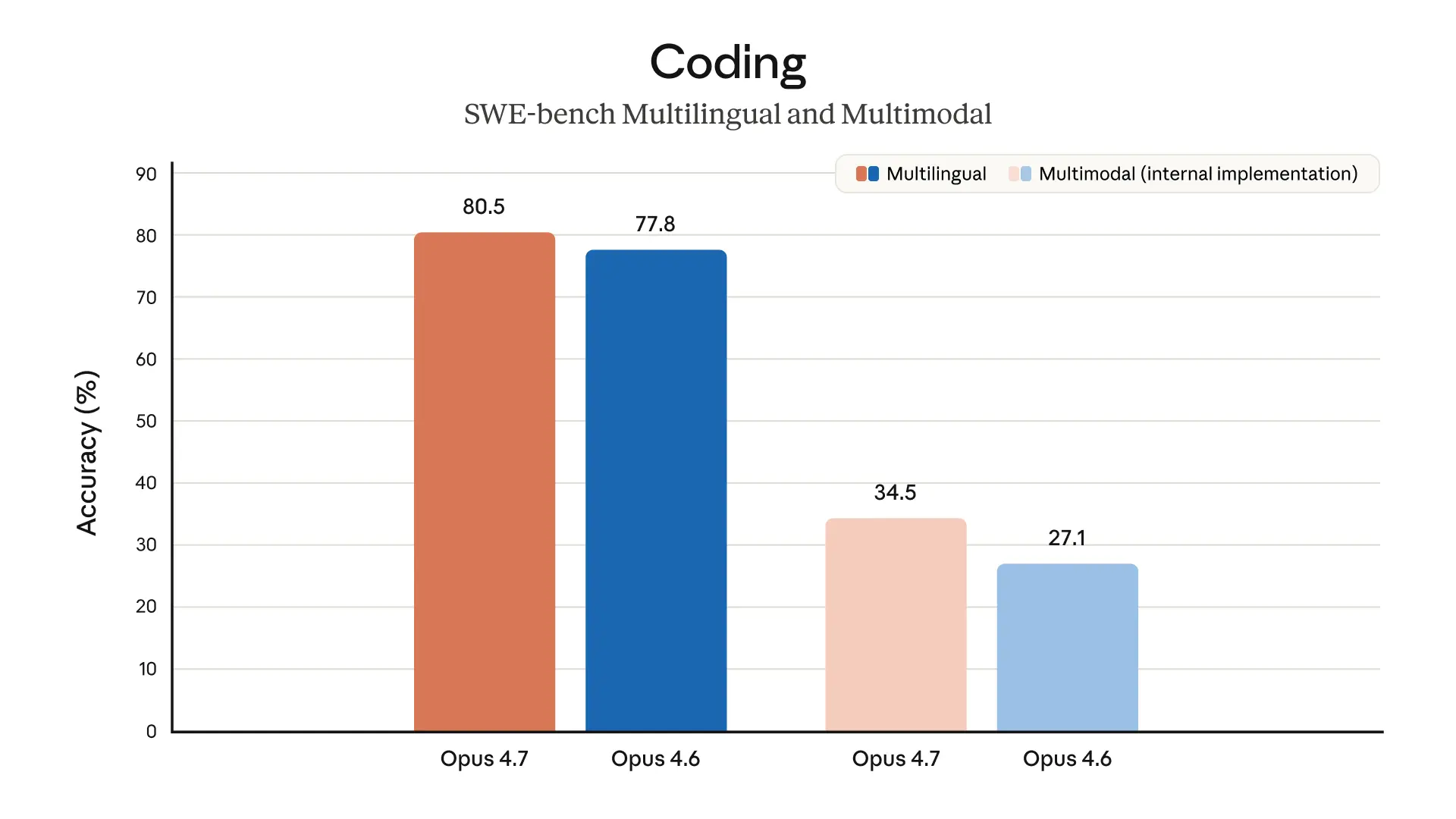
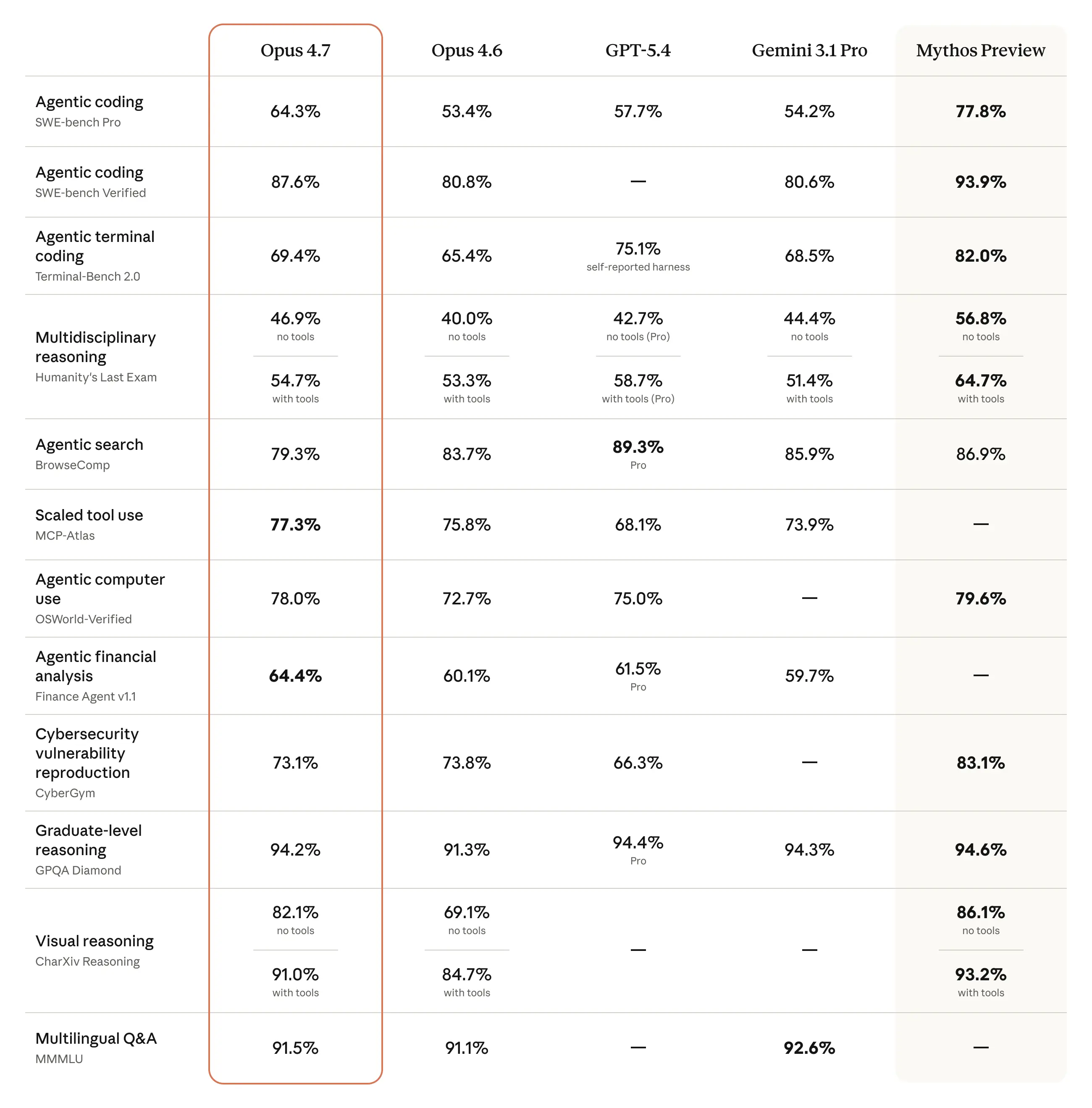
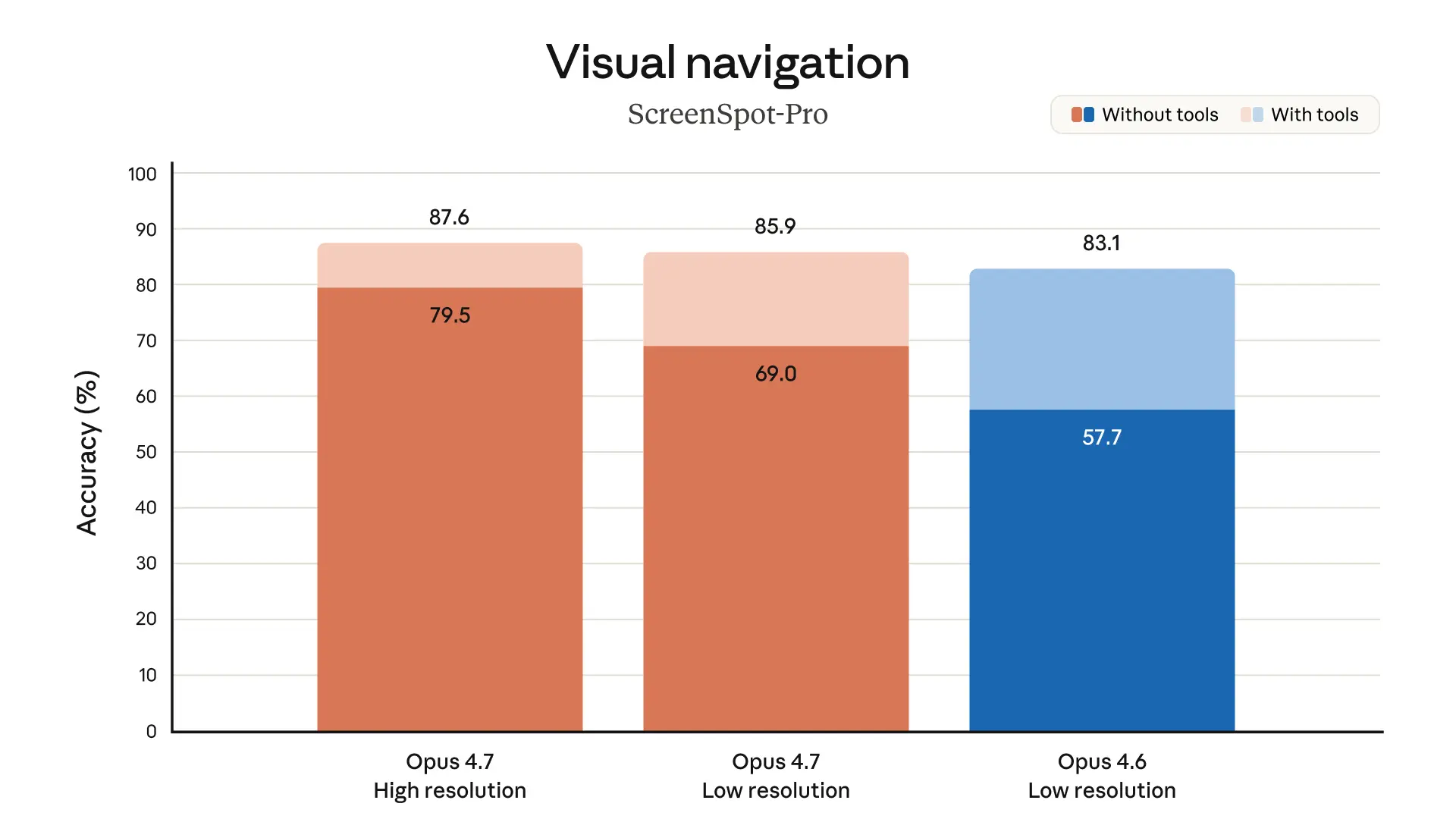
For Claude and Claude Code users, Claude Opus 4.7 is interesting less as a flashy consumer release and more as a signal about where Anthropic thinks the frontier is moving: longer-horizon coding, better self-checking, stronger multimodal work, and