vLLM の記事「Micro-Agent: Beat Frontier Models with Collaboration inside Model API」は、ひとことで言うと「モデルを返すだけのサーバー」から「モデルの力を組み立てるサーバー」へ、という話だ。
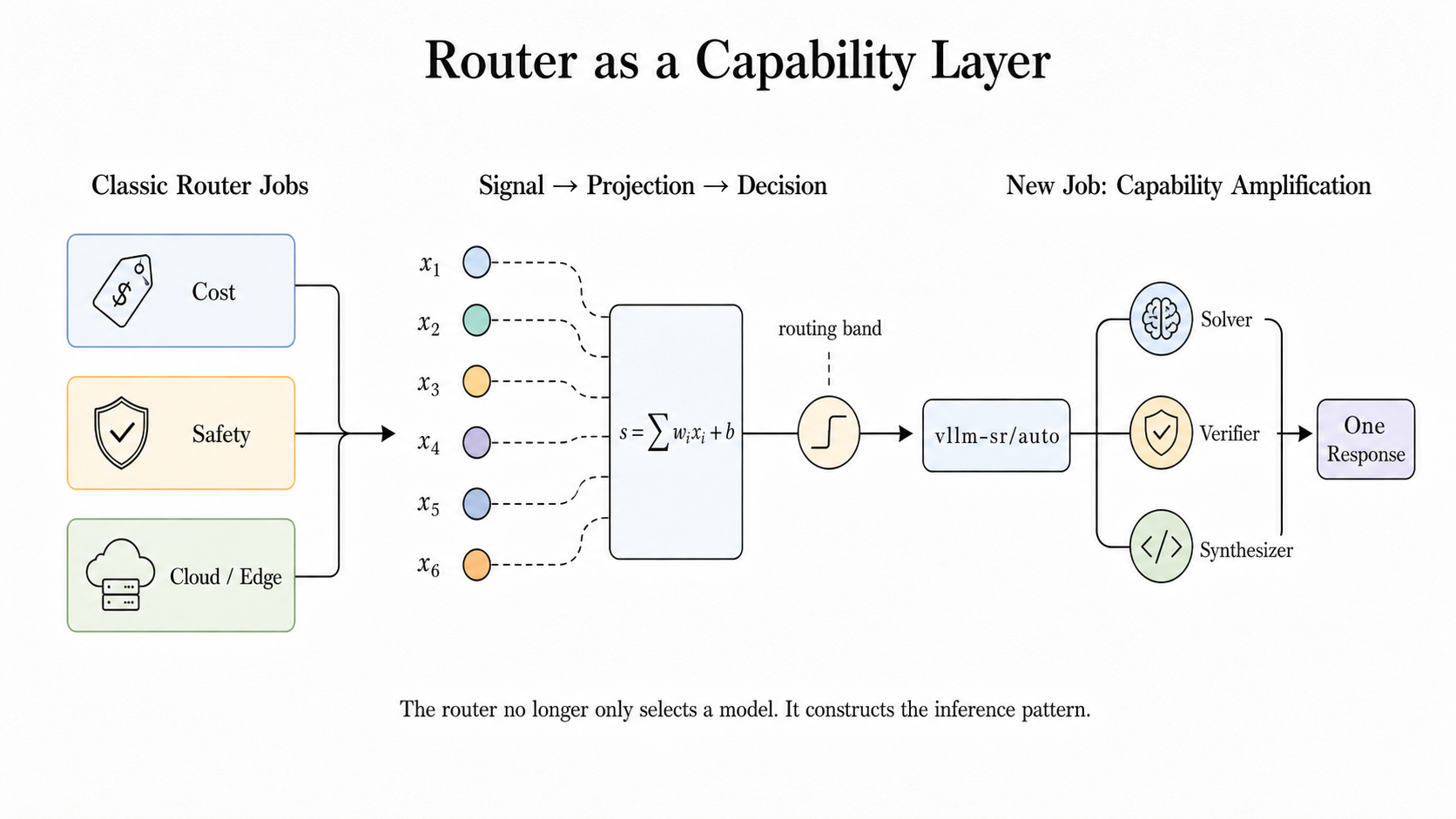
普通、APIで model を指定したら、そのモデルが1回答えて終わりだ。ところが vLLM Semantic Router は、表向きは vllm-sr/auto という1つのモデル名を見せながら、裏側では必要に応じて複数のモデルを動かす。しかもそれを、アプリ側に見せびらかさない。ここがまず面白い。
![]()
たとえば、簡単な質問なら安い候補で済ませる。自信が足りなければ次の候補に回す。複数案を並列で出して、良さそうなものをまとめる。あるいは、役割分担した worker に仕事を振って、最後に finalizer が整える。こうした「協調」を、単なるアプリの工夫ではなく、サービング層の機能として持ち込もうとしている。
