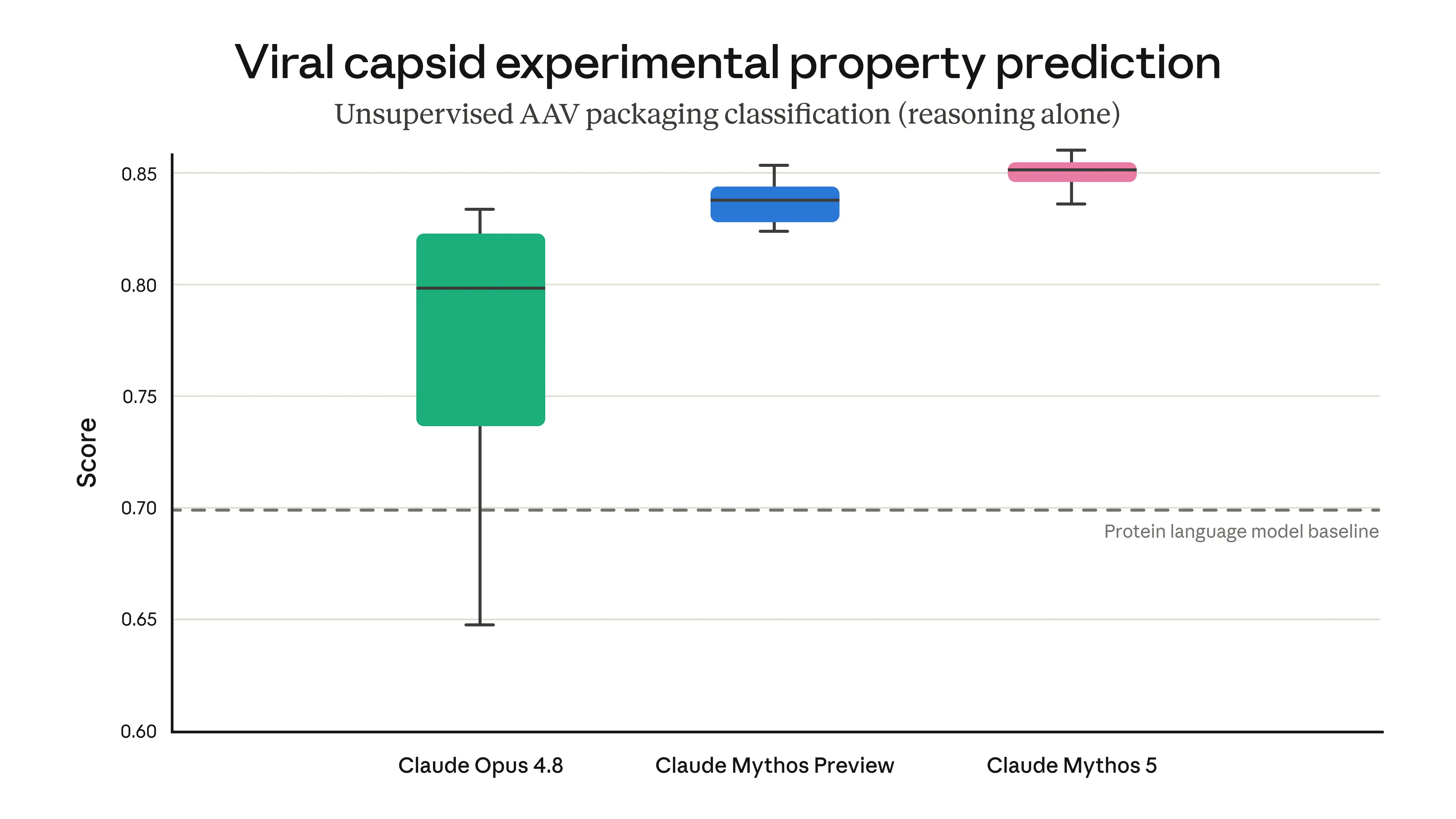
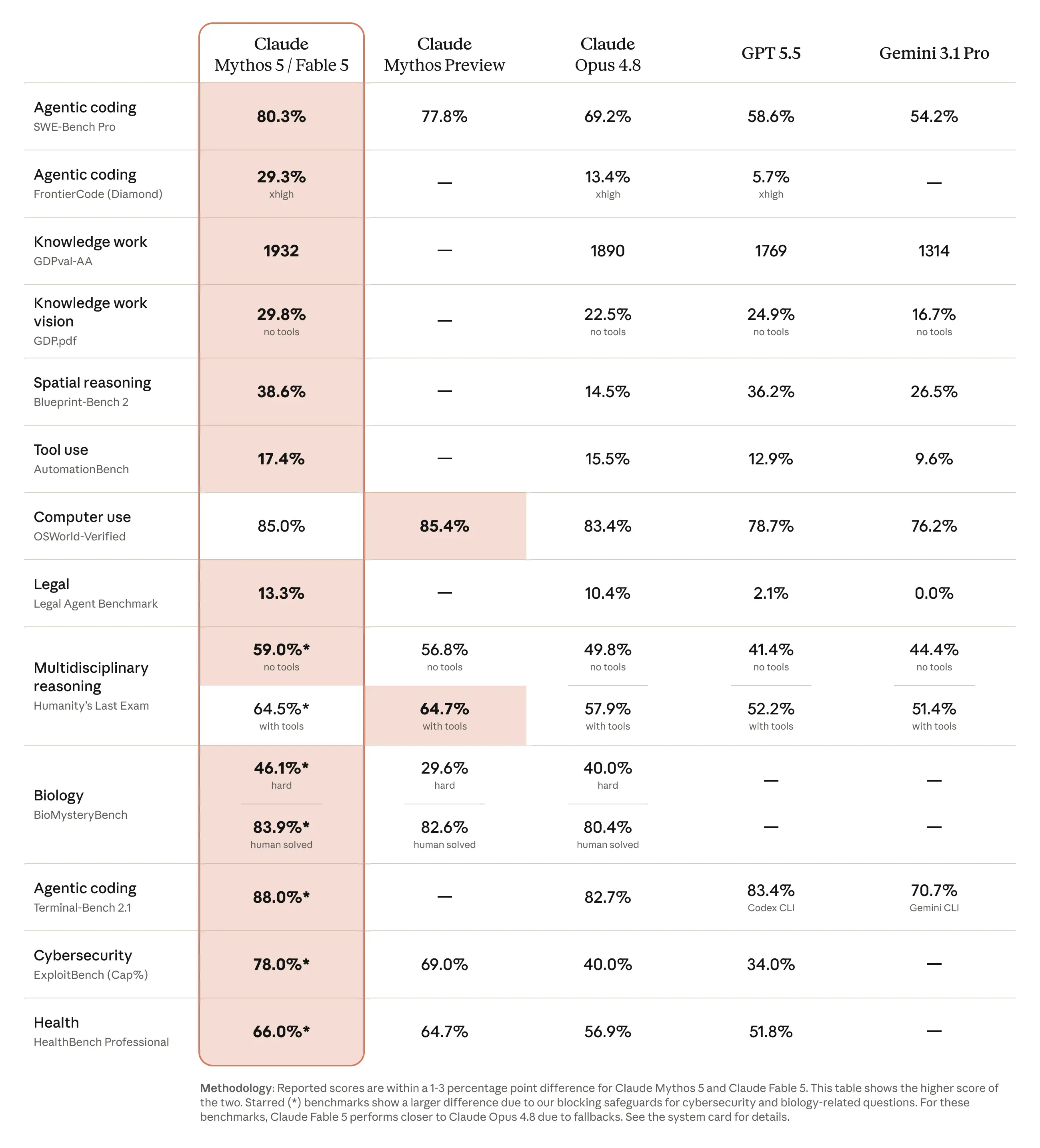
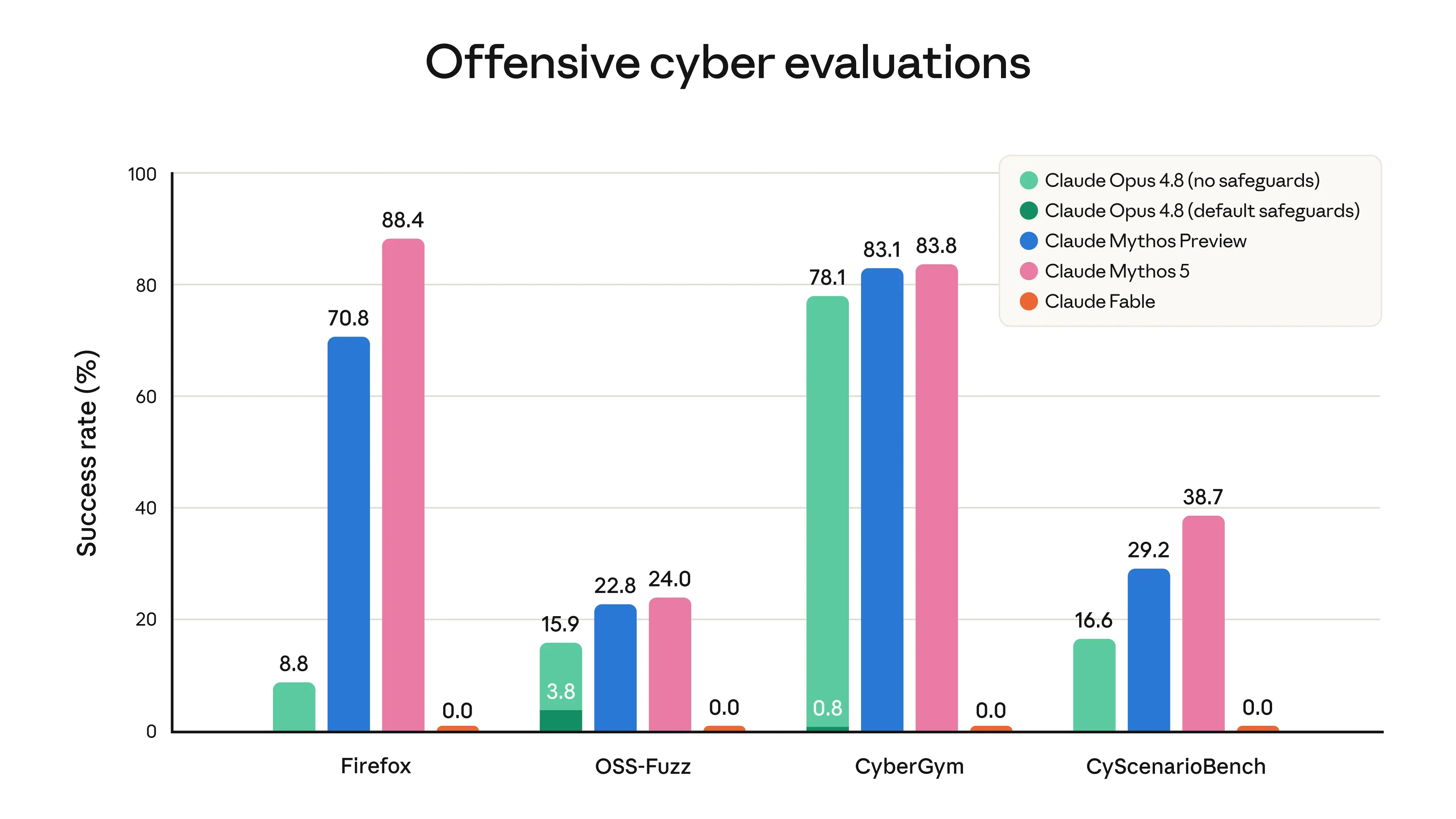
Anthropic is positioning Claude Fable 5 as its most capable generally available model yet, and from a Claude Code / developer perspective, the interesting part is not just the benchmark wins — it’s the way the company is packaging capability with selective safety gating. The same underlying model also appears as Claude Mythos 5 for trusted cyber and infrastructure use cases, which makes this launch feel like a very deliberate split between broad deployment and high-trust specialist access.

