Databricksのこの記事は、Postgresを土台にしたサーバーレスDB「Lakebase」と、その先にある「LTAP」という考え方を紹介しています。
話がかなり技術寄りなので、最初は「何のことだ?」となるかもしれません。でも中身はわりとシンプルで、ひと言でいえばデータベースの“保存のしかた”を根っこから見直そうという話です。
いま多くのデータベースは、書き込みログも実データも、だいたい1台のマシンの中で抱え込んでいます。この記事はそこを「そもそも古くないか?」と疑い、クラウド時代に合う形へ組み替えています。ここがかなり面白い。
しかも単なる理想論ではなく、書き込みの安全性、読み取りの拡張、障害対策、分析処理との干渉まで一気に整理しているのがポイントです。
この記事の出発点は、かなり本質的です。
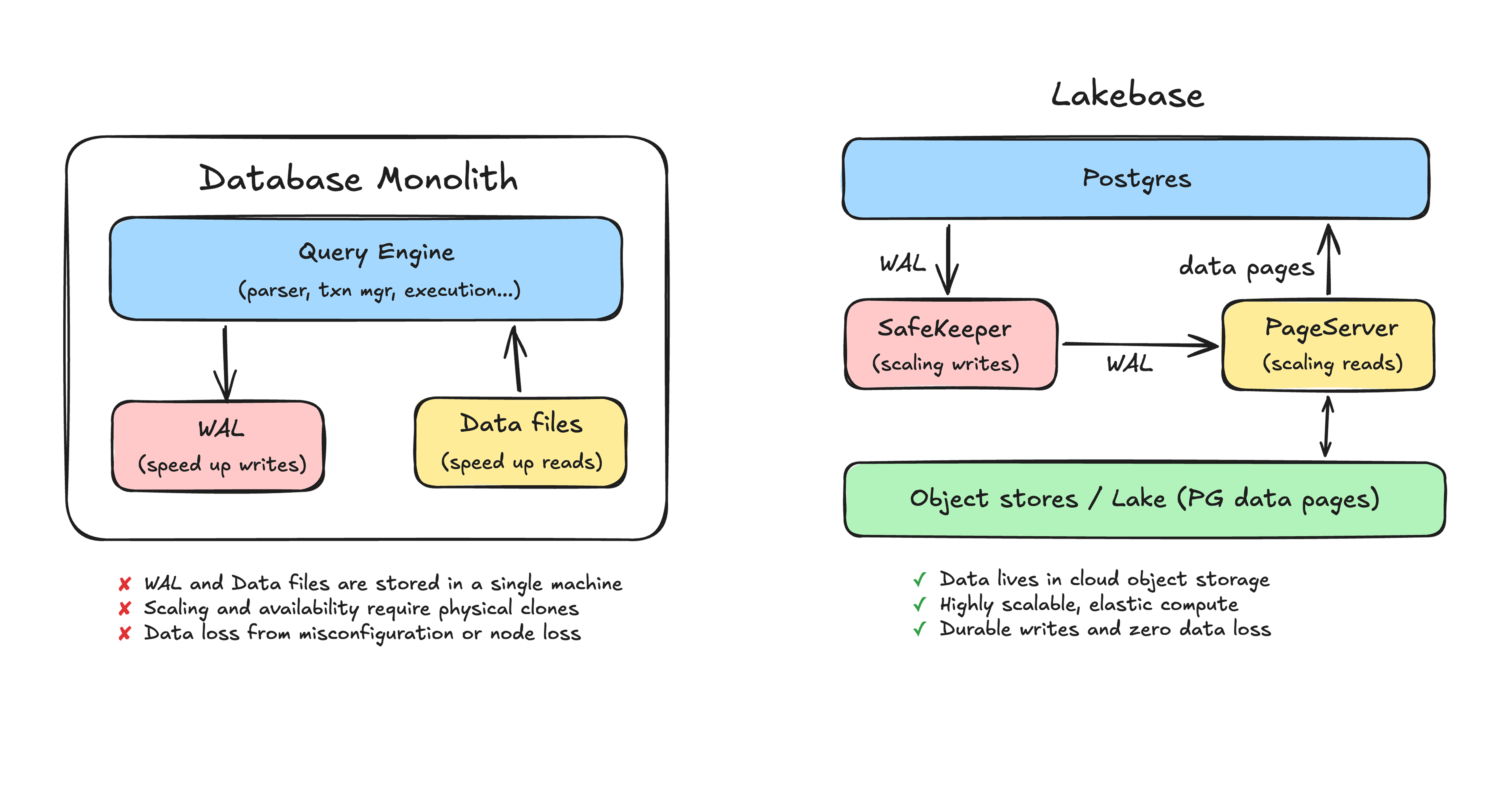
ふつうのDBは、見た目は高機能でも、裏側では「WAL」と「data files」を同じ機械の中に置いています。
WAL は write-ahead log の略で、変更内容をまず順番に記録するログです。これにより、行データをいきなり書き換えるより速く、安全に書き込みできます。
data files は、実際のテーブルの内容そのもの。読み取りはこっちを見るので、クエリが速くなります。
つまり、WAL は書き込み向け、data files は読み取り向け。役割分担としてはよくできています。
ただし、その両方を1台のマシンに閉じ込めると、いろいろ苦しくなる。
たとえば、ディスクへの flush 設定を間違えると、コミット済みのはずの変更が消えることがある。これは怖い。しかも厄介なのは、設定ミスが静かに事故へつながる点です。
さらに、そのマシンのディスク自体が壊れたらどうするのか。RAID やネットワークストレージで多少ましにはなっても、根本的には「その箱が死んだら終わり」という構造から逃げられません。
読み取りを増やしたいなら read replica を作る。でもこれはDBの物理コピーを丸ごともう1台持つようなものです。データが大きいほど重いし、立ち上げにも時間がかかる。
高可用性も同じで、primary が落ちたときのために standby を置く。結局、似たような箱を何台も抱えることになり、コストが膨らむ。
そして、分析クエリがトランザクション処理を邪魔する。これもよくある話です。
大きな集計やデータ整理を走らせると、普段は軽快だったアプリの更新まで重くなる。DBを1つの共有資源として使っている以上、避けにくい問題です。
個人的には、ここで語られている問題の多くは「DBソフトの性能不足」というより、保存モデルが古いことから来ている、という見方がしっくりきます。性能チューニングで頑張る前に、置き場所の設計がまずい。この記事はそこを容赦なく突いています。