tighter control around high-risk cybersecurity use. The headline here is not just “better benchmark scores,” but “more trustworthy on messy, multi-step work,” which is the part developers actually feel.












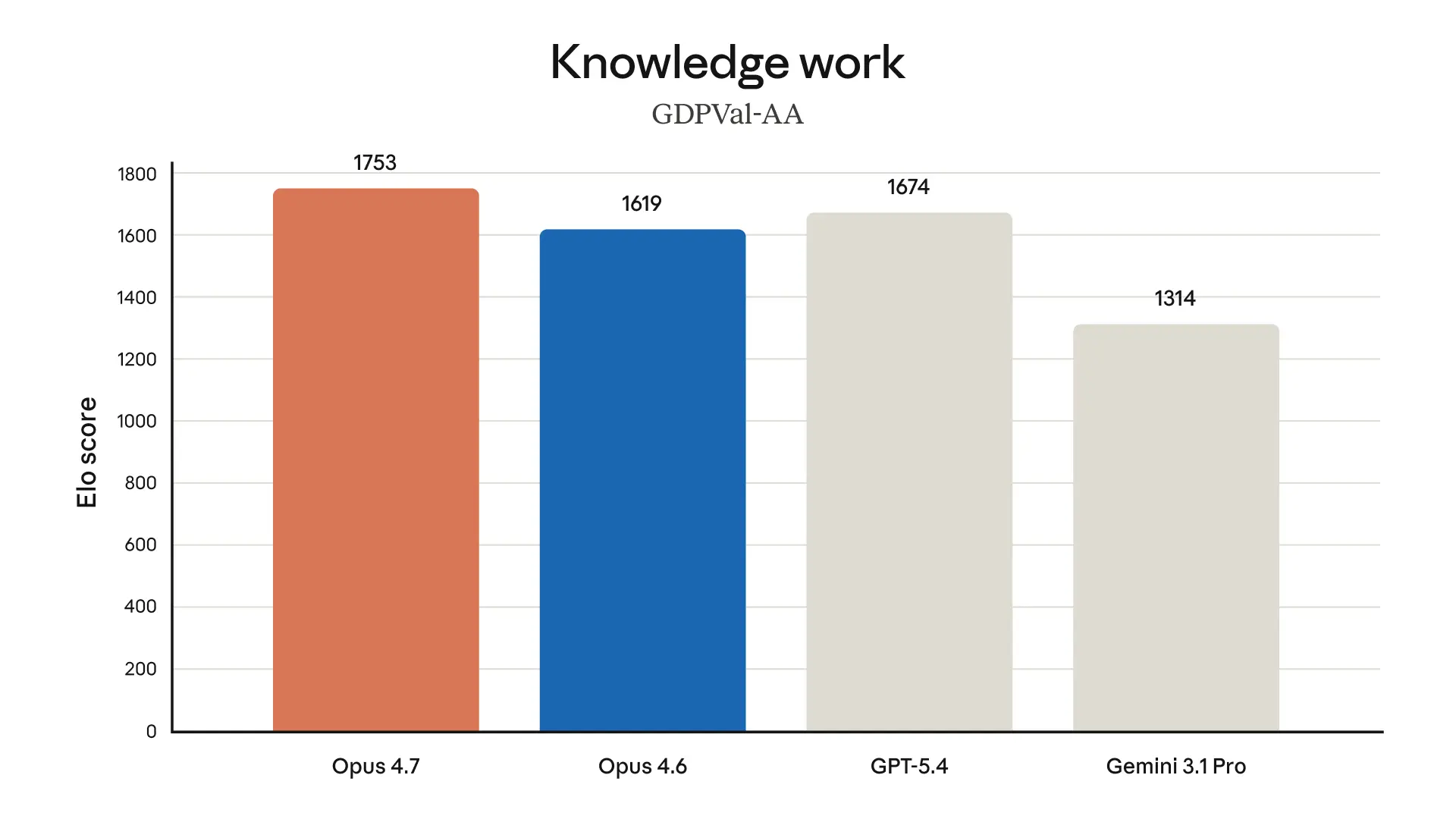
What strikes me is that Anthropic is leaning hard into the kind of improvements that matter most for real developer workflows: fewer half-finished runs, better tool use, better calibration, and more willingness to say “I don’t know” when the data is missing. That’s boring in the best possible way. If you use Claude Code, or build on top of Claude for agentic tasks, this is exactly the category of upgrade that can save time without needing a totally new product shape.



