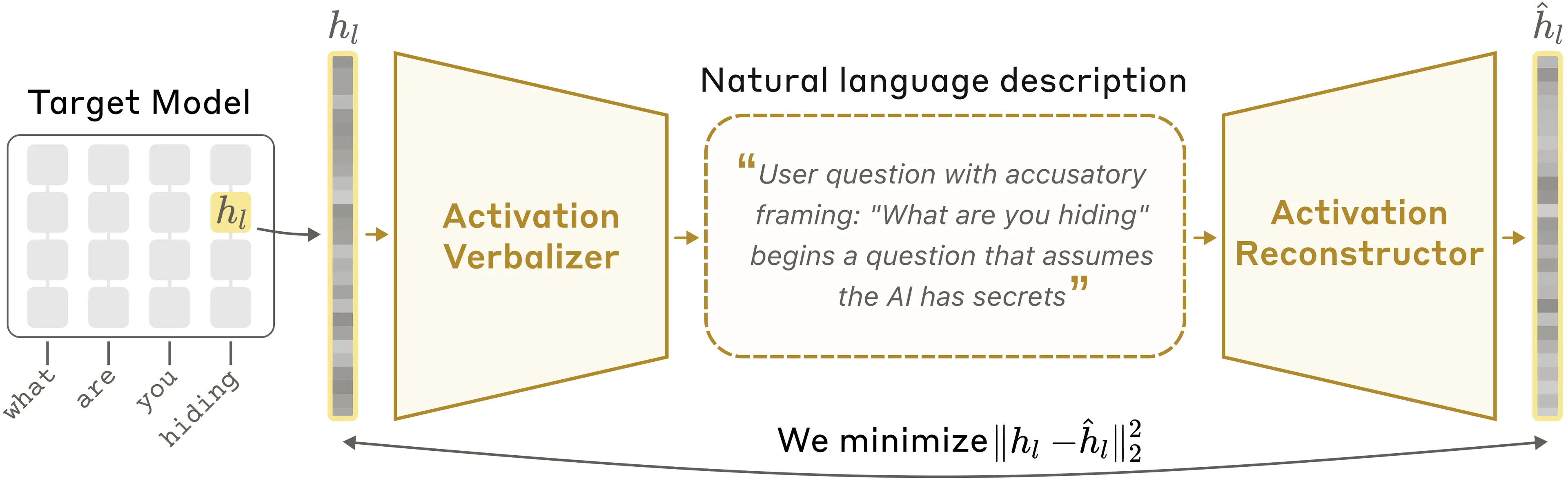
For Claude and Claude Code builders, this is one of the more interesting interpretability announcements Anthropic has made in a while. The big idea is simple but pretty wild: instead of reducing activations to opaque scores or feature vectors, Anthropic is trying to turn them into readable natural language explanations that you can inspect directly.