私はこの発想、かなり筋がいいと思う。なぜなら、現実のAI運用は「最高性能のモデルを1つ置けば全部解決」ではないからだ。速さ、コスト、安全性、出力形式の厳守。全部のバランスを見ながら動かす必要がある。ならば、サーバー側がその判断を持つのは自然だ。
記事の中心にあるのは「routerはモデル選択だけでなく、capability construction をやる」という考え方だ。日本語で雑に言えば、「どのモデルを使うか決める係」から「どう組み合わせれば賢くなるか考える係」へ進化する、ということになる。
![]()
vLLM Semantic Router では、これを looper と呼んでいる。looper は、bounded micro-agents のための runtime だ。bounded というのは「無制限に暴れないよう制約がある」という意味で、ここが大事だ。いわゆる野放図な agent ではなく、予算・回数・時間・失敗時の挙動までちゃんと縛られている。
記事で挙げられている主なパターンは次の通りだ。
どれも「たくさんモデルを呼ぶ」だけではない。どこで止めるか、何を成功とみなすか、失敗したらどう戻るかまで含めて一つの runtime として設計している。ここに、この記事の本気度がある。
個人的に見ていて一番実務っぽいのは Confidence だと思う。
やっていることはシンプルで、まず安い候補に答えさせて、その自信度を測る。自信が十分ならそこで終了。低ければ次へ進む。これだけだ。だが、これが実運用ではかなり効く。全部を高級モデルに投げるのは、どう見ても無駄が多いからだ。
自信度の判定には、token-level log probability、logprob margin、self-verification、AutoMix風の entailment verifier などが使えるとある。要するに「答えの見た目」ではなく「答えの確からしさ」を何らかの数値で見ている。
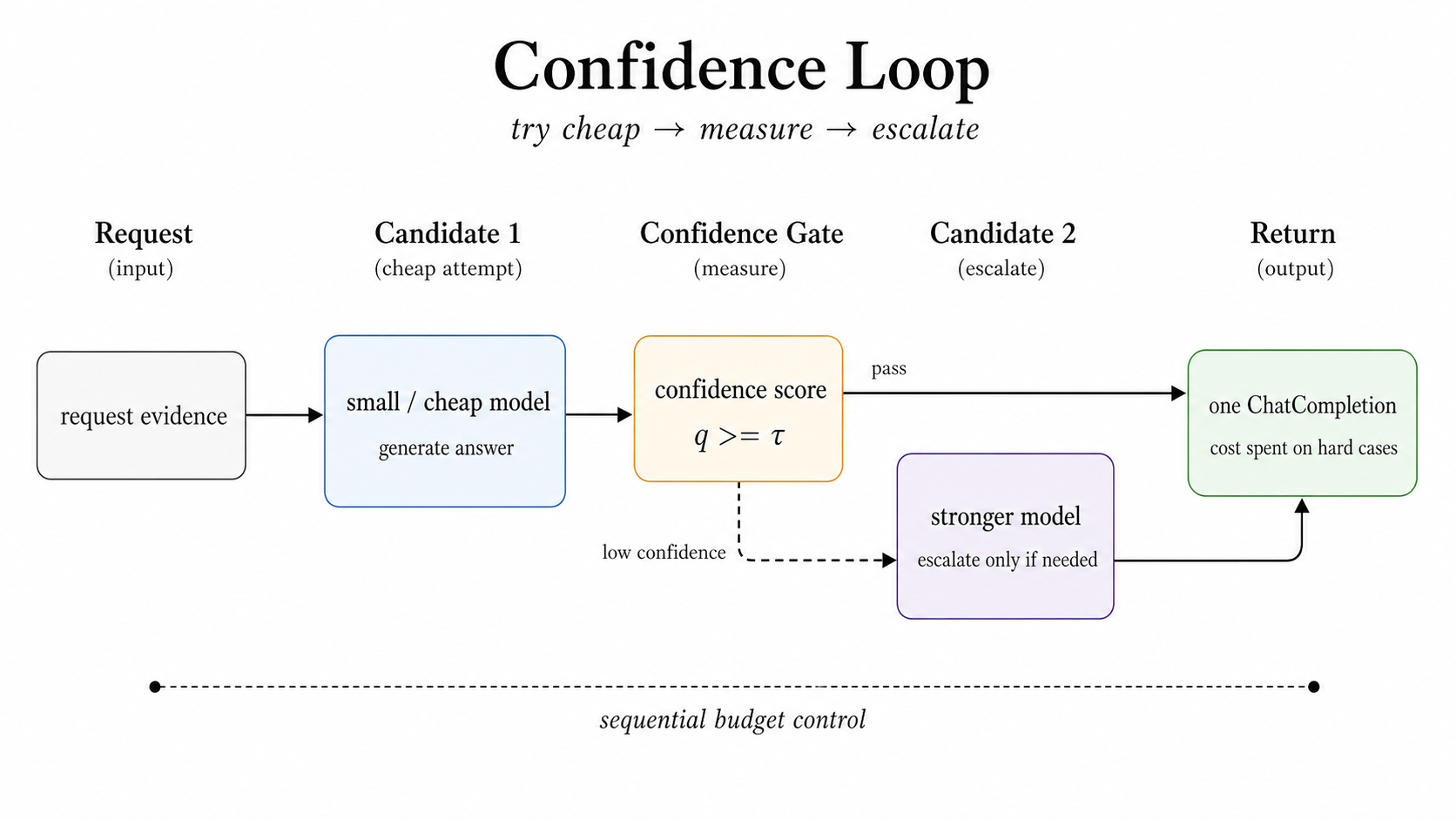
こういう仕組みは派手ではない。でも、コスト削減と品質維持を同時にやるなら、こういう地味な制御がいちばん効くことが多い。現場ではたぶん、こういうものが一番愛される。
Ratings は、複数候補を並列実行するけれど、max_concurrent という上限をきっちり置く。ここも好感が持てる。AIシステムでありがちなのは、「とにかく並列にすれば速いし強いでしょ」という雑な発想だが、それだとコストがすぐ爆発する。
