Reference: Introducing Claude Opus 4.7

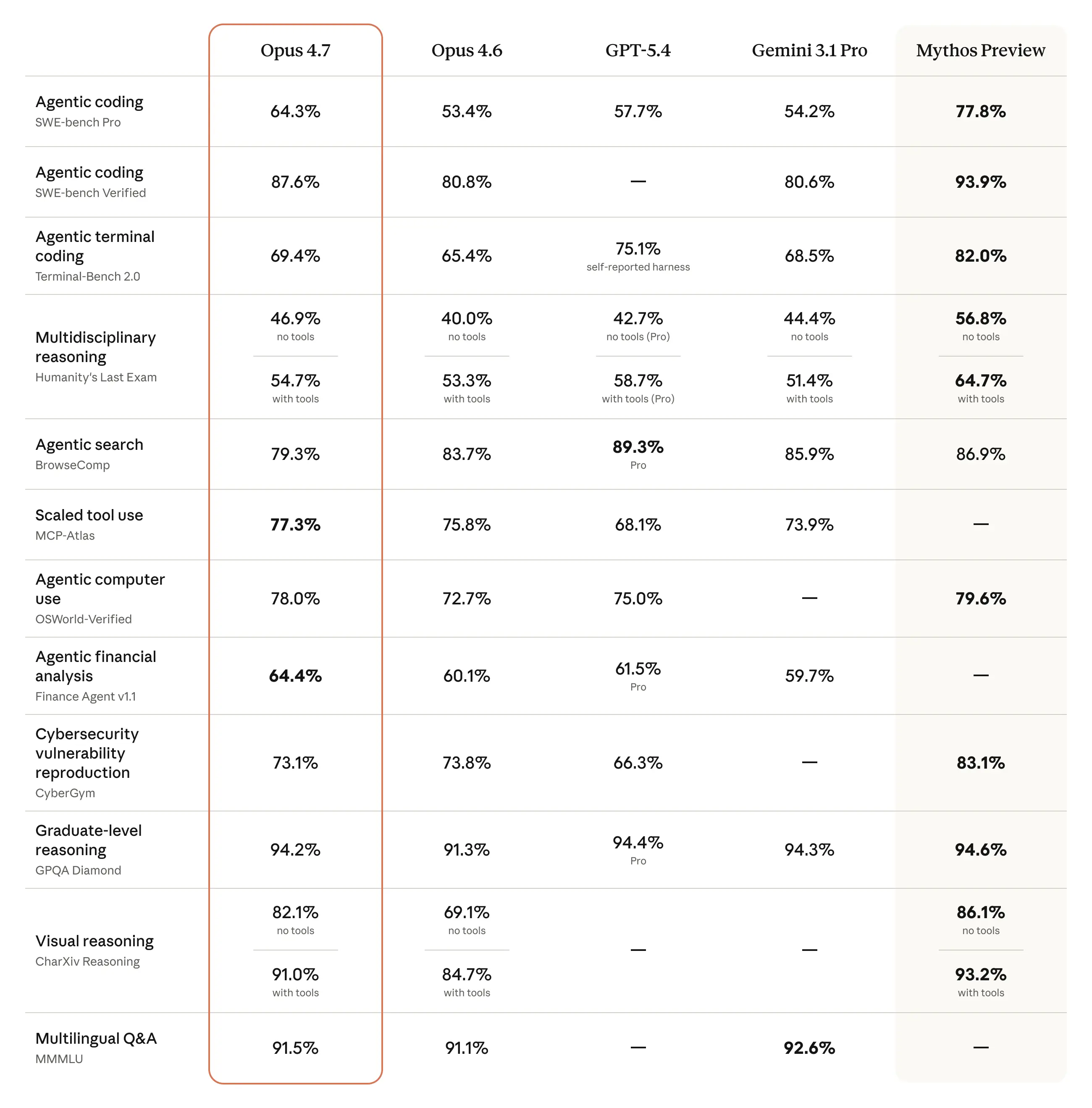





For Claude and Claude Code users, this is the kind of release that matters more than a flashy benchmark chart: Anthropic is claiming a real step up in the places developers feel pain most—long-running, multi-step, high-stakes coding tasks. What stands out to me is that the pitch is less “new model, bigger number” and more “this one is steadier, more self-checking, and less likely to fall apart halfway through.”














What strikes me is that Anthropic is leaning hard into a very practical message: this is the model you give to harder coding jobs when you want fewer interruptions, fewer hallucinated shortcuts, and less babysitting. That’s the stuff developers actually pay for, so I think the positioning makes sense.




The most interesting part, honestly, is not the raw capability claims but the recurring theme of reliability: self-verification, better instruction following, better handling of missing data, fewer tool-call mistakes, and better behavior in async workflows. If those improvements hold up, they matter more than a small jump in benchmark scores because they change how much trust you can place in the model during real work. I’d be curious whether this translates into noticeably fewer “close enough” failures in Claude Code-style workflows, especially on long tasks where models usually drift.




