この記事でいちばん引っかかるのは、画像生成器の中身です。
Un-0 は Transformer や diffusion の延長線上にあるのではなく、振動子が互いに影響し合う物理システム を計算の本体にしています。

振動子というのは、たとえばメトロノームみたいなものだと思うとわかりやすいです。1個なら勝手に一定のリズムで動くだけですが、2個、3個と並べて同じ台に置くと、振動が少しずつ干渉し合います。うまく噛み合うと同期するし、逆に反対向きに揃うこともある。Un-0 はこの性質を、何千、何万という数にスケールさせて使っています。
正直、この発想はかなり好きです。
AI を「ニューラルネットのサイズ競争」から少し外して、そもそも計算とは何か を問い直している感じがあるからです。最近のAIはどうしても「より大きいGPUで、より大きいモデルを回す」方向に寄りがちですが、この論文はそこに真正面から逆らっています。

Un-0 の基礎になっているのは Kuramoto oscillators です。難しそうに見えますが、要するに「それぞれ自分のリズムを持つ振動子たちが、他人に引っ張られながら動く」仕組みです。
各振動子には位相 θ があり、これは円運動のどこにいるか、みたいなものです。
さらに自然な回転速度 ω があって、振動子同士の結びつきは K という行列で表されます。
元記事に出てくる式は、ざっくり言えばこういう意味です。
「自分のペースで回りつつ、他の振動子との差に応じて引っ張られる」。
この“引っ張り合い”の強さを学習して、画像生成に使うわけです。
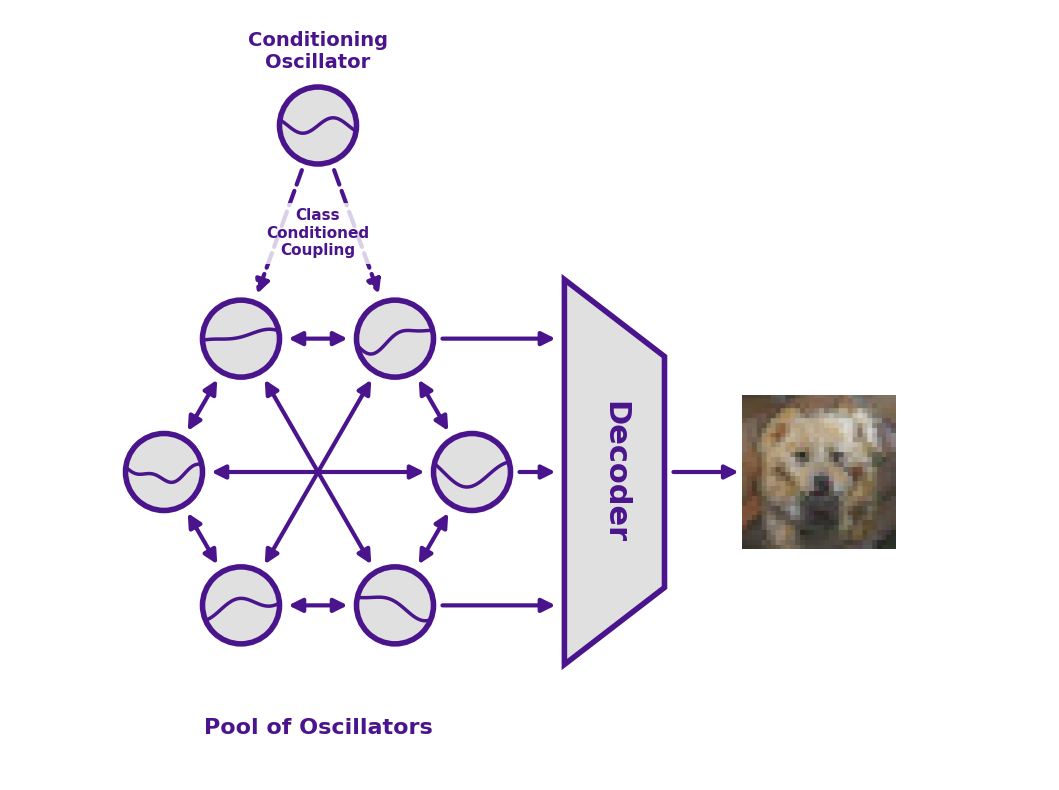
ここで面白いのは、学習される中心が「重み付きの層」ではなく、物理システムのパラメータ になっている点です。ニューラルネットに慣れていると少し不思議ですが、見方を変えると「計算をする材料そのものを訓練している」とも言えます。