Ratings は、A/B テストや ensemble 的な使い方に向いているとされている。つまり、複数候補の品質差を見ながら統合したい場面だ。しかも rating-aware aggregation なので、単純平均ではなく評価を加味してまとめる。
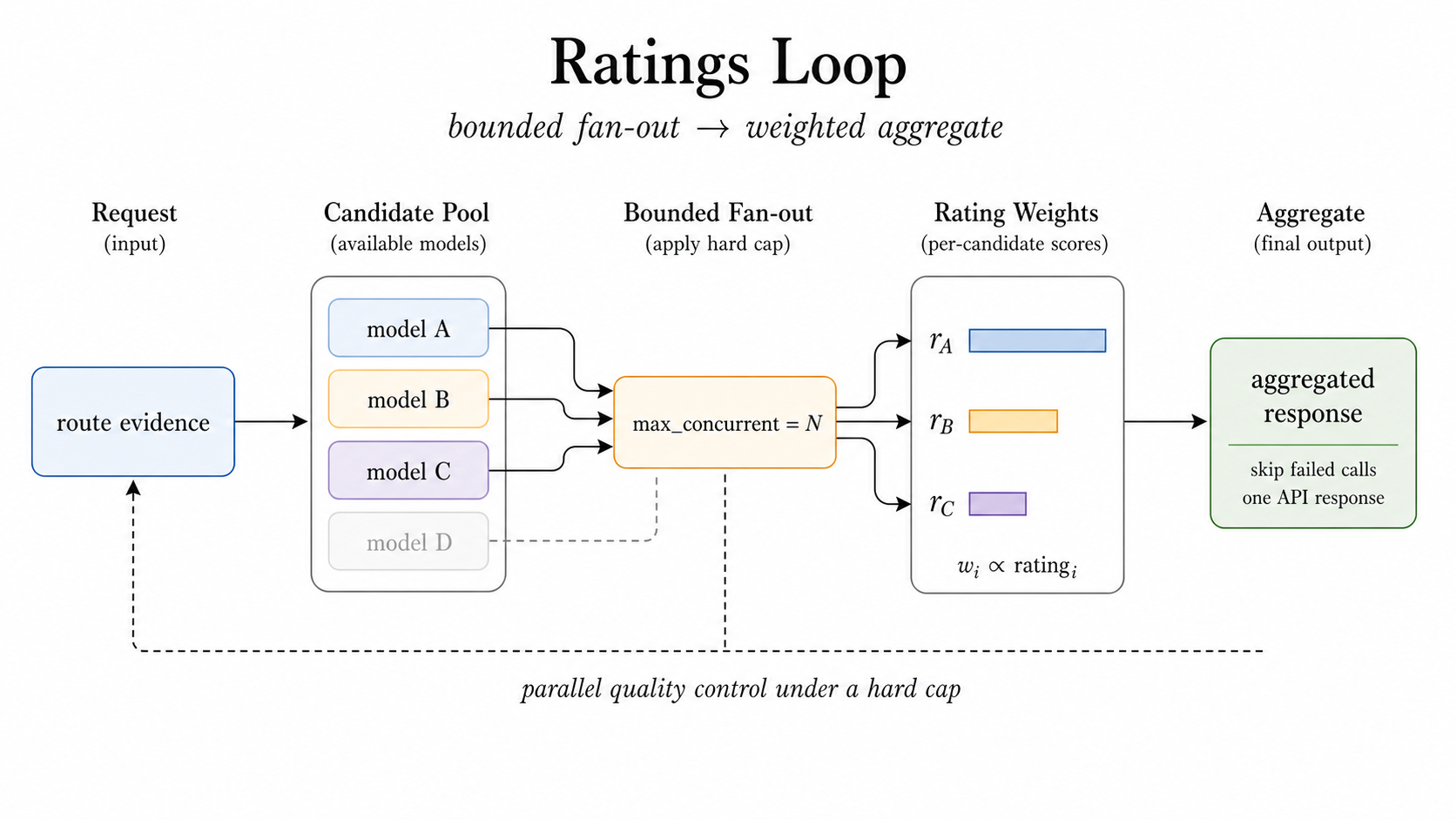
私はここに、サービング層が「推論の実験装置」から「制御された運用基盤」に変わる感じを見る。好き放題に試すのではなく、上限を守りつつ賢く並列化する。地味だけど重要だ。
ReMoM は repeated mixture-of-model reasoning の略で、複数の reasoning を広く集め、ある程度そろったら synthesis に回す方式だ。ポイントは、答えの形式を壊さないこと。問題が難しいほど、推論の途中でゴチャつきやすいが、最終的には API としてちゃんとした形で返す必要がある。
記事では、synthesis が失敗しても、前段の worker が有効な evidence を出していれば、それを fallback にできるとある。これがかなり実務的だ。AIはたまに「最後のまとめ」でコケる。そういうとき、全部エラーで返すのではなく、手元にある妥当な材料で返せるのは強い。