I also think the cyber story is important, even if it’s not the headline most developers will care about first. Anthropic is clearly trying to test a safer path for more capable cybersecurity-related models, and Opus 4.7 becomes the proving ground. That feels thoughtful, though perhaps also like a reminder that frontier coding models and frontier cyber risk are now tightly linked whether vendors like it or not.
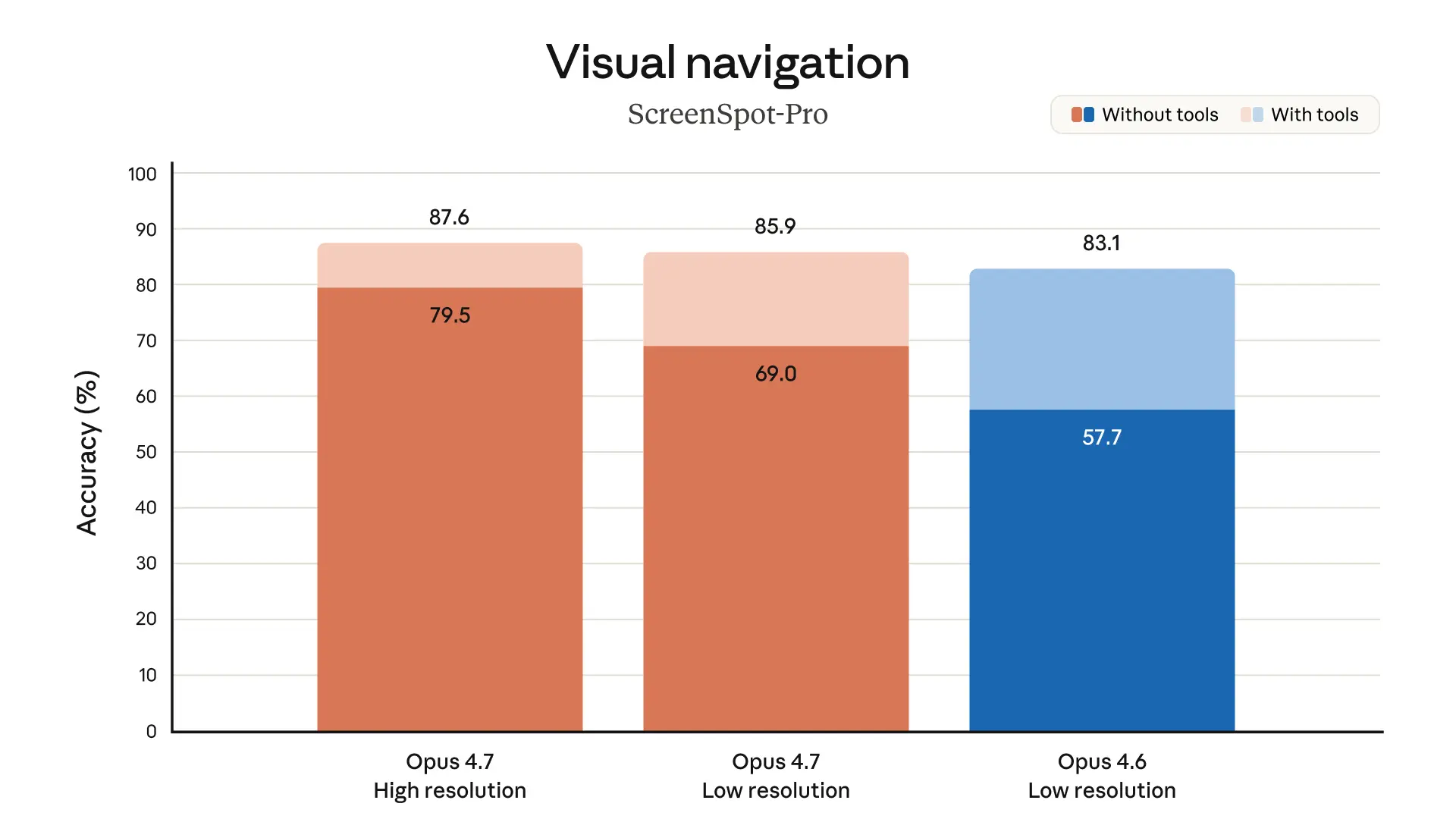
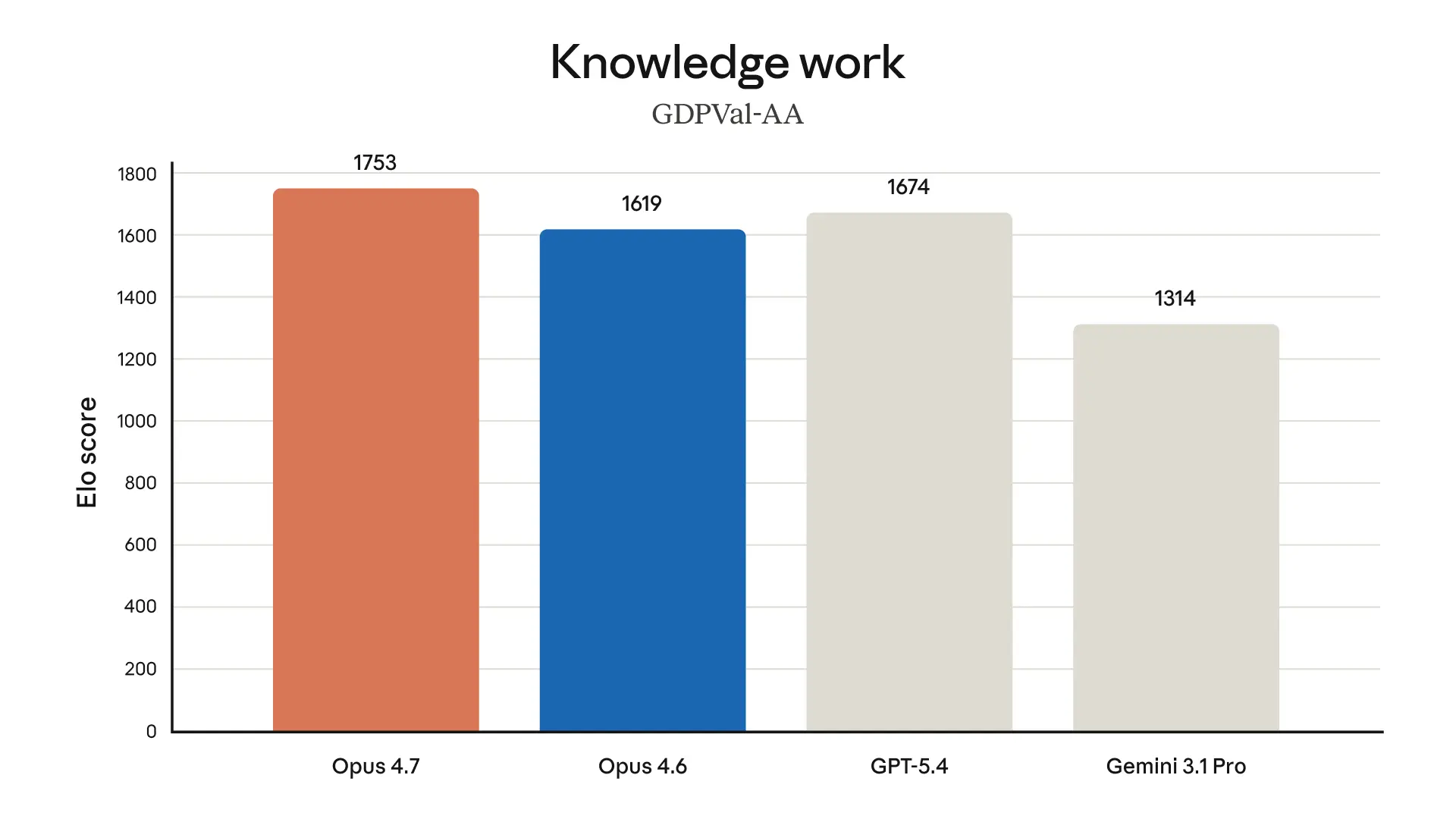