Un-0 の生成手順は、意外なくらい筋が通っています。
最初に、すべての振動子の位相をランダムに置きます。これが diffusion でいうノイズのような役割です。
次に、生成したいクラス、たとえば “daisy” や “volcano” を指定します。これは少し小さな振動子群が担当していて、主集団にクラス情報を流し込みます。
そのあと、システムを放っておくと、振動子たちが互いに影響し合いながら時間発展します。
ある時点 T で全振動子の位相をスナップショットとして取り出し、それを latent representation として decoder に渡す。
最後に、その decoder が画像を復元します。
この流れ、かなり詩的です。
乱数から始まって、物理の相互作用で形が決まり、最後に人間が見られる画像になる。
しかも、decoder のパラメータは全体の13%未満 だそうです。主役はあくまで oscillator 側。ここも普通の画像生成モデルとはかなり違います。
著者たちの主張はかなりはっきりしています。
今のAIはGPU上の deep neural networks に依存しているけれど、次のエネルギー効率の飛躍には、物理そのものが計算する新しいコンピュータ が必要だ、と。
この考え方は、単なるロマンではありません。
記事では、neuromorphic computing、Hopfield networks、reservoir computing、Hamiltonian networks、Liquid networks、Thermodynamic computing など、物理や動力学を使う計算の系譜にも触れています。つまりUn-0は突然出てきた変な一発芸ではなく、かなり長い研究の流れの上にあります。
ただ、ここで冷静に見ておきたいのは、「物理で動く」こと自体がすぐ省エネになるわけではない という点です。