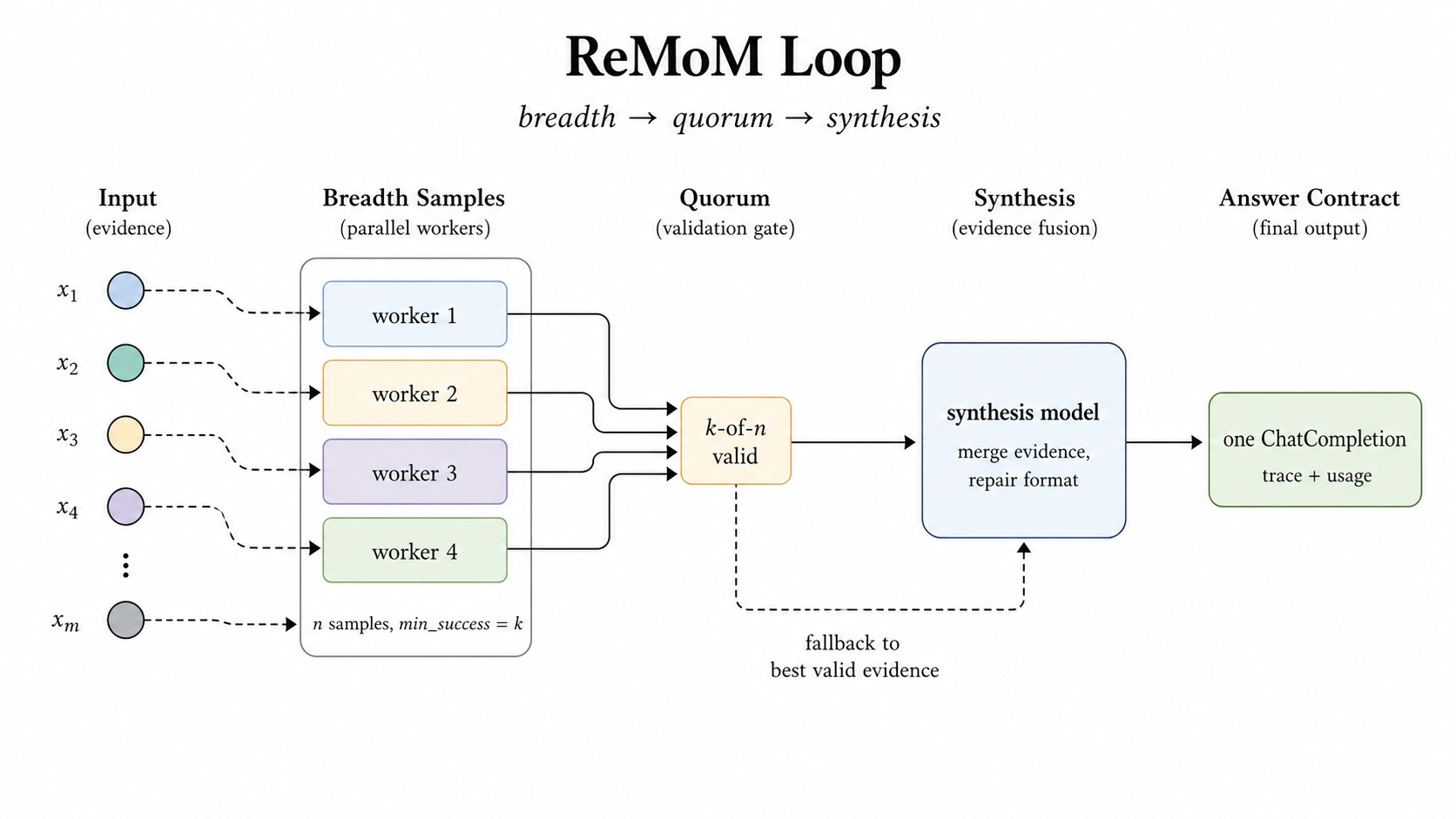
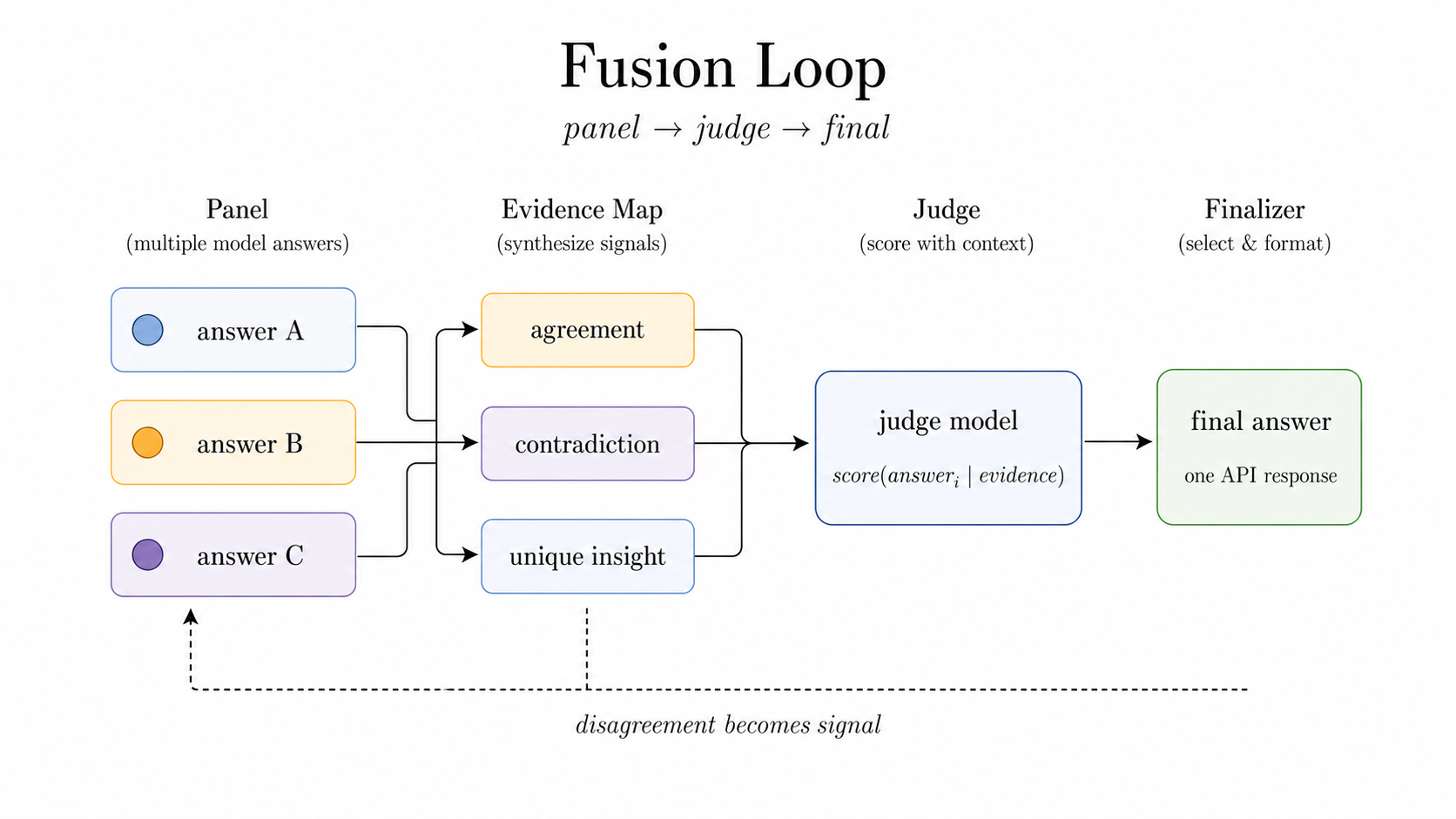
一方の Fusion は、disagreement そのものを signal にする。これは発想が少し違う。答えを平均するのではなく、意見の食い違いを見て judge が判断し、finalizer が1つにまとめる。複数の答えが食い違うことを「失敗」と見なすのではなく、「そこに価値がある」と見るわけだ。
この違いは面白い。ReMoM は breadth と quorum を重視する。Fusion は disagreement の構造を重視する。似ているようで、世界の見方が違う。
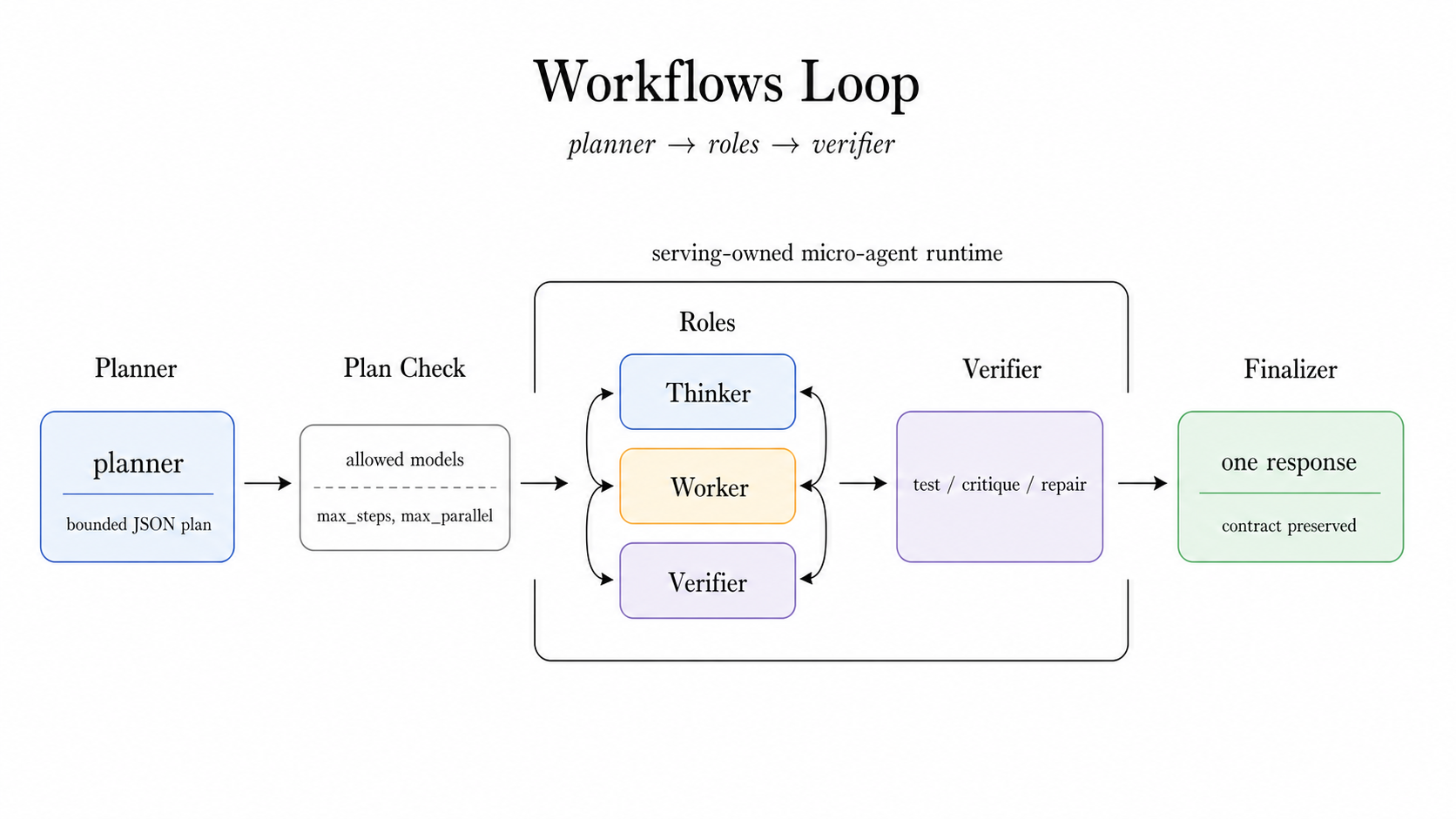
Workflows はいちばん agent らしい。planner がいて、worker がいて、verify があって、最後にまとめる。いわば小さなチームだ。
でも記事は、ここでも「無制限な自律エージェント」にしない。allowed worker models を制限し、plan を検証し、max steps、max parallelism、timeout、error policy を持たせる。つまり、強力だけど、あくまでインフラの管理下に置く。
