画像の一部を自然に埋める「image inpainting」は、地味に見えて実はかなり難しいタスクです。消したい物体の跡を消すだけでなく、周囲の文脈を読んで「そこに本来何があったか」をそれっぽく再現しないといけないからです。木の枝、壁の模様、人の顔。どれも適当に塗れば終わりではありません。



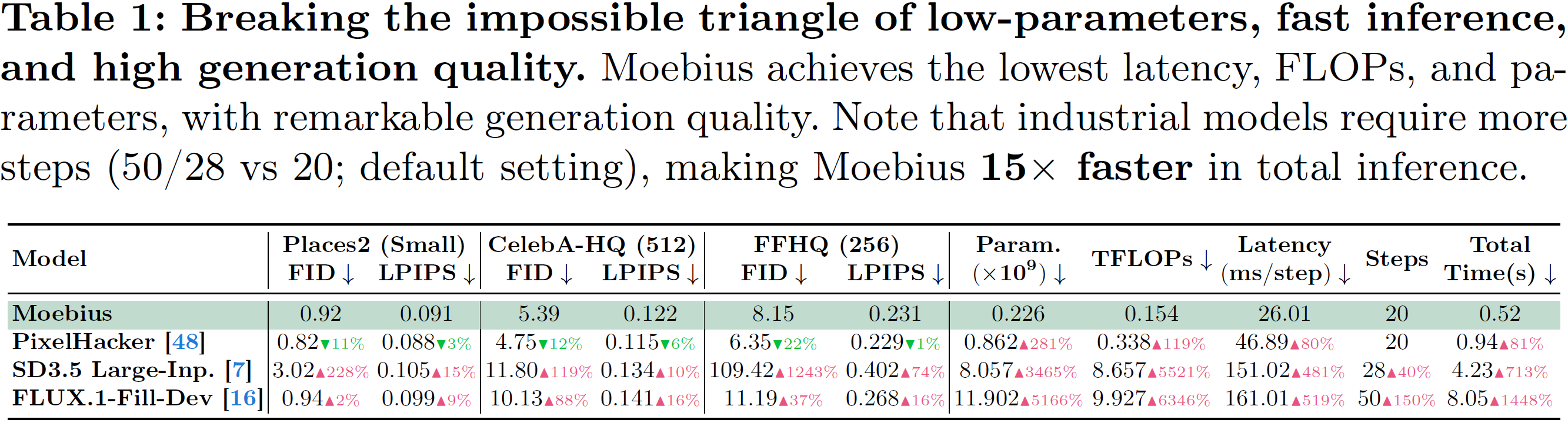
そんな中で登場したのが Moebius です。名前は数学っぽいですが、中身はかなり実務寄り。ポイントは、0.22B(2億2600万)パラメータという小ささで、11.9B級の巨大モデルに迫る、あるいは一部で上回ることを狙っている点です。論文の主張どおりなら、これはかなり痛快です。大きければ勝ち、という空気に「ほんとにそれだけ?」と突っ込んでくるモデルだからです。




















この手の話でまず気になるのは、「軽量化したら画質が落ちるのでは?」という点です。普通はそうです。モデルを小さくすると、表現力が減って、細部の破綻が増えやすい。とくにinpaintingは、周囲の情報を見て違和感のない絵を作る必要があるので、モデルの頭の良さがかなり露骨に出ます。





Moebiusは、その弱点に真正面から手を入れています。
やっていることをざっくり言うと、無駄に重い構造をやめつつ、必要な情報は別のやり方でちゃんと詰め込む、という発想です。