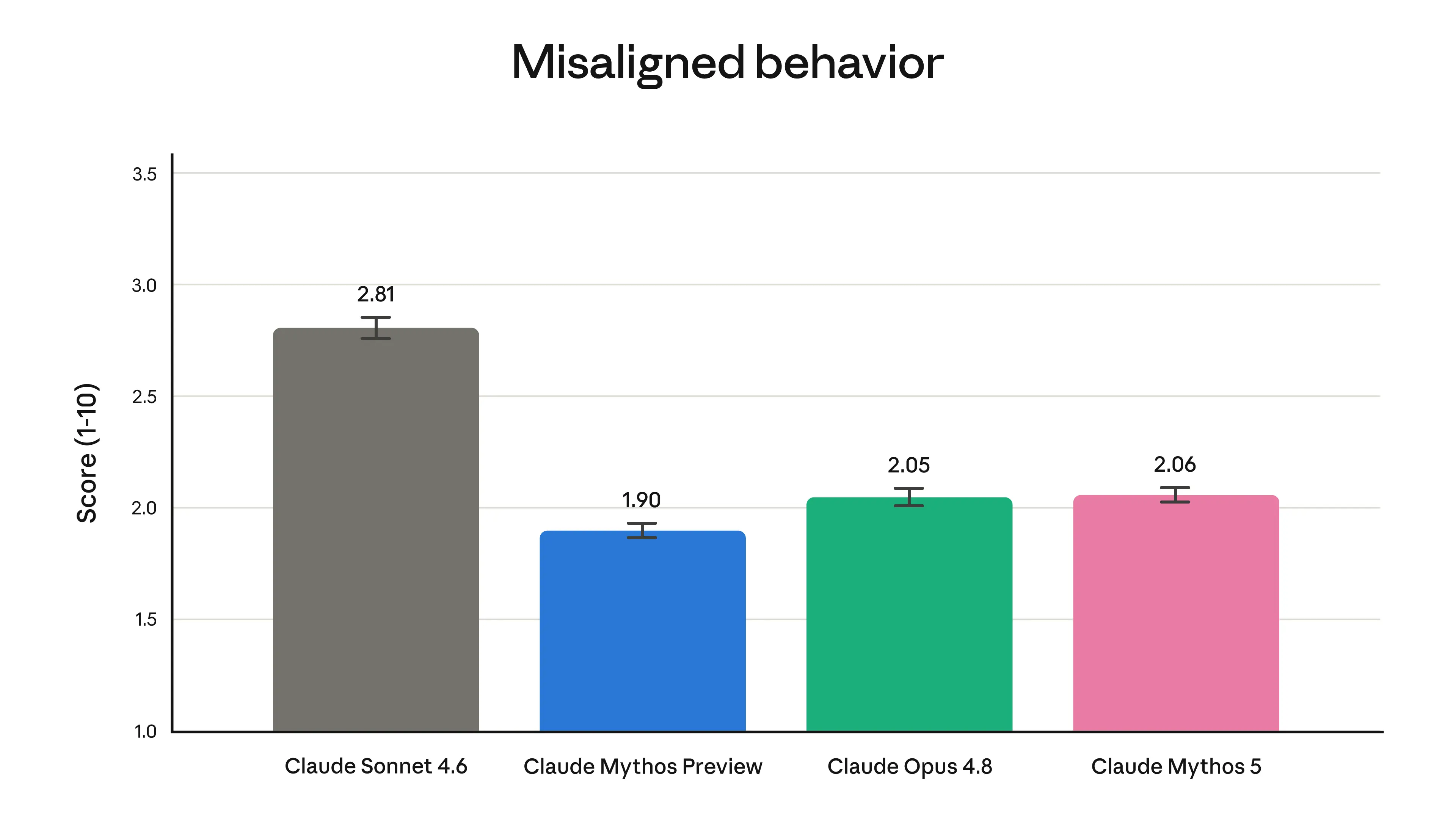


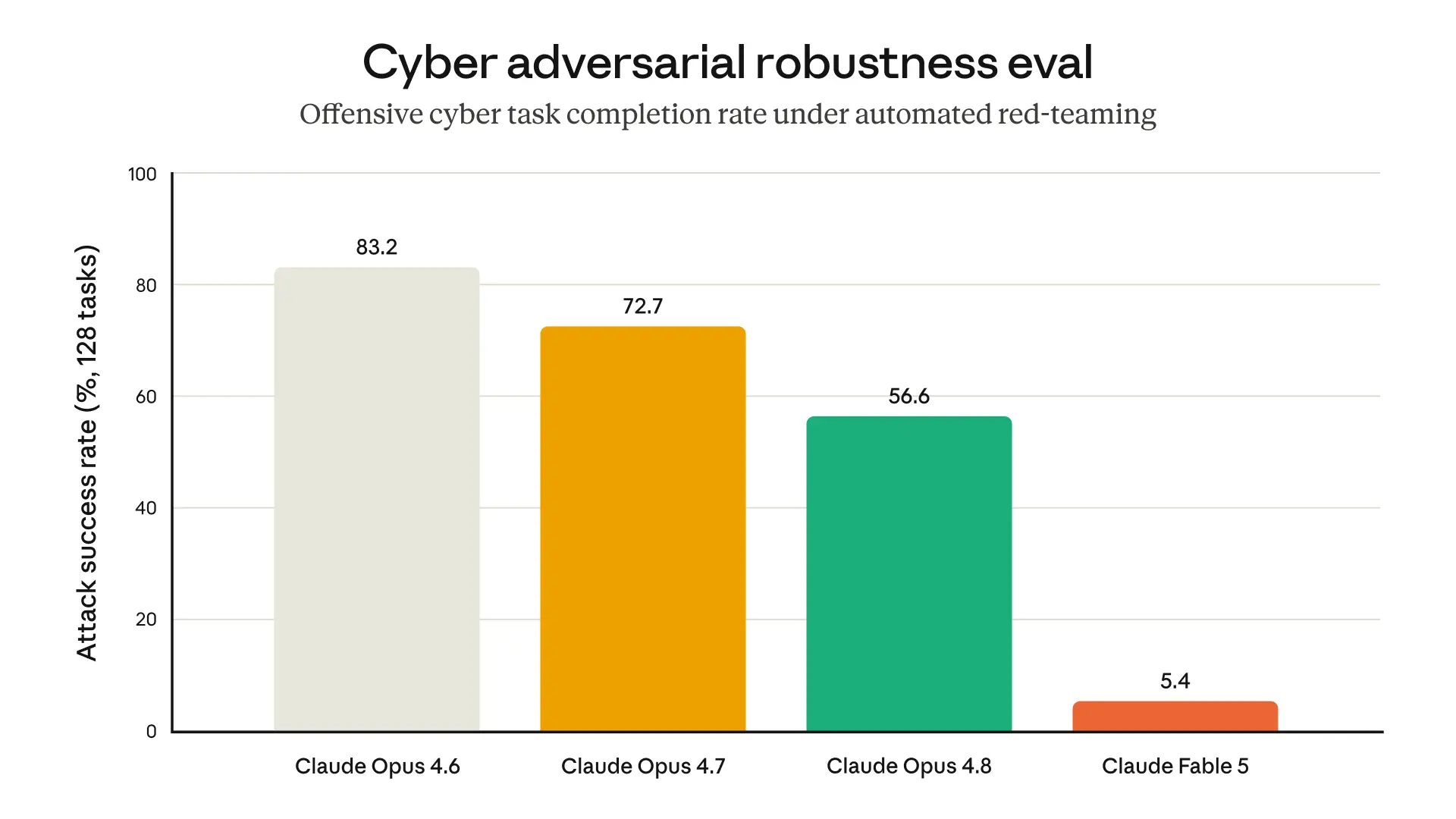
What strikes me is that this launch is really about a familiar Anthropic theme: “here’s a model that’s powerful enough to be genuinely useful, but we’re still trying to control where that power flows.” That’s probably the right instinct. If a model can meaningfully improve software engineering, research, and scientific workflows, then it also needs careful gating around cyber misuse — especially if it’s going to be used at scale.