これは重要だと思う。agent という言葉は便利すぎて、気を抜くと「勝手に何でもやってくれる魔法」に見えてしまう。でも実際には、何をさせるか、どこで止めるか、失敗したときどうするかを決めるほうが難しい。vLLM の記事は、その難しさを正面から扱っている。
この記事のいちばん芯にある主張はここだと思う。
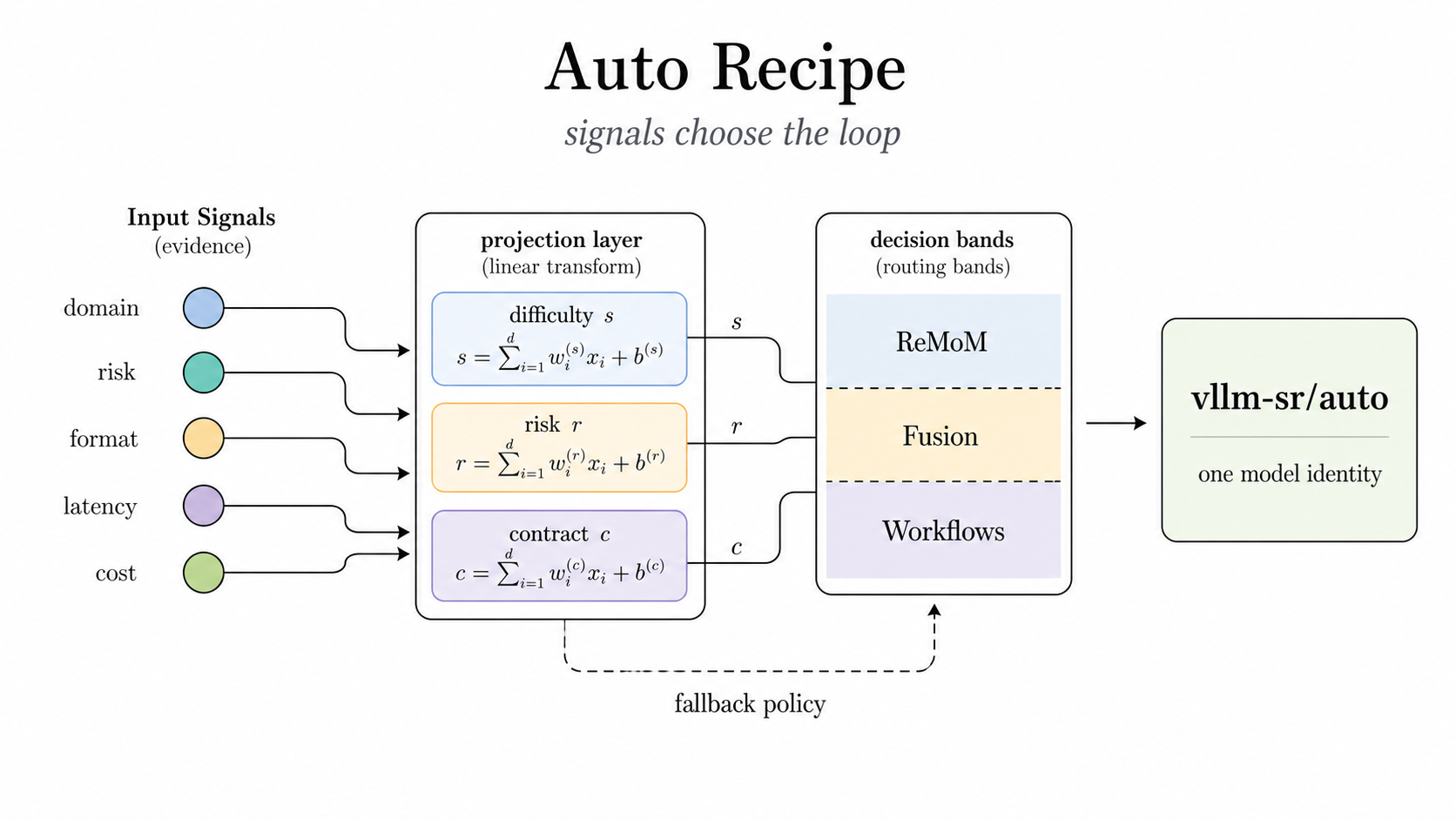
最適なループは、タスクの形で決まる
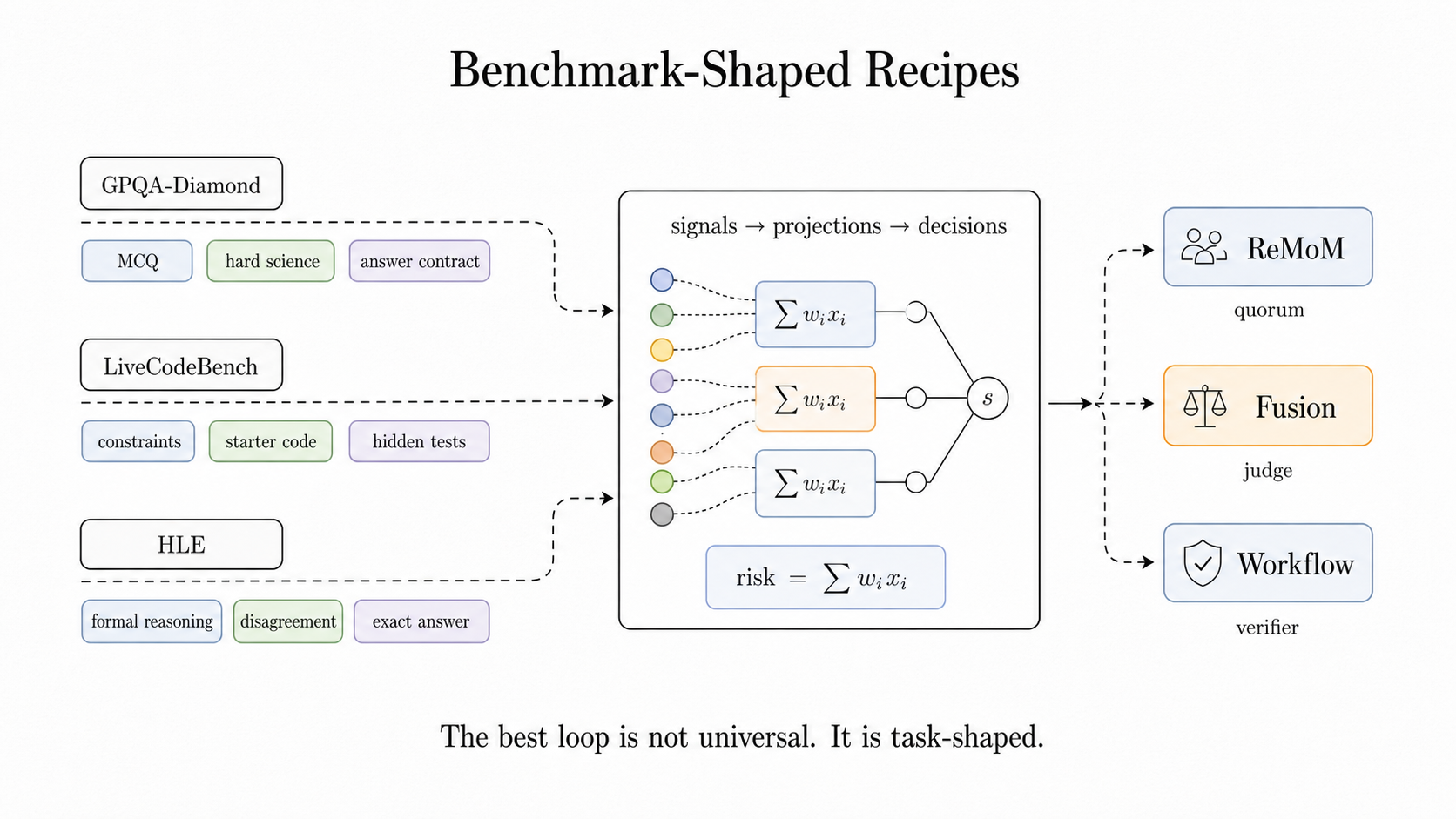
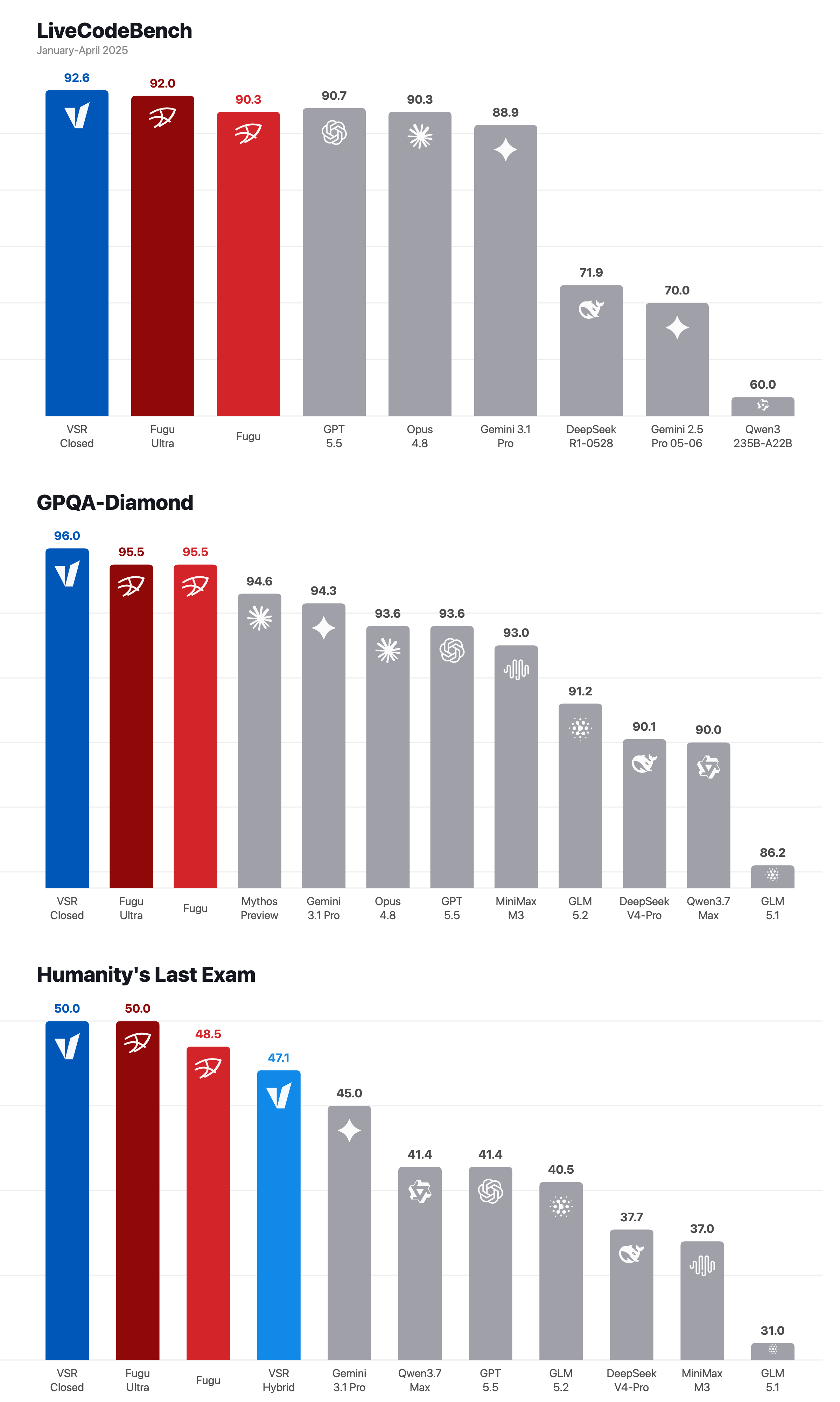
GPQA-Diamond みたいな multiple-choice では、答えの形式を壊さないことが大事だ。LiveCodeBench では、コードが実際に動くことや hidden test に耐えることが大事だ。Humanity’s Last Exam では、厳密な答えの形式や disagreement の解消が大事になる。SWE系では、planner / patcher / verifier / finalizer のような分業が必要になる。