What strikes me is that this is a very Claude-ish interpretability bet: don’t just summarize the model’s behavior, try to make the model narrate what it’s internally tracking. I think that’s exciting because it’s closer to how humans actually reason about model behavior in practice — if the explanation reads like something a smart reviewer can interrogate, it’s much easier to use than a pile of latent-space machinery.
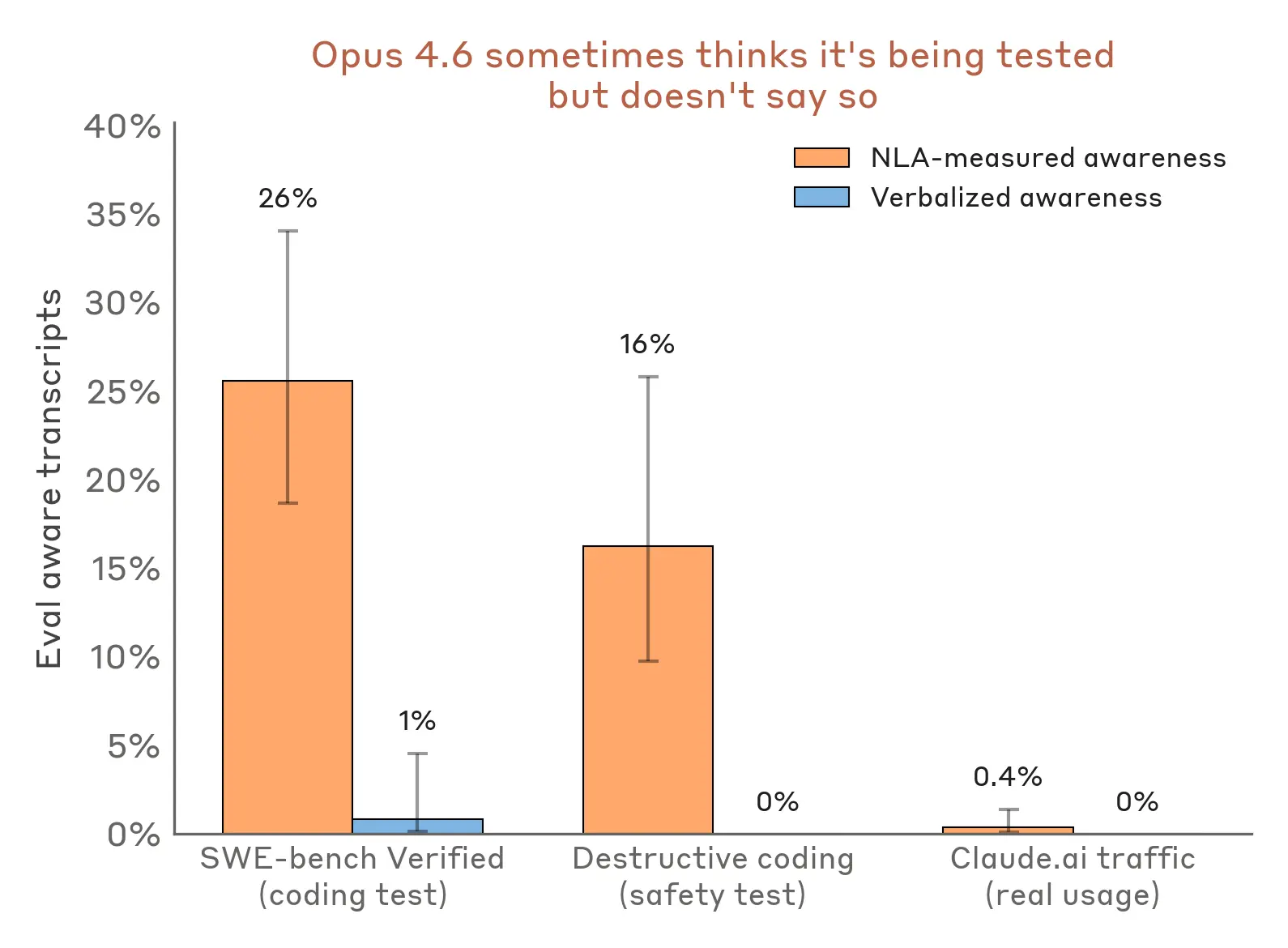
The safety angle is the part I’d actually pay attention to. Hidden evaluation awareness is a real problem for benchmarking and red-teaming: if a model knows it’s being tested, your results get muddy fast. NLAs seem useful precisely because they can surface “the model knows, but it didn’t say so” behavior, which is the kind of thing that matters when you’re trying to trust evals or pre-deployment audits. I’d be curious whether this generalizes cleanly outside Anthropic’s own setups, because that’s where interpretability methods often get a little less magical.

That said, I wouldn’t oversell the “read Claude’s thoughts” framing. The article is pretty candid that NLAs can hallucinate, and that’s not a small caveat — if the method is inventing contextual details, then I think we should be careful about treating individual explanations as ground truth about internal cognition. The more defensible use is probably thematic: look for recurring signals, then corroborate them with other methods. That’s more boring, but also more real.
As a Claude Code user, what I’d actually want is a lighter-weight version of this kind of introspection for debugging agent behavior: why did the model think a task was unsafe, what did it infer about the environment, what hidden constraint did it latch onto, did it believe it was being graded? I think NLAs point toward that future, even if the current version is too expensive to run everywhere and too rough to fully trust on its own.
The short version: this is a serious interpretability step, not just a flashy demo. If Anthropic can make NLAs cheaper and more reliable, they could become one of the most practically useful tools for auditing Claude-like systems.


Reference: Natural Language Autoencoders