Lakebase の発想は、クラウドの強みを素直に使うことです。
いまのクラウドには、安くて壊れにくい object storage と、必要に応じて増減できる compute があります。だったら、DBもそこに合わせて作り直せばいい、というわけです。
そのために Lakebase は、Postgres の compute を stateless にします。
stateless というのは、計算する部分が自分ではデータを抱え込まない、という意味です。データ本体は外に出して、compute は必要なときだけ起動し、止め、複製できるようにする。
この役割分担がかなりうまい。
DBの頭脳と記憶を切り離すことで、スケールや可用性の話が一気に楽になります。
Lakebase の中核は2つの外部サービスです。
ひとつは SafeKeeper。これは WAL を受け持つ役割です。
もうひとつは PageServer。こちらは data files 側を受け持ちます。
SafeKeeper は、ローカルディスクへの flush で耐久性を担保するのではなく、複数の SafeKeeper ノードへ quorum でレプリケーションします。quorum は「過半数など、合意が成立したとみなせる数」のことです。
要するに、1台のディスクに命運を預けるのではなく、ネットワーク越しに複数台へ広げて、そこで安全性を確保するわけです。
この話の良いところは、ただ「分散してます」で終わらないことです。
従来のDBだと、耐久性を上げると性能が落ちやすい。ところがこの記事では、クラウド上の設計でそれを崩そうとしている。もし説明どおりなら、かなり筋がいいです。
PageServer の役割も重要です。
data files を外に置くことで、compute は必要に応じて立ち上げ直せるし、読み取り側の拡張もやりやすい。
つまり、DBを「1台のマシンに全部載せる」のではなく、「保存層と計算層を分けて、必要な部分だけ増やす」設計にしています。
この手の設計は一見まわりくどいのですが、実は現代のクラウドではかなり自然です。
昔は「DBサーバー=箱そのもの」だったけれど、今はもっと部品化できる。記事はその流れを、DBのど真ん中に持ち込んでいます。
Lakebase の先にあるのが LTAP です。
名前だけ見ると新しい流行語っぽいですが、考え方はわりと筋が通っています。
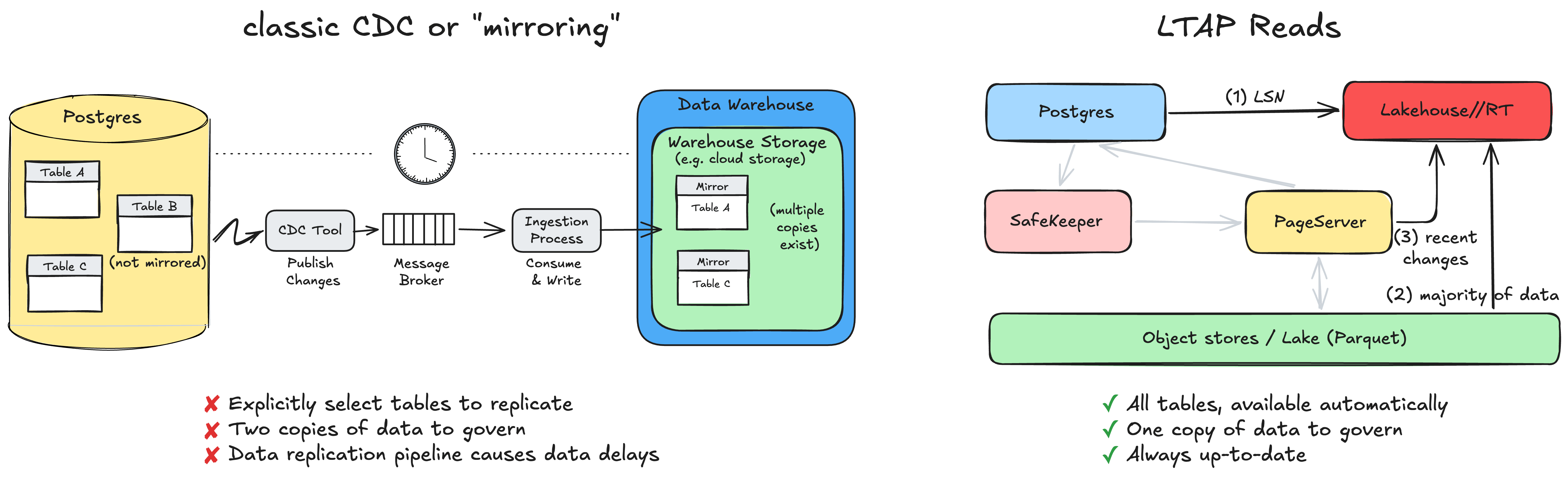
ここでの記事の主張は、transactional data を1回だけ open columnar formats に保存し、その同じデータを Postgres と Lakehouse の両方が読む、というものです。
open columnar formats というのは、列指向の開かれた形式で、分析に向いた保存方法です。列ごとに並んでいるので、集計に強い。