What feels a little overhyped, as always, is the parade of customer blurbs. Some of them are useful because they point to concrete wins—fewer tool errors, better bug finding, stronger multimodal reading—but they’re still vendor-approved testimonials. I trust them as directional signals, not as proof.
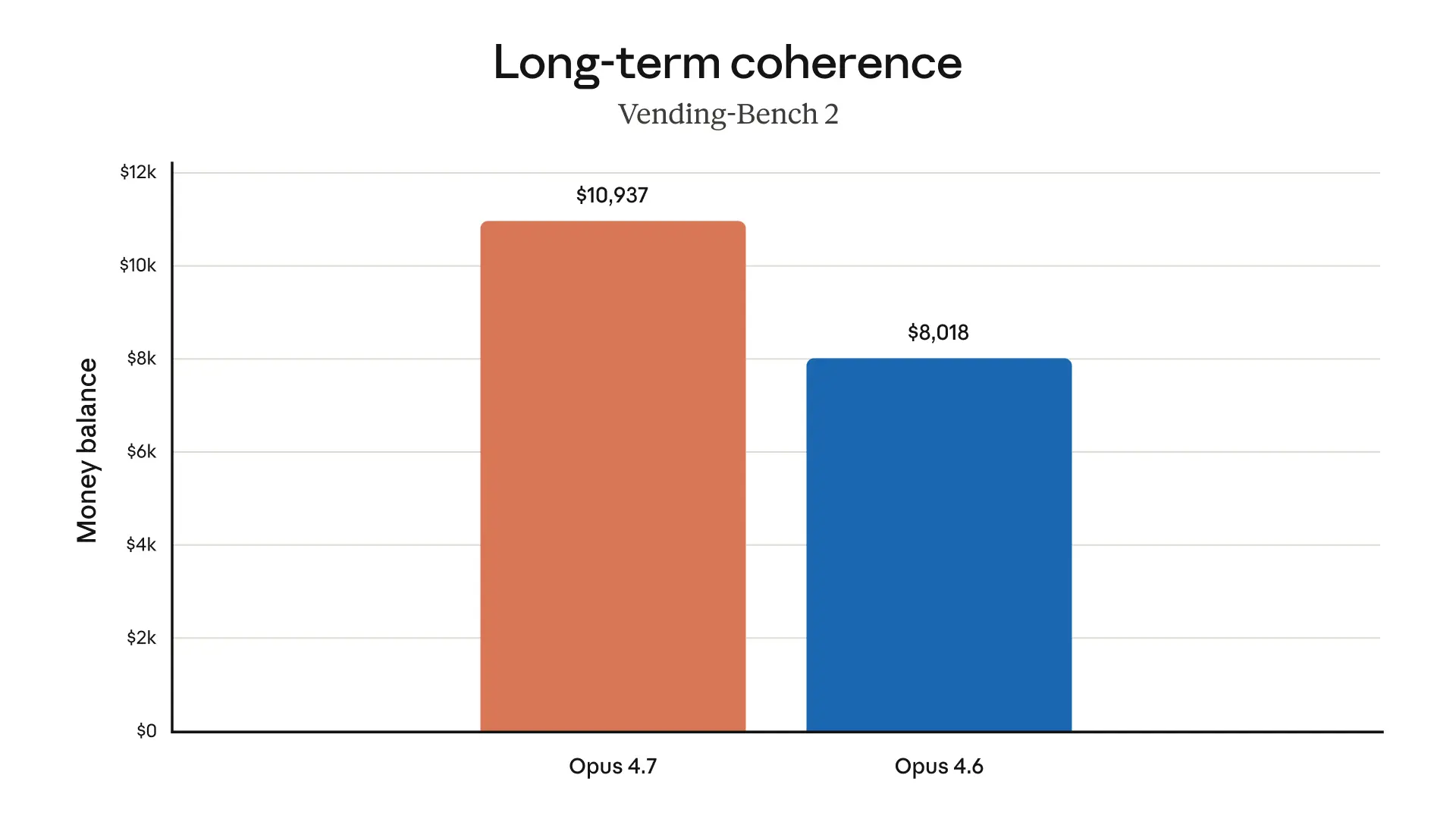
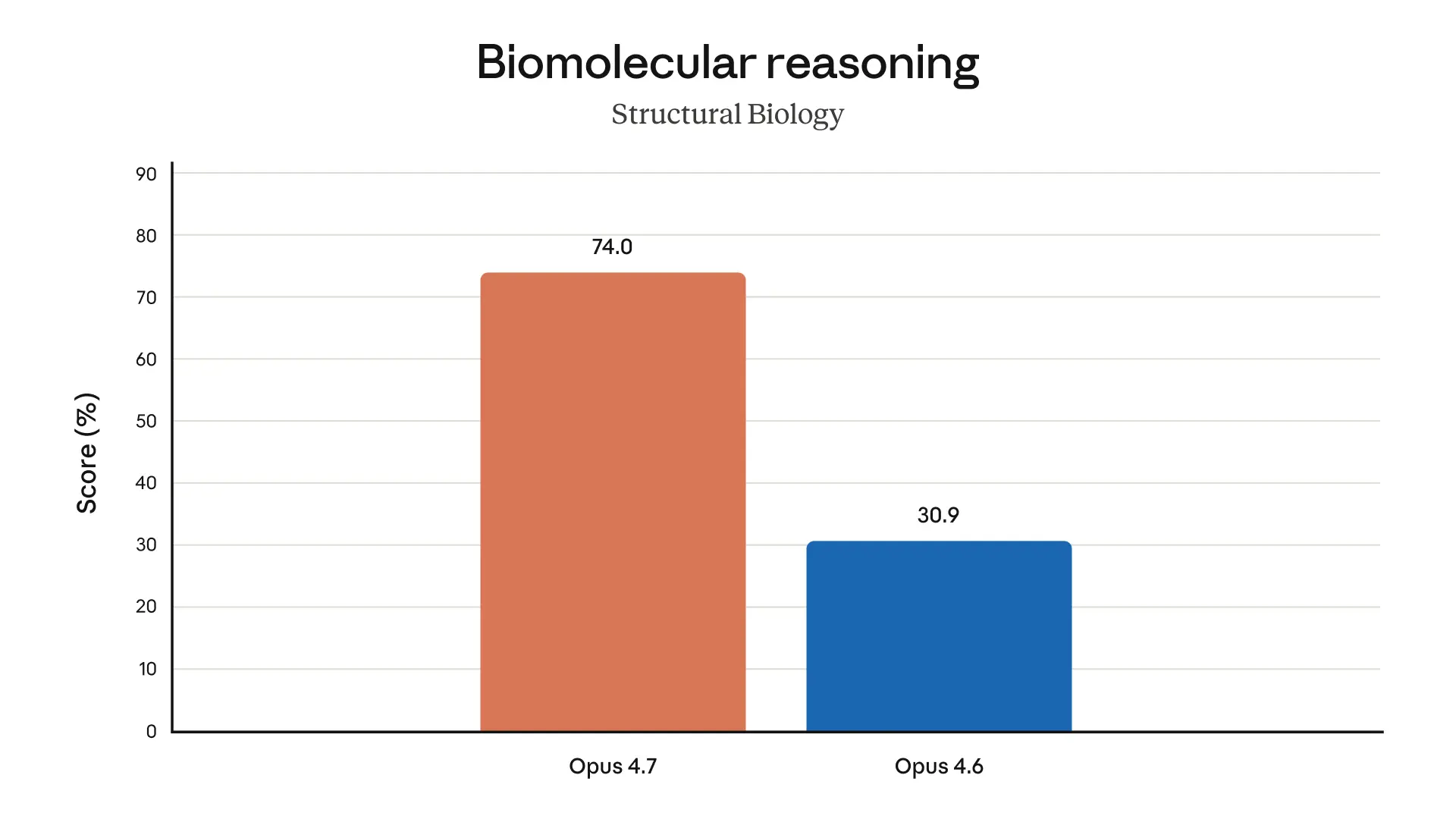
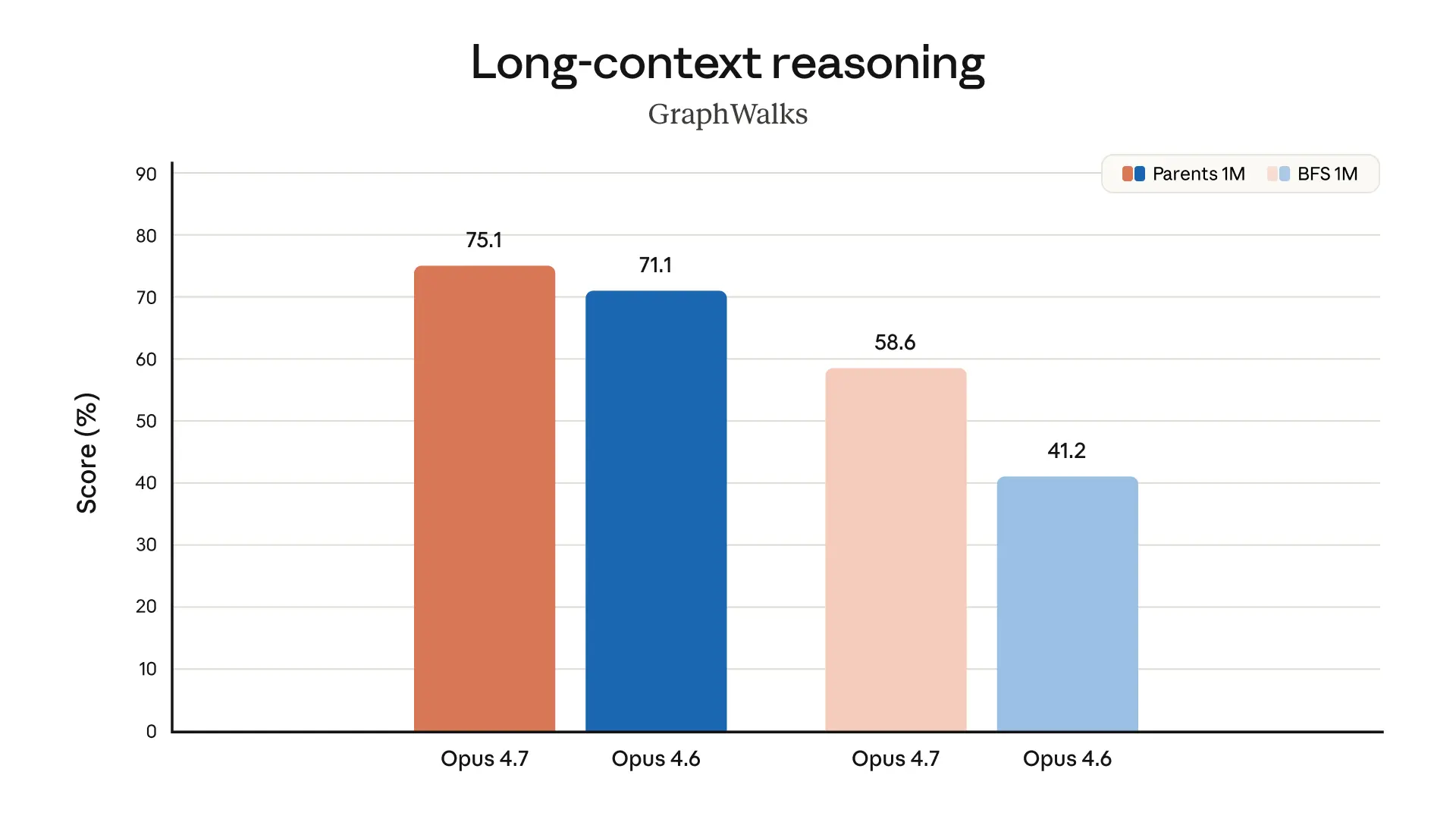
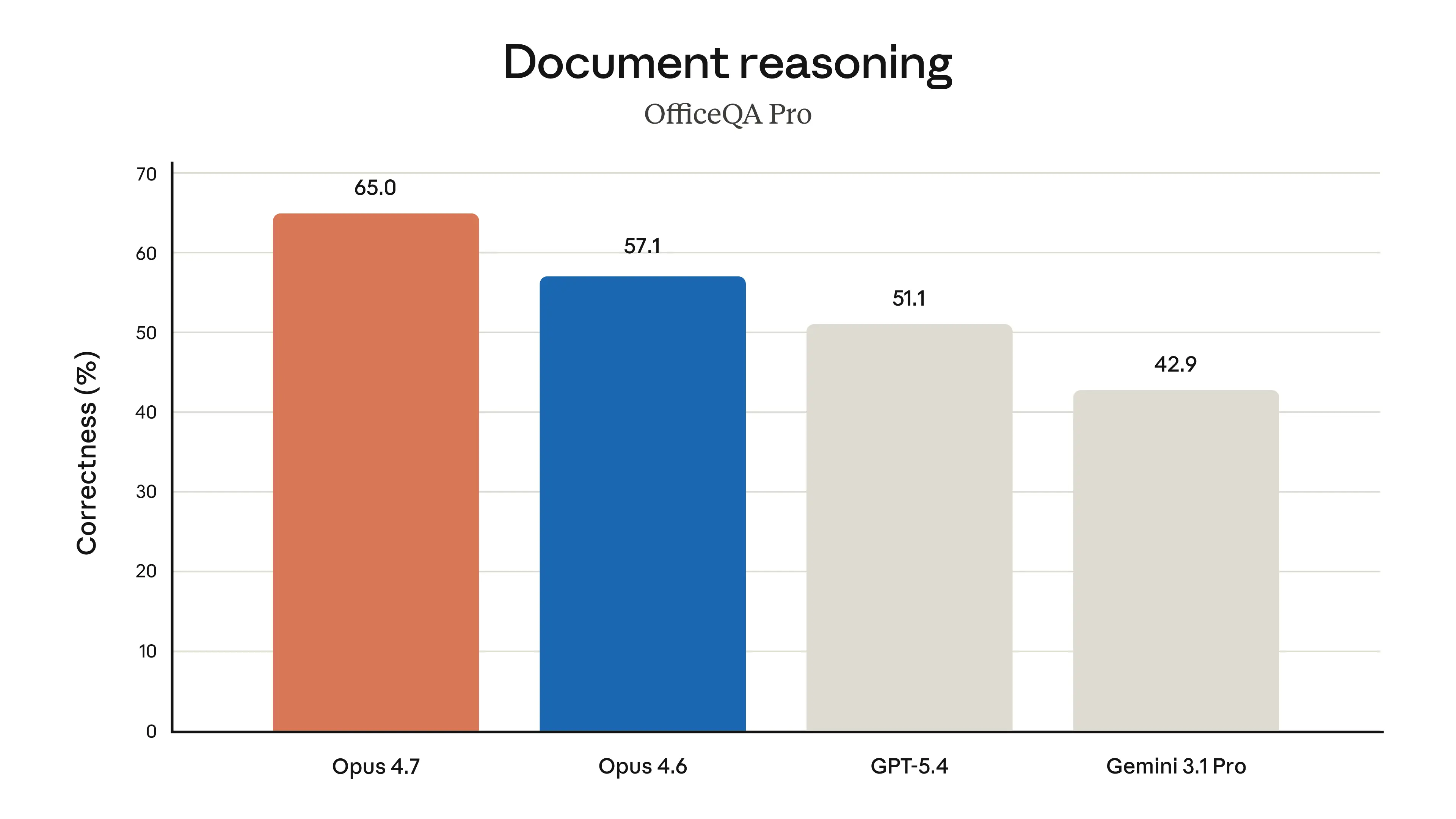
If I were using Claude Code today, I’d try Opus 4.7 first on the nastiest tasks: deep refactors, flaky test triage, multi-file debugging, long-running agent loops, and anything involving logs, traces, or tool use that tends to spiral. I’d especially watch whether it actually stays coherent over hours, because that’s where these models either feel magical or immediately disappointing.
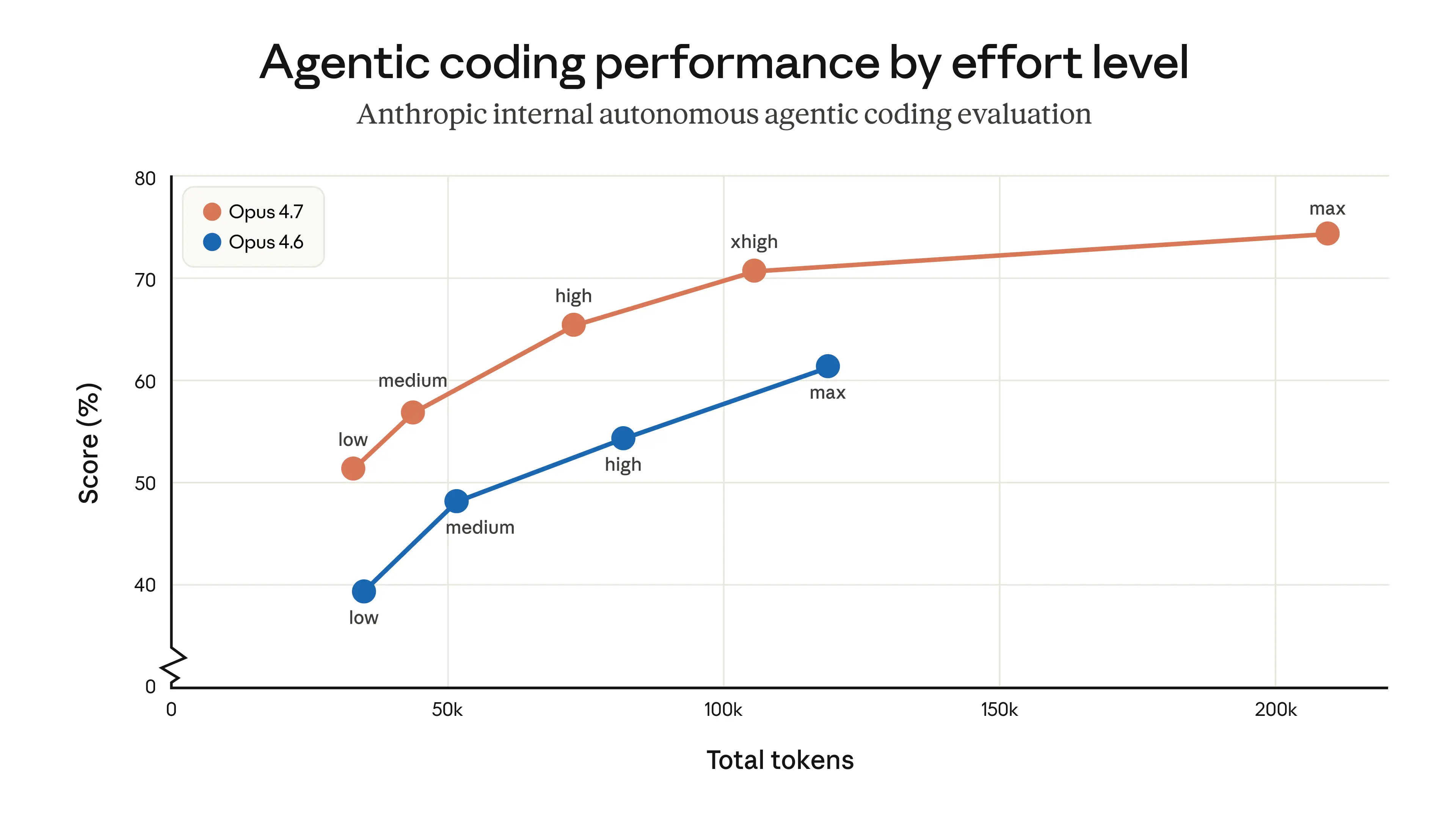
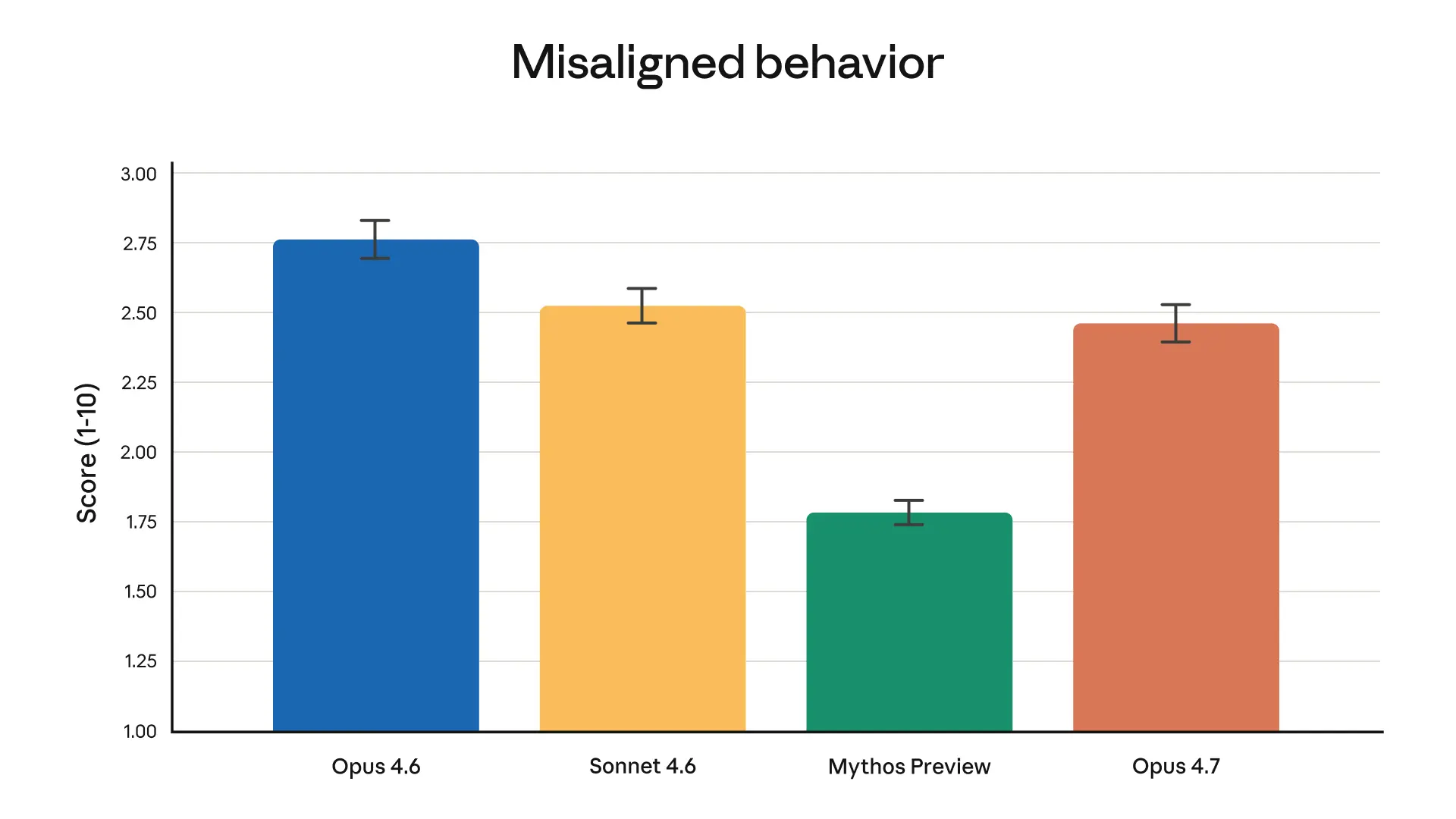
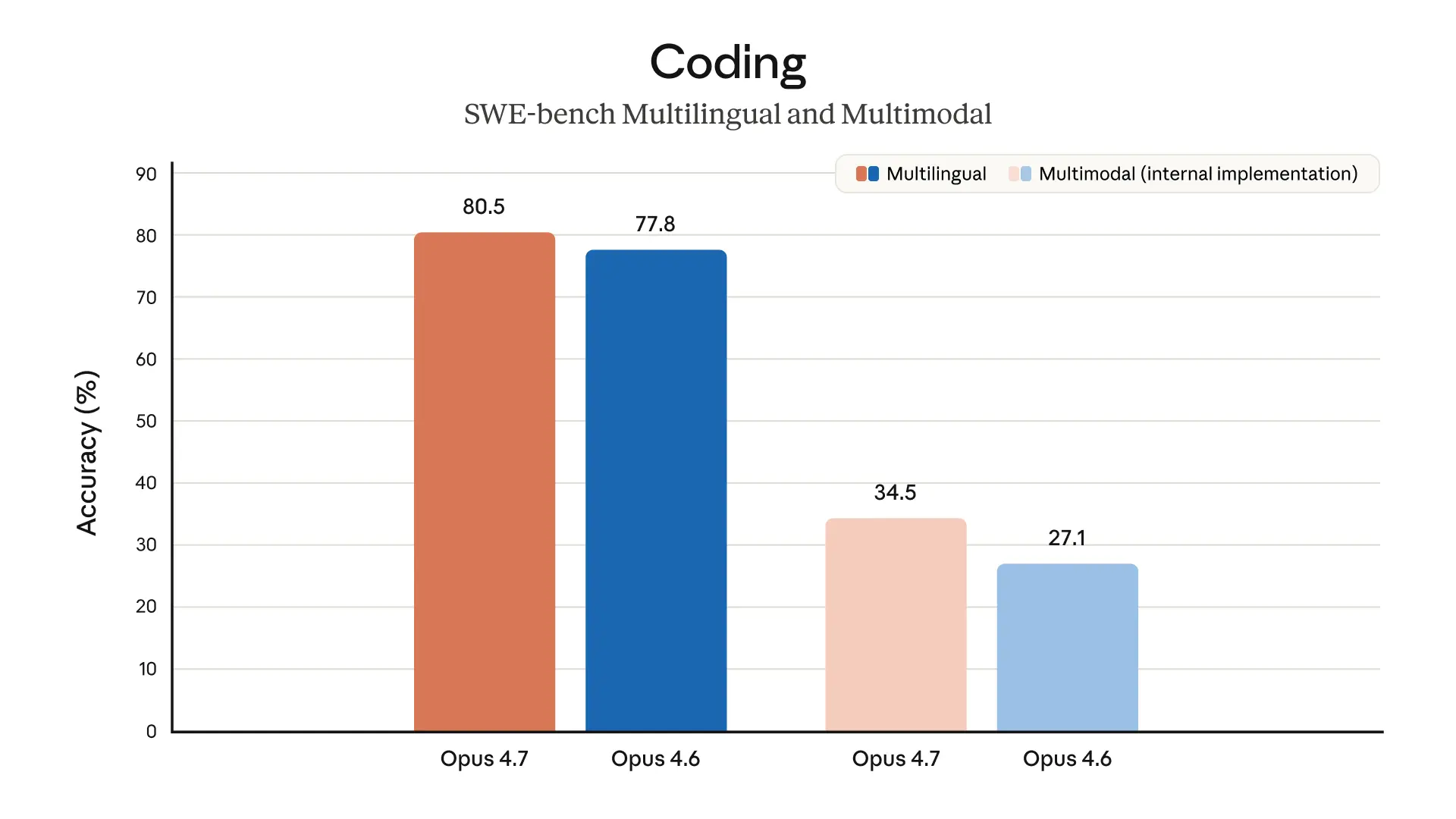
The short version: Opus 4.7 sounds less like a flashy leap and more like a meaningful systems upgrade for serious developer workflows. If the reliability claims are real, this is exactly the kind of model that makes Claude feel more like a teammate and less like a very smart autocomplete.