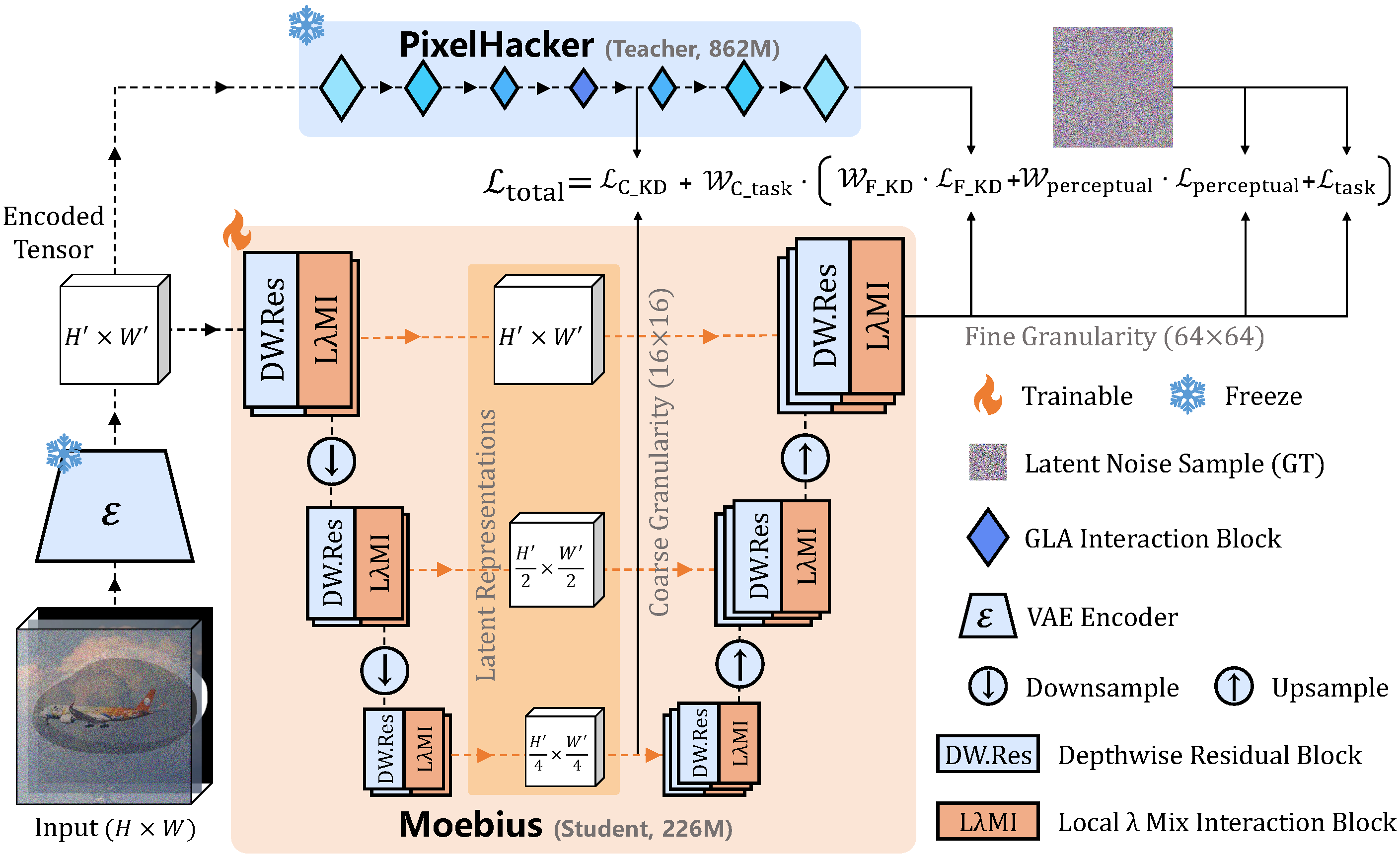
その中心が LλMI block です。論文では、localな文脈とglobalな意味情報を、固定サイズの行列にうまくまとめることで、複雑な相互作用を保ちながらパラメータを大きく減らす、と説明されています。
ここでのポイントは、Transformer系でよく問題になる「計算量の重さ」を避けつつ、ただの簡略版にはしないこと。私はここがいちばん面白いと思いました。軽量化って、どうしても「削る」話になりがちですが、Moebiusは「どうまとめるか」の設計で勝負しています。