何がうれしいかというと、分析用に別コピーを作らなくてよくなることです。
ふつうは、トランザクションDBのデータを CDC(変更データキャプチャ。更新分だけ別へ流す仕組み)で同期して、分析基盤に“ミラーリング”します。
でもそれって、地味に面倒ですし、遅延もコストも出ます。しかも同期が崩れると面倒くさい。
LTAP はそこを「同じ保存場所を読めばいいじゃないか」に寄せている。
これはかなり強い発想です。分析のためにデータを複製しない。最新の更新をそのまま分析に使う。しかもトランザクション処理の足を引っ張らない。
もし本当にうまく動くなら、運用の面倒さがだいぶ減るはずです。
ここで気になるのが HTAP との違いです。
HTAP は Hybrid Transactional/Analytical Processing の略で、1つのエンジンでトランザクションと分析を両立させようとする考え方です。
一方で LTAP は、エンジンを無理に1つへ寄せません。
保存層を1つにして、Postgres と Lakehouse という得意分野の違う実行エンジンを両方生かす。ここがかなりクールです。
私はこの考え方、わりと好きです。
「全部を1台のスイスアーミーナイフに詰め込む」のではなく、「共有の土台を作って、上は専門家に任せる」感じがあるからです。
現実のシステムって、だいたい何かを一つの魔法で解決しようとして失敗します。LTAP はその罠を避けようとしているように見えます。
このブログが面白いのは、単なる Postgres の新機能紹介ではないところです。
DBをどう速くするか、ではなく、DBをどういう単位で分ければクラウド時代に自然になるかを問い直しています。
昔のDBは、1台の強いマシンにいろいろ詰め込むのが合理的でした。
でも今は、ストレージもコンピュートもネットワークも、クラウド前提で設計し直せる。なら、DBだって monolith のままでいる理由は薄い。
この記事は、その変化をかなり真正面から言語化しています。
個人的には、Lakebase よりも LTAP のほうがさらに野心的だと思います。
Lakebase は「DBをクラウド向けに組み替える」話ですが、LTAP は「その組み替えた結果、トランザクションと分析の境界そのものを再定義する」話だからです。
もし実装と運用が本当にうまくいくなら、分析基盤の作り方はかなり変わるのではないか、と思います。
もちろん、こういう構想は美しいだけでは終わりません。
実運用では、整合性、レイテンシ、障害復旧、ガバナンス、コストなど、気にすべき点が山ほどあります。
それでも、この記事が提示する方向性はかなり筋がいい。DBは“1台の箱”である必要がない、というメッセージは、今後もっと重要になりそうです。
参考: From monolith to Lakebase to LTAP: rethinking the database from storage up
