From a Claude / Claude Code builder’s perspective, this is a useful reminder that benchmark vibes can get weird fast. Simon Willison’s long-running “pelican riding a bicycle” test is intentionally silly, but it sometimes tracks something real: whether a model can reliably produce a clean SVG illustration from a prompt.

llm-lmstudio plugin.thinking_level: max, but it still didn’t improve much.<!-- Sunglasses on flamingo! -->
What strikes me is how good this is as a reminder that “best model” is always task-specific. If you’re building with Claude or Claude Code, it’s easy to assume the newest frontier model should dominate everywhere, but image-ish structured output in SVG format is one of those places where quirky local models can surprise you.
I think the most interesting part is not that Qwen won a joke benchmark; it’s that it won a second joke benchmark too. That makes the result feel less like random noise and more like a real signal that this particular local setup is unusually strong at turning prompts into playful vector output.

At the same time, I’d be careful not to over-read this. Simon explicitly says he does not think Qwen is “cheating,” and he also says he does not believe the local quantized model is more powerful or more useful than Claude Opus 4.7 overall. That’s the right level of skepticism. A better pelican is not the same thing as a better coding assistant, a better reasoning model, or a better agent model.
If I were using Claude Code day to day, I’d treat this as a nudge toward pragmatic model routing. For code, docs, and agent workflows, Claude may still be my default; for cheap local SVG generation or other self-contained creative tasks, I’d absolutely be curious whether a local Qwen-class model could be the more efficient tool. That’s the real lesson here: pick the model that wins the actual task, not the one with the strongest brand halo.

In short, this post is funny on the surface but genuinely useful underneath. It shows that local models can be surprisingly competitive in specific, weirdly concrete jobs—even when a flagship Claude release is the more formidable system overall.
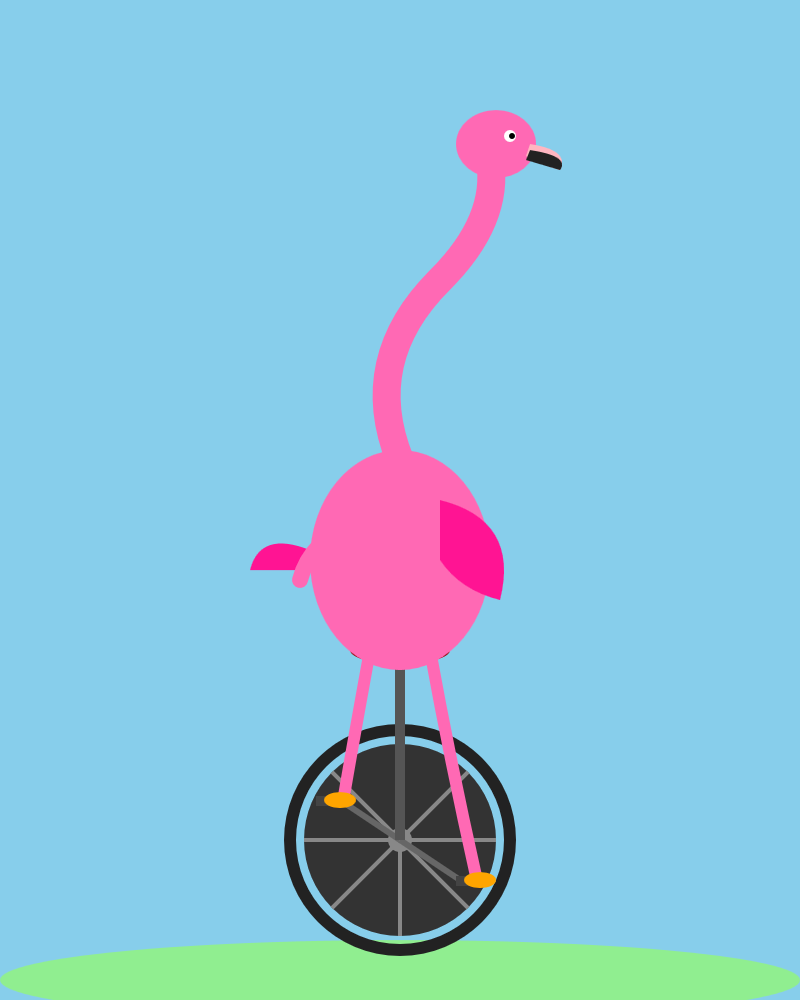
Reference: Qwen3.6-35B-A3B on my laptop drew me a better pelican than Claude Opus 4.7