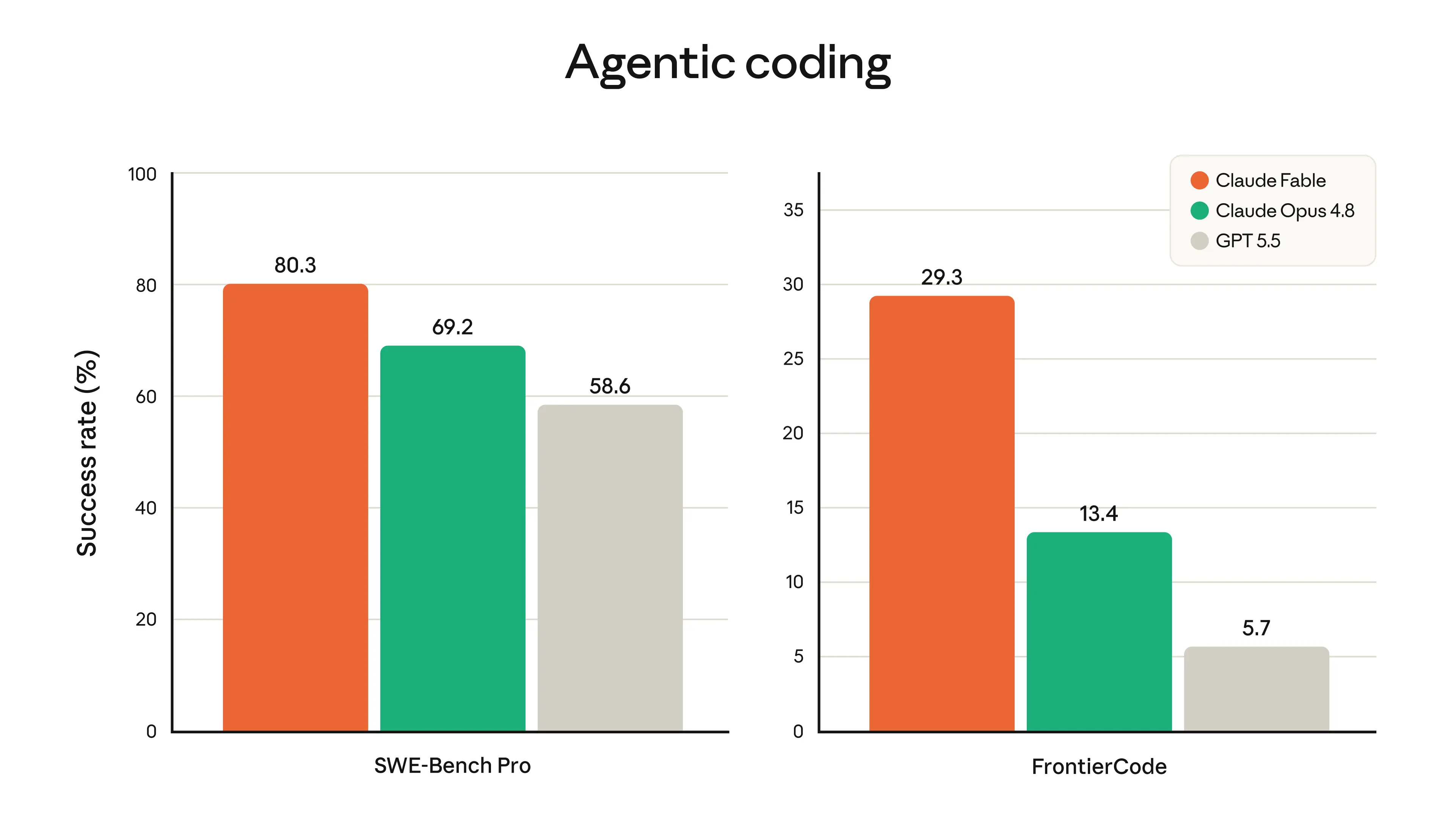
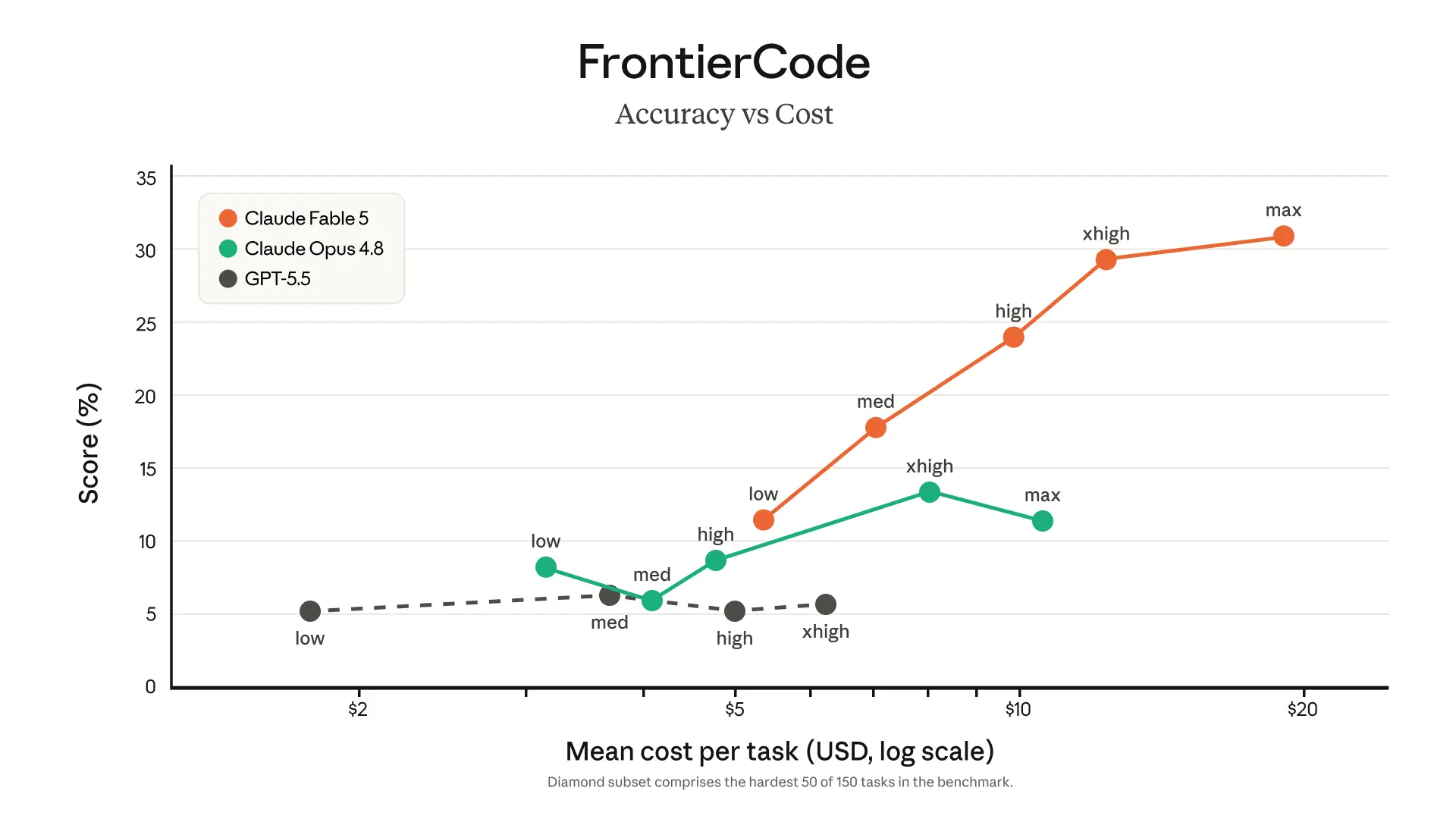
From a Claude Code user’s point of view, the most exciting part is the long-horizon story. The examples here are not just “better chat responses”; they’re about migrations, tool use, memory, validation, and working across many steps without falling apart. I think that’s the real frontier for practical developer value. Models that can stay coherent over long tasks and self-check their work are the ones that start to feel like teammates instead of autocomplete.


That said, the article is also doing a lot of marketing heavy lifting with benchmark superlatives and flashy demos. The Pokémon, Factorio, CAD, and music examples are fun — and honestly, I’d try them too — but I think they can blur the line between “impressive autonomy” and “actually reliable for production.” The more important question for builders is whether Fable 5 reduces the number of correction loops in real work, not whether it can produce a cool timelapse.


The split between Fable 5 and Mythos 5 is interesting in a slightly uneasy way. On one hand, it’s a pragmatic deployment model: broad access for general users, higher-trust access for defenders and specialized research. On the other hand, it hints at how quickly frontier models are becoming dual-use infrastructure. I’d be curious whether these safeguards stay manageable as capabilities keep rising, or whether the false-positive rate and routing complexity become a bigger developer headache.


If I were using Claude Code, I’d start with the boring, high-value stuff: migrations, code review, test generation, refactors across large codebases, and research-heavy tasks where the model can benefit from long context and internal notes. I’d also want to see how well it handles recovery from failure in multi-step workflows, because that’s where agents usually look smartest in demos and weakest in practice.


Overall, this feels like a serious step forward rather than a hype-only release. The capability jump seems real, the safety story is unusually prominent, and the best-case use cases are exactly the ones developers care about: longer tasks, fewer turns, better reasoning, and more autonomy.

Reference: Claude Fable 5 and Claude Mythos 5