Un-0 は現状、シミュレーションとして動いていて、学習にはB200 GPUを複数枚使っています。最大モデルのImageNet 64×64版は 640 B200 hours かかっている。なので、この記事を読んで「もうGPU時代は終わりだ」と受け取るのは早すぎます。
とはいえ、著者たちが狙っているのはそこではないはずです。
彼らがやっているのは、「将来、実際の physical substrate で回せる計算様式」を、まずは難しい画像生成タスクで成立させることだと思います。
この順番はかなり重要で、現実的です。先に“何ができるか”を証明しないと、電力効率の話は絵に描いた餅で終わるからです。
数字の話も大事です。
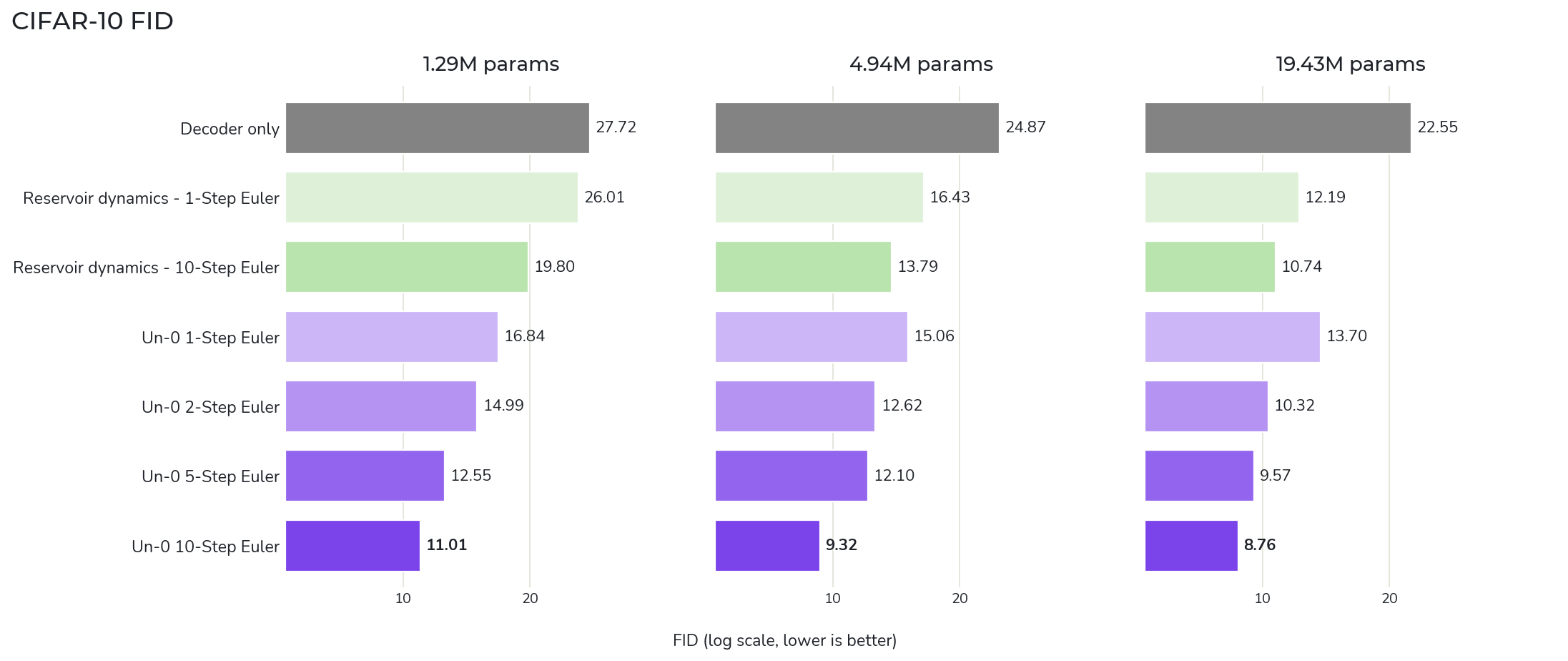
Un-0 は ImageNet 64×64 で FID 6.74 を達成しています。FID は生成画像の品質を測る指標で、ざっくり言うと 実画像っぽさ を見る数字です。小さいほど良い。
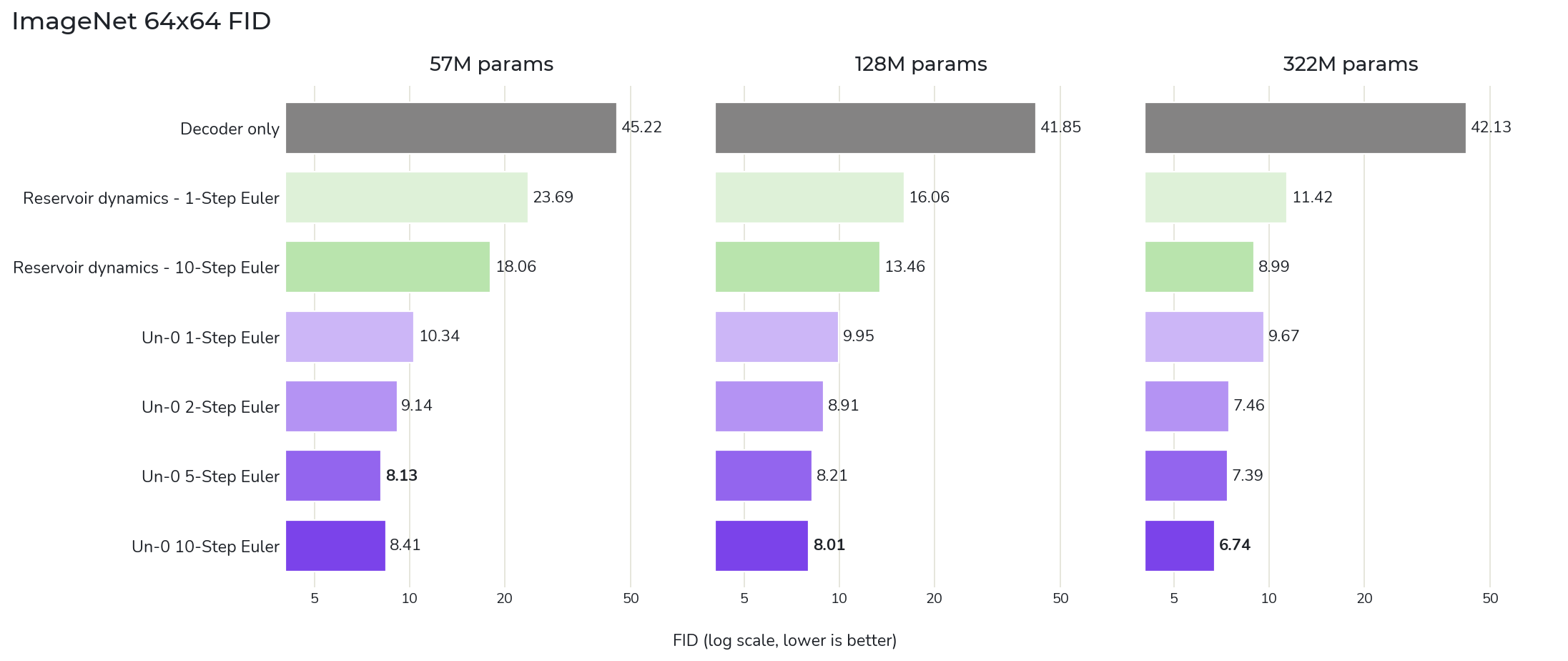
この記事の面白いところは、性能そのものだけでなく、その位置づけ です。著者らは、公開時点での conventional image generation methods の初期公開時の水準に匹敵すると述べています。
つまり、「物理ベースの変わり種」なのに、ちゃんと比較対象になるレベルまで来ている。ここはかなりインパクトがあります。
しかも、weights や training code、ablation code まで open にしている。
こういう研究は、派手な図だけ出して終わると一気に信用が落ちます。だからこそ、再現や検証に必要なものを出しているのは好印象です。個人的には、このオープンさはかなり大きいと思います。研究としてもコミュニティとしても、次の人が乗りやすいからです。