もう一つの柱が adaptive multi-granularity distillation です。蒸留というのは、強い先生モデルの振る舞いを小さいモデルに教える学習法のこと。人間でいえば、優秀な先輩のやり方を見ながら仕事を覚える感じです。





Moebiusの面白いところは、これを pixel spaceではなくlatent spaceで行う ことです。
pixel spaceは、ふつうの画像そのものの領域です。一方latent spaceは、画像を圧縮した「意味の詰まった内部表現」のようなもの。ここで学習すると、いちいち重い画像復元を挟まずに済むので効率がいい。地味ですが、実装や計算コストを考えるとかなり大事な差です。





さらに、蒸留のやり方も一枚岩ではなく、細かい中間特徴から、拡散モデル全体の軌道まで、複数の粒度をまとめて合わせる設計になっています。
要するに、「この点だけ真似して」ではなく、「途中の考え方から最終出力まで、なるべく広く学べ」ということです。小さいモデルは容量が限られるので、こういう多層的な教え方をしないと、すぐ頭打ちになるのでしょう。









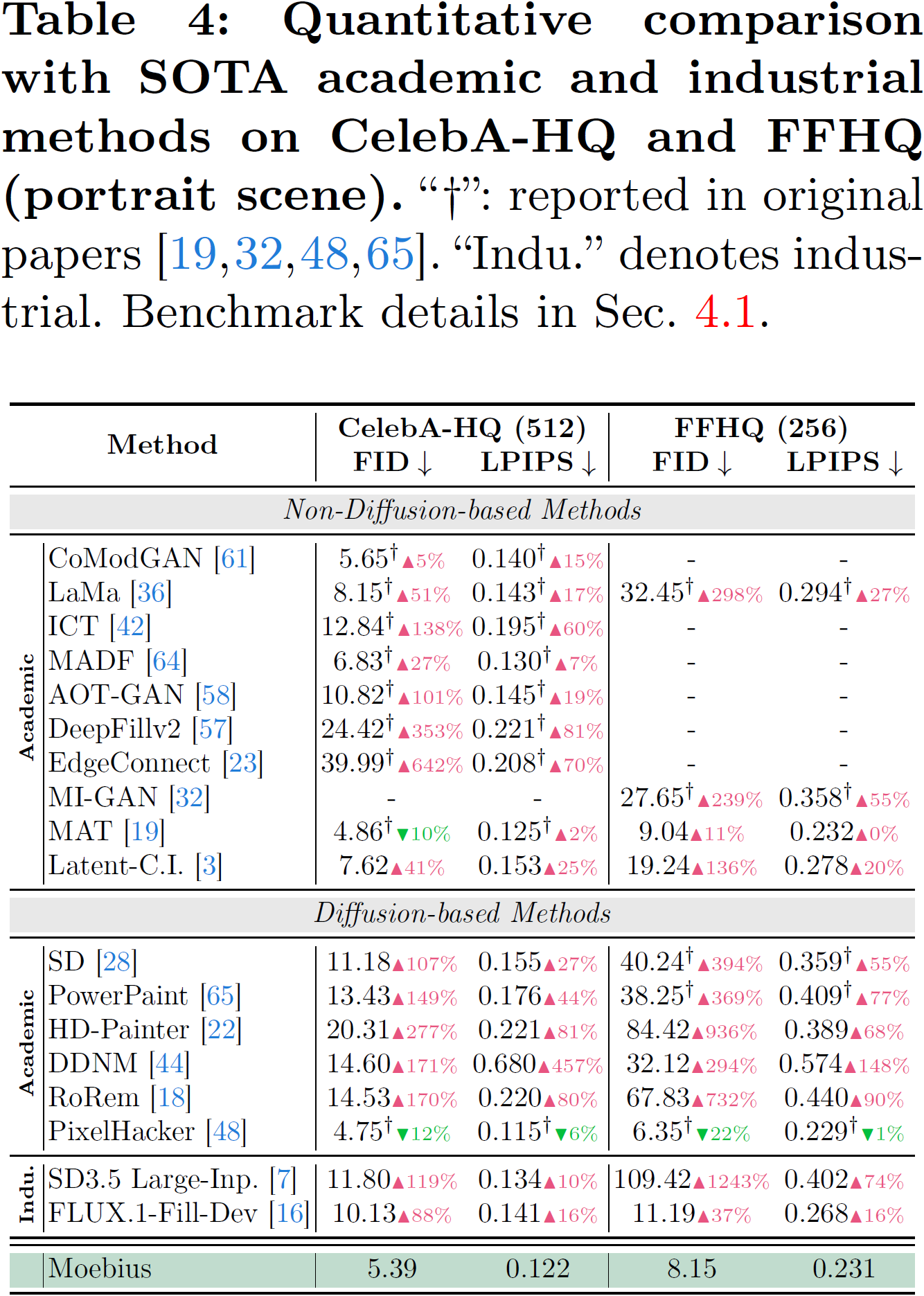
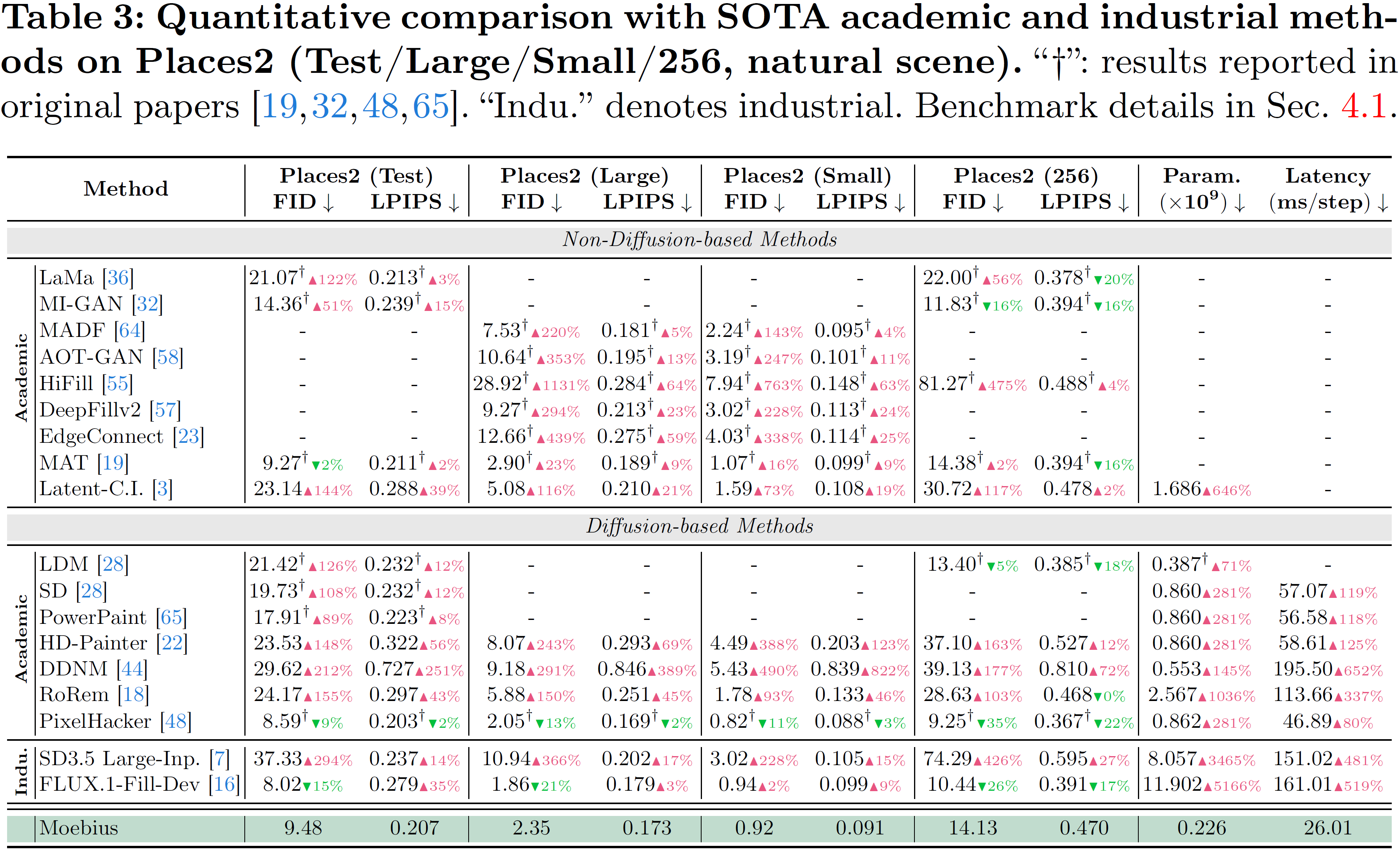
元ページの主張では、Moebiusは自然画像の Places2、人物画像の CelebA-HQ や FFHQ を含む6つのベンチマークで、FLUX.1-Fill-Dev や SD3.5 Large-Inpainting と同等か、場合によっては上回るとしている。
ここはかなり強い言い方ですが、もし再現性が取れるならインパクトは大きいです。