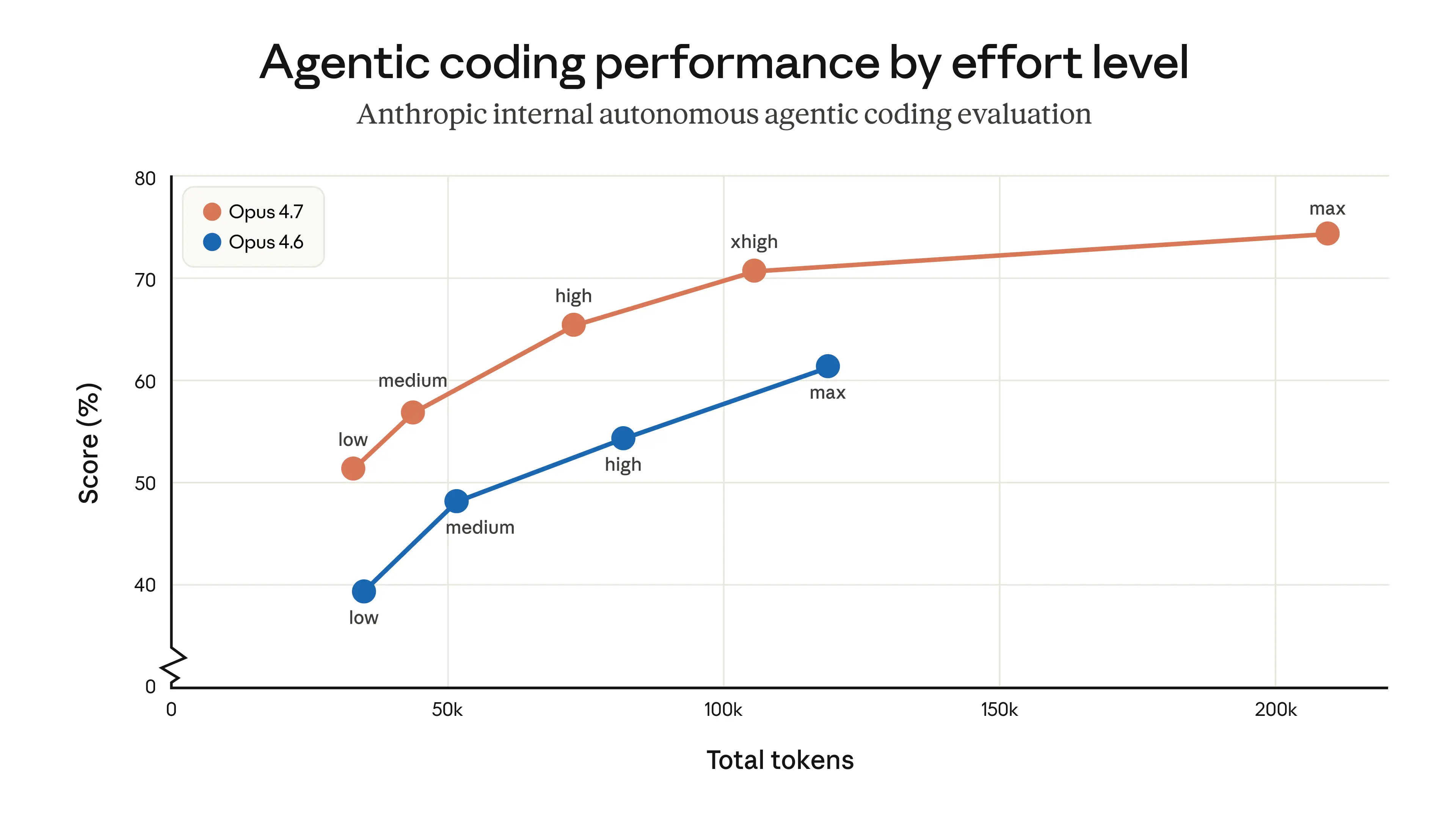
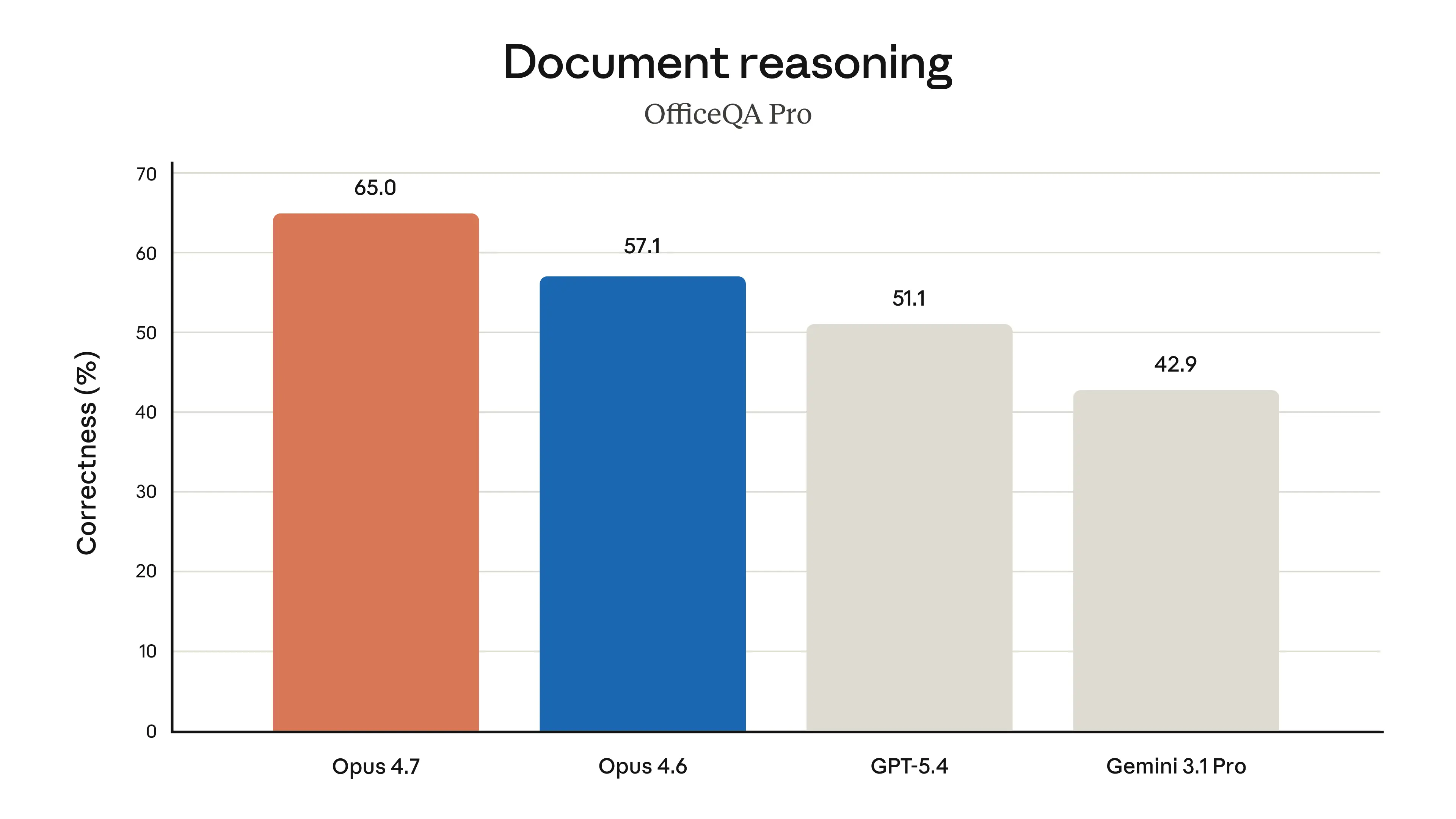
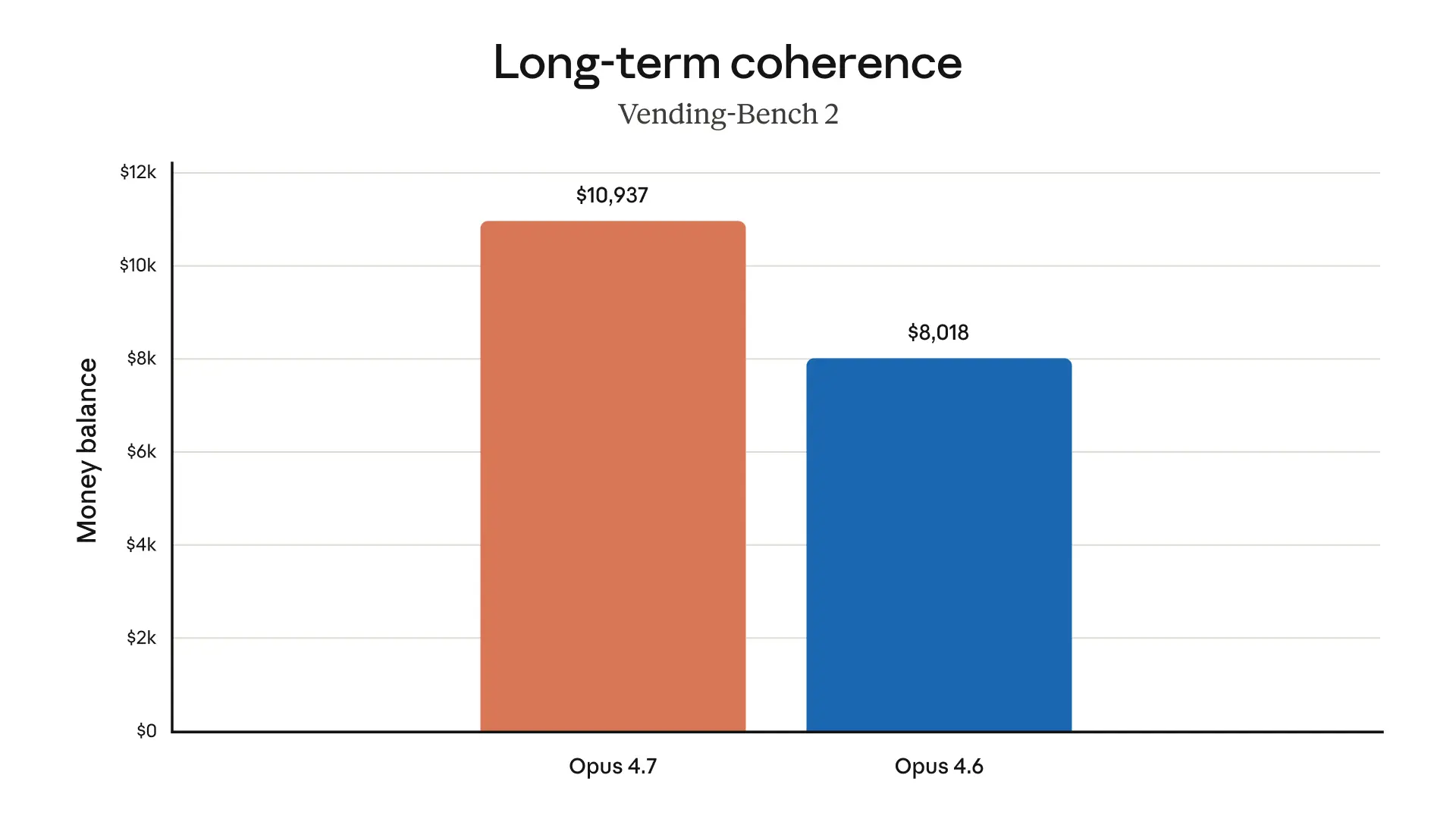
I think the most interesting part is the repeated emphasis on long-running work. Lots of models can look impressive in a quick demo; fewer can stay coherent through CI/CD, async workflows, bug hunts, and multi-step investigations. If Anthropic’s testers are right, Opus 4.7 is less about “wow, it