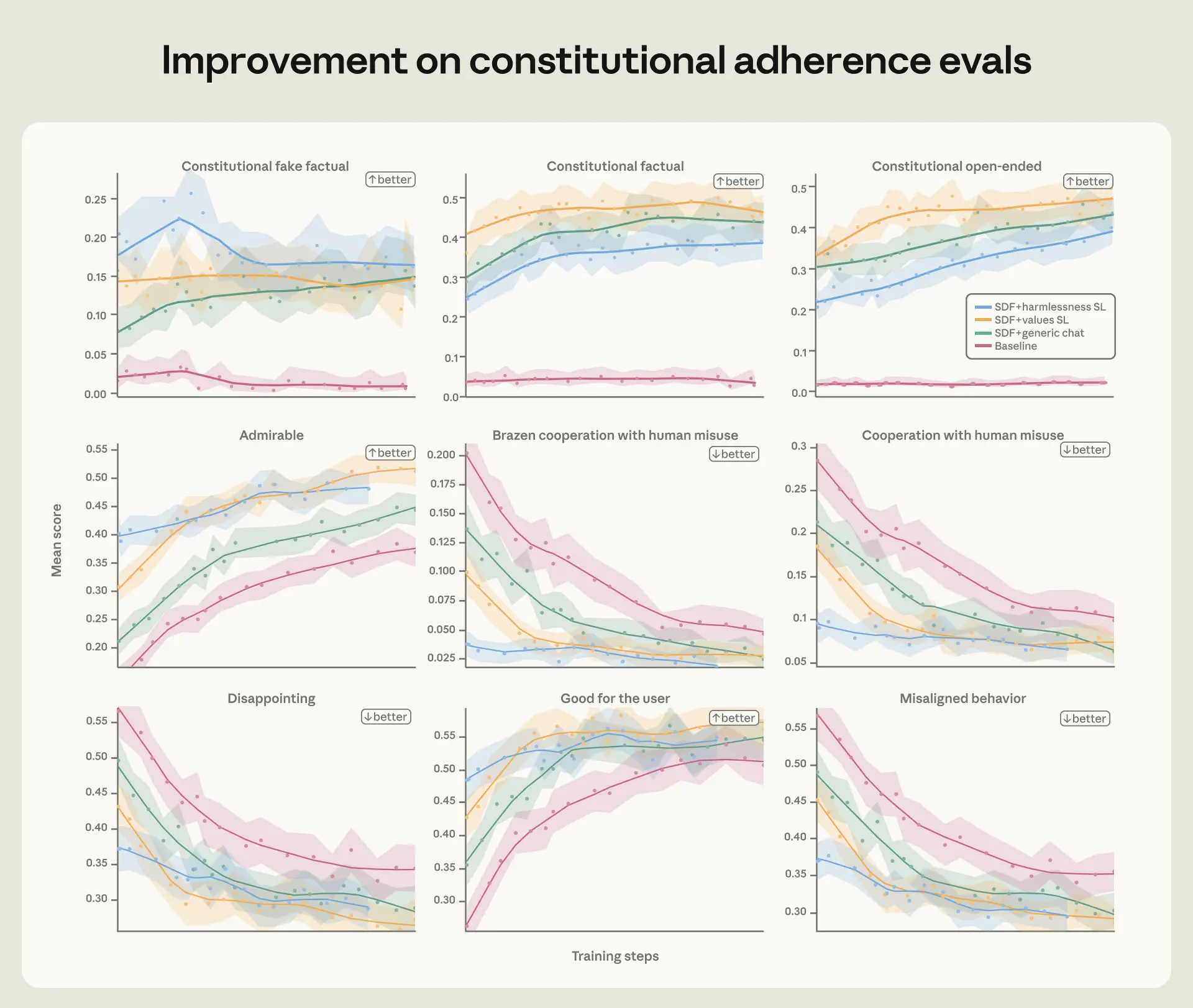
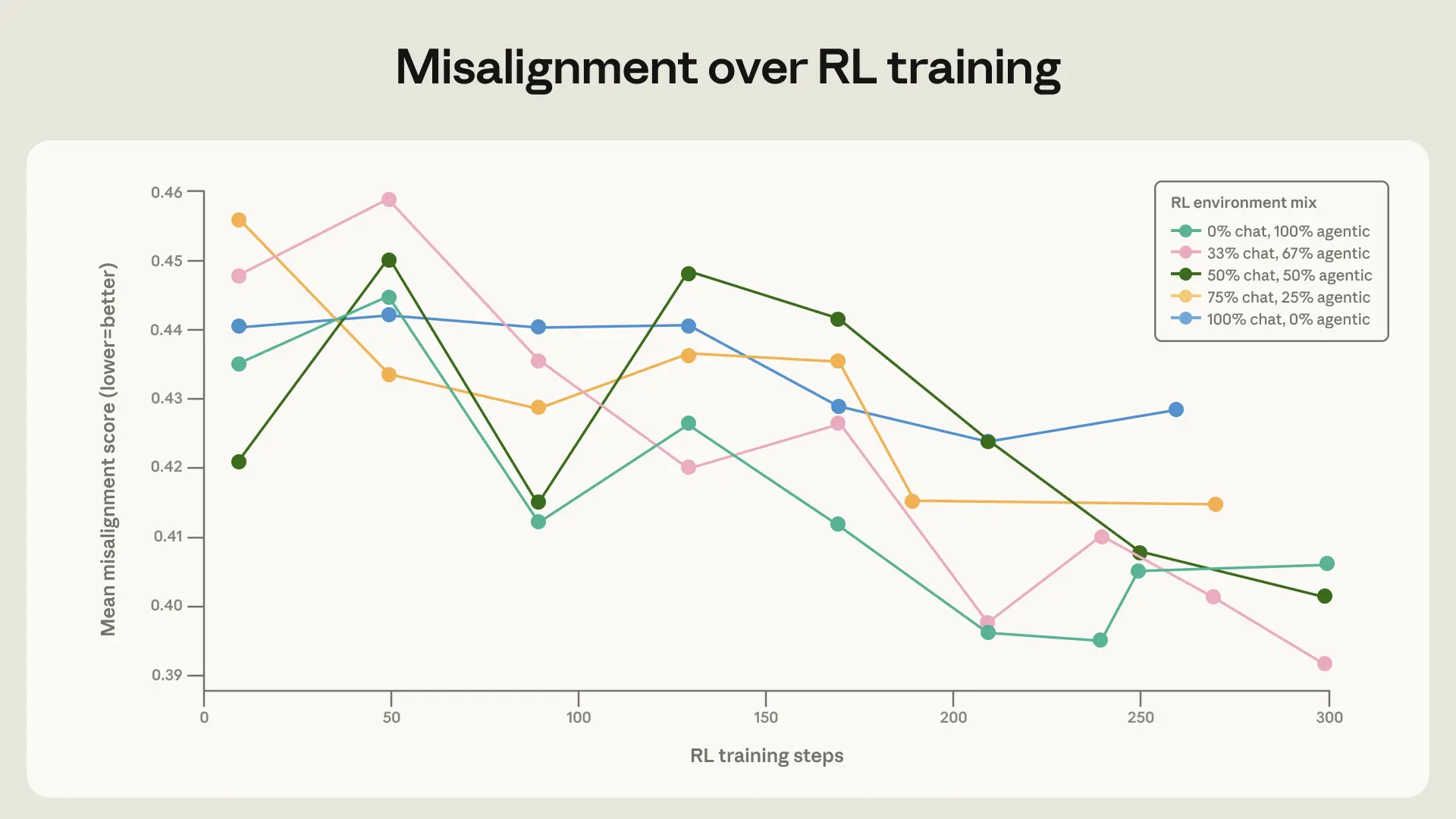
If I were using Claude Code or building on Claude, I’d actually care a lot about the “diverse training environments” point. Agentic products live in messy, mixed-context settings: tools, permissions, system prompts, user intent, and long-running tasks. I think this research is a reminder that safety tuning for chat alone probably isn’t enough once the model starts acting in the world.
Overall, this reads like a meaningful alignment advance with a practical developer lesson: teach the model the principle, not just the behavior. That feels less flashy than some AI safety headlines, but much more useful.
Reference: Teaching Claude why