しかも、単に「少し速い」ではありません。15倍超の総推論時間短縮をうたっていて、1ステップの推論は 26.01ms。この数字は、研究用途のデモとして見るとかなり気持ちいいです。巨大モデルを回すときの「うわ、重いな…」という嫌な感じを、かなり減らしてくれそうです。





ただし、個人的にはここで少し冷静にもなります。
高性能な基盤モデルと、タスク特化の軽量モデルは、そもそも勝負の土俵が少し違います。だから「小さいのに勝った!」と単純に言い切るより、用途が明確な場面では軽量特化型がかなり強い、と見るほうが実態に近い気がします。Moebiusはまさにその方向を押し進めているモデルです。










Moebiusのメッセージは、ただの性能自慢ではありません。
むしろ、「タスクがはっきりしているなら、巨大な汎用モデルを毎回呼び出す必要はあるのか?」という問いかけに見えます。





これはかなり重要です。生成AIの世界は、どうしても「より大きく、より多機能に」が正義になりがちです。でも実運用では、遅い・高い・重い、の三拍子がそろうと一気に使いづらくなる。とくに画像修復やオブジェクト除去のような機能は、写真編集、EC、モバイルアプリ、エッジ端末など、現場では軽さがものを言います。





Moebiusはそこに対して、**“専用機は専用機で強い”** と言っているわけです。私はこの姿勢にかなり好感があります。AIは何でもできるほど偉い、という空気に少し疲れていたので、こういう割り切りはむしろ健全に見えます。










このモデルが真価を発揮しそうなのは、やはりリアルタイム性や導入コストが気になる場面でしょう。たとえば、写真の不要物消去をアプリに載せたいとき、サーバーコストを抑えたいとき、あるいは端末側で軽く動かしたいときです。





特に画像のinpaintingは、見た目の自然さがすぐ評価されます。少しの破綻でも目立つので、モデルの「賢さ」と「速さ」の両方が必要です。Moebiusは、その両立をかなり本気で狙っているように見えます。





もちろん、論文ページの段階では「どこまで現場で安定するか」はまだ見極めが必要です。でも、少なくとも方向性は明確です。
巨大モデルのコピーではなく、目的に絞った最適化で勝つ。 この思想は、今後いろいろな画像生成・編集タスクに波及していくのではないかと思います。










Moebiusは、「小さいから妥協したモデル」ではなく、小さいこと自体を武器にしようとするimage inpainting専用モデルです。
LλMI blockで構造を削り、蒸留で知識を濃縮し、latent space中心で効率よく学ぶ。発想が筋道立っていて、しかも結果として10B級に迫る性能を名乗っている。こういう研究は見ていて気持ちいいです。





巨大モデルの時代に、あえて“細くて速い専門家”を作る。
Moebiusは、その流れをかなりわかりやすく示す例だと思います。