wrote a nicer paragraph” and more about “it didn’t fall apart halfway through the job.” That’s the kind of thing developers remember.



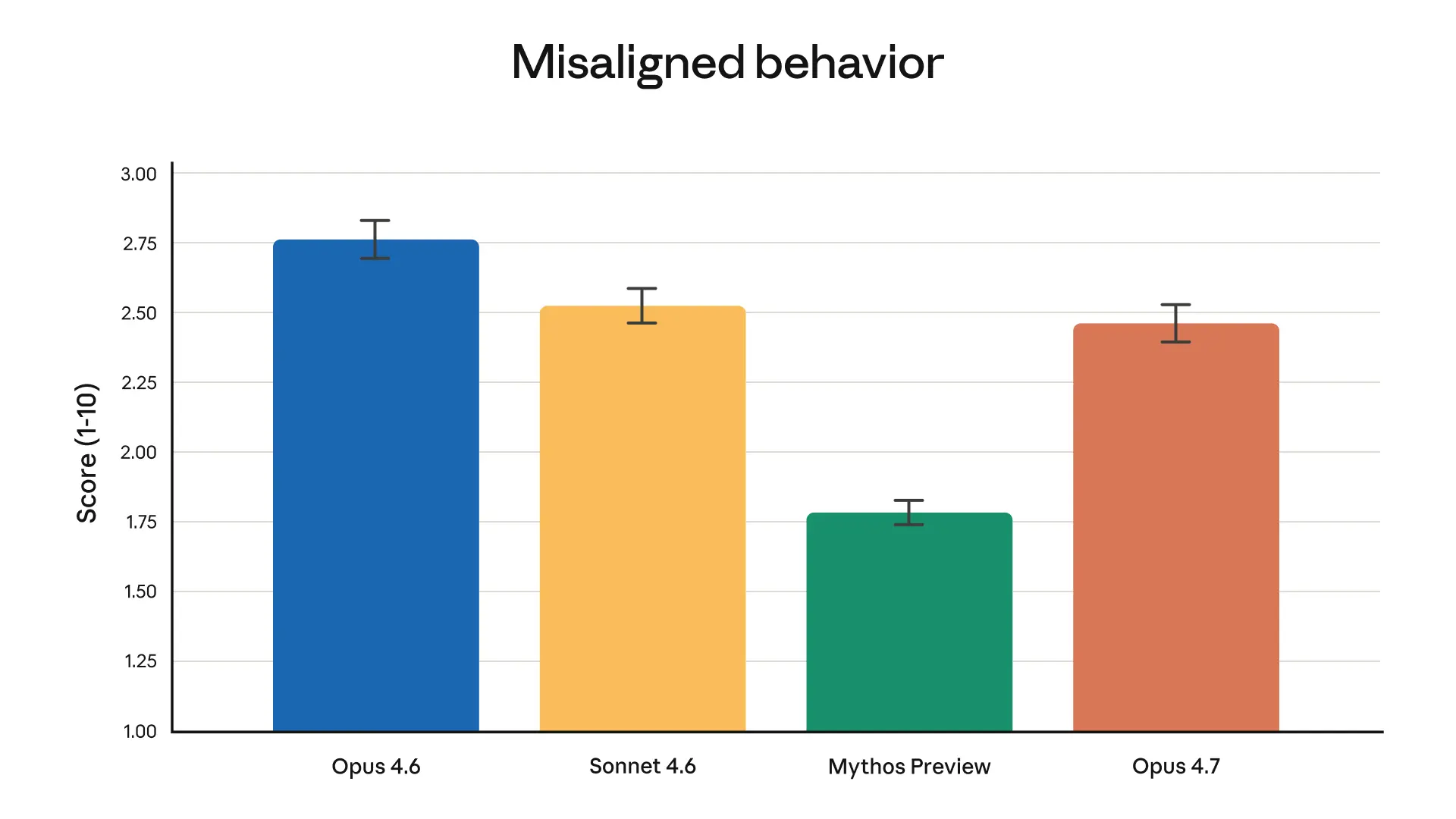
The cyber angle is also notable. Anthropic is clearly trying to thread a needle: push frontier capability forward, but stage the rollout of more capable cyber-related behavior behind safeguards and verification. I think that’s sensible, even if