つまり、何でも同じループで回すのは雑すぎる。vllm-sr/auto は「常に最大のループを回す」ではなく、「この問題にはこの recipe を使う」という自動選択であるべきだ、という話になる。
この考え方はかなり健全だと思う。AI界隈はどうしても「万能」への誘惑が強い。でも実際に強いシステムは、たいてい task-shaped だ。仕事の形にちゃんと合わせている。
記事では、Closed / Hybrid の recipe でいくつかの benchmark を見ている。LiveCodeBench、GPQA-Diamond、Humanity’s Last Exam だ。数字そのものを細かく追いかけるより大事なのは、「これは単なるアイデアではなく、性能としても成立している」と示している点だ。
ただし、記事自身もかなり慎重だ。ここは好印象だった。つまり、「このスコアだから全部置き換えられる」とは言っていない。そうではなく、router-owned collaboration によって、個々のモデル呼び出し以上の強い model identity を作れる、という主張だ。
この見方は正しいと思う。AIシステムの価値は、単体のモデル点数だけでは決まらない。どのように組み合わせ、どの条件で止め、どの失敗を許し、どの出力契約を守るかで、かなり違ってくる。スコアカードはその一部を証明しているにすぎない。
昔の serving stack は受け身だった。モデル名を受け取り、裏の backend に流すだけだった。けれど記事が描く次の層は、もっと積極的だ。
このリクエストは難しいのか。危ないのか。安く済ませるべきか。複数案を出すべきか。どの output contract を守るべきか。失敗したら何を返すべきか。そういうことをサーバー自身が考える。
これは、単なる「ルーター」の話ではない。推論の運用設計そのものが、モデル API の中に溶け込んでいく話だ。
個人的には、ここはかなり大きな変化だと思う。これまでアプリ開発者が無理やり組んでいた agentic なロジックを、サービング基盤が標準機能として吸収し始めている。もしこれが広がるなら、AIアプリの作り方そのものが少し変わるはずだ。アプリは「どう頼むか」より、「何を求めるか」に集中し、裏の配線はサーバーが面倒を見る。そんな未来が見える。
参考: Micro-Agent: Beat Frontier Models with Collaboration inside Model API