it’s a bit unglamorous. It also hints that future Claude releases may be shaped as much by safety deployment strategy as by raw model quality.




What feels a little overhyped, at least from the article itself, is the parade of customer praise. Some of it sounds genuinely compelling, but this is still vendor-selected feedback. I’d be curious whether the gains hold up on my own codebase, especially on the weird edge cases where agents tend to spin, over-edit, or over-explain. The strongest claims here are the ones about reliability and tool discipline, not the “best in the world” marketing language.



If I were using Claude Code today, I’d try Opus 4.7 first on the hardest work: big refactors, flaky tests, code review on nasty PRs, and any task where the model has to keep state across many steps. That’s where a model with better self-verification and fewer tool mistakes could really matter.



Bottom line: Opus 4.7 looks like a pragmatic, high-leverage upgrade for developers, not a flashy reset. If Anthropic’s claims hold in practice, it could be the kind of model that makes agents feel less like demos and more like coworkers.

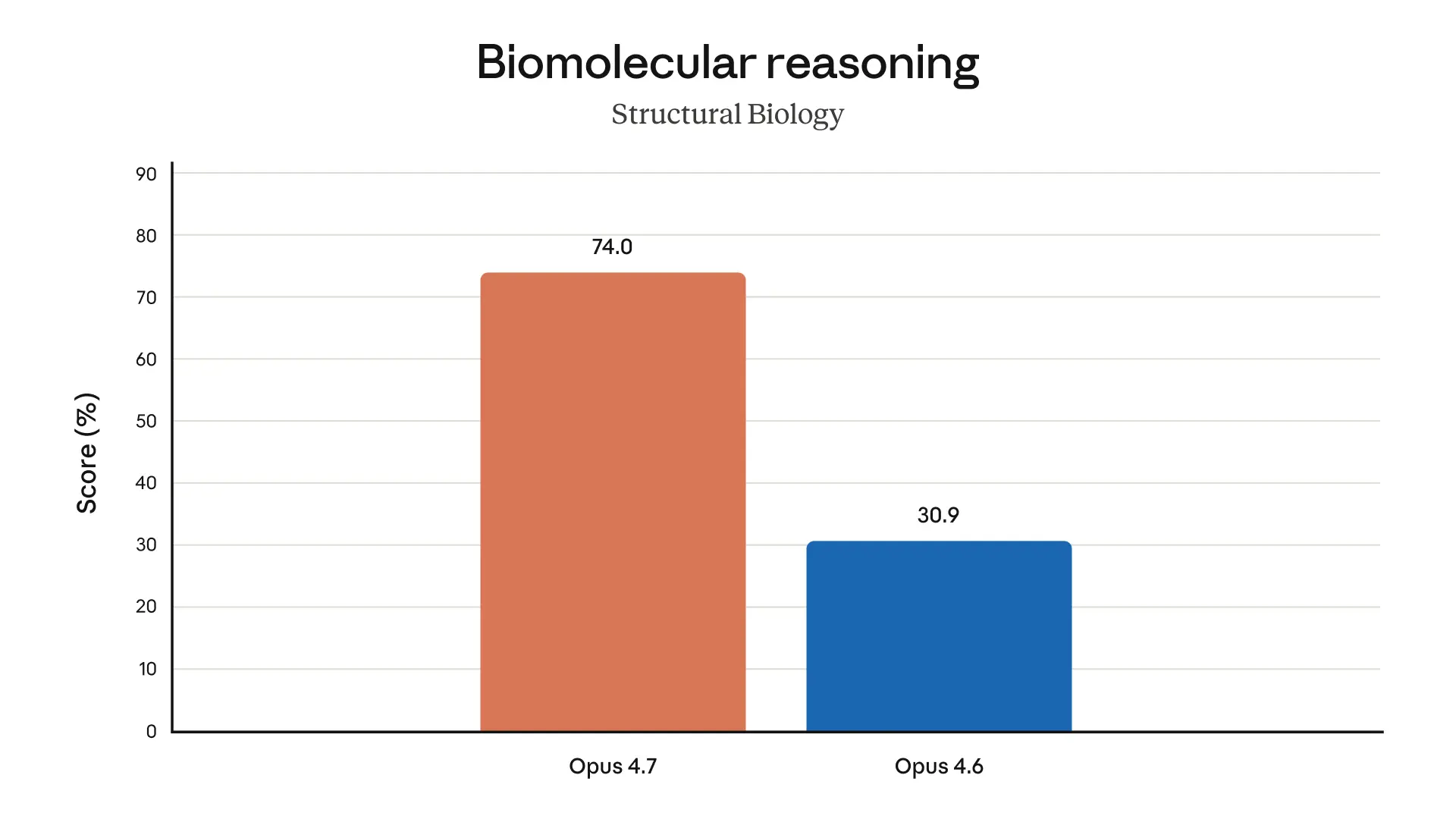
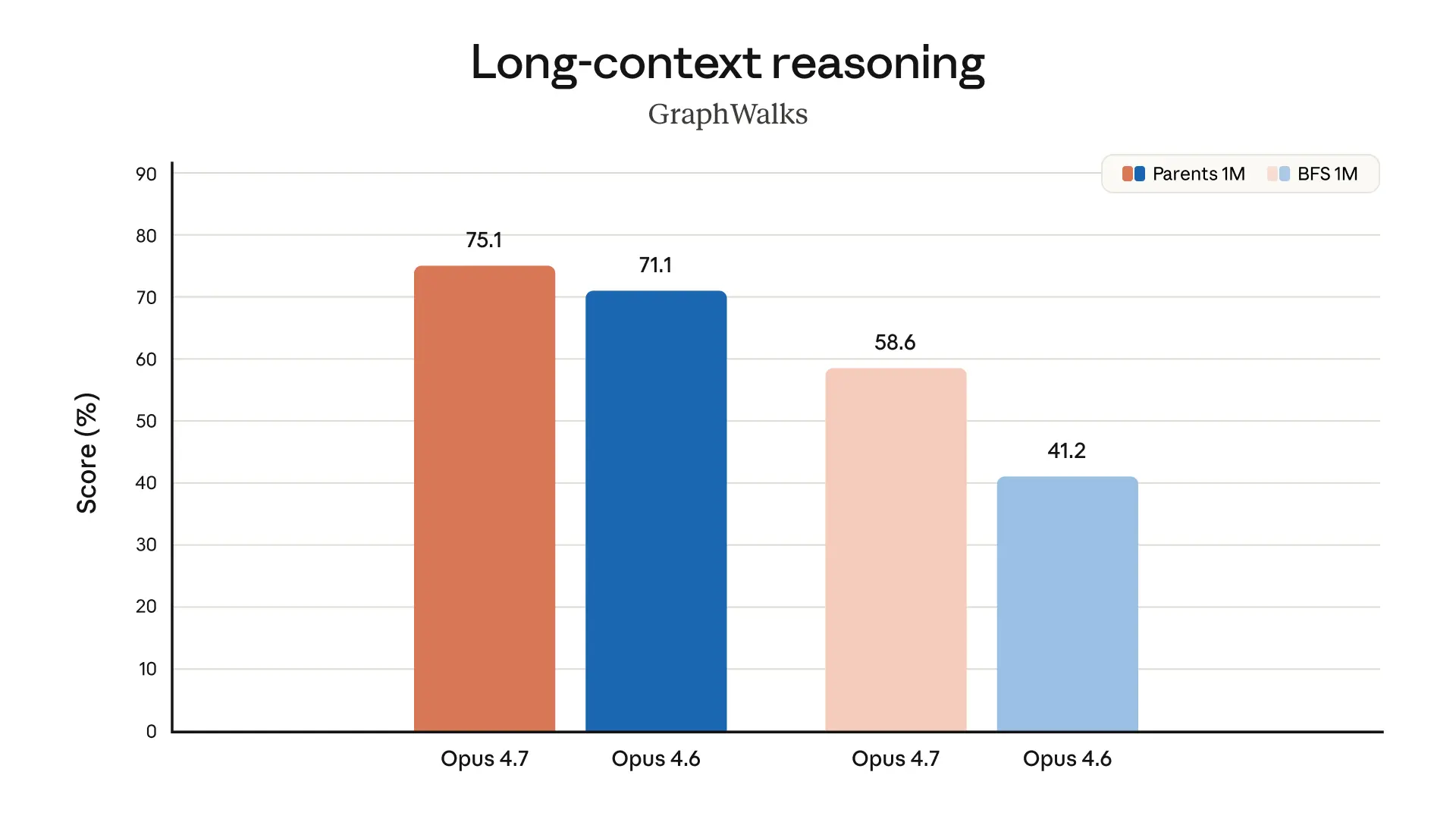
Reference: Introducing Claude Opus 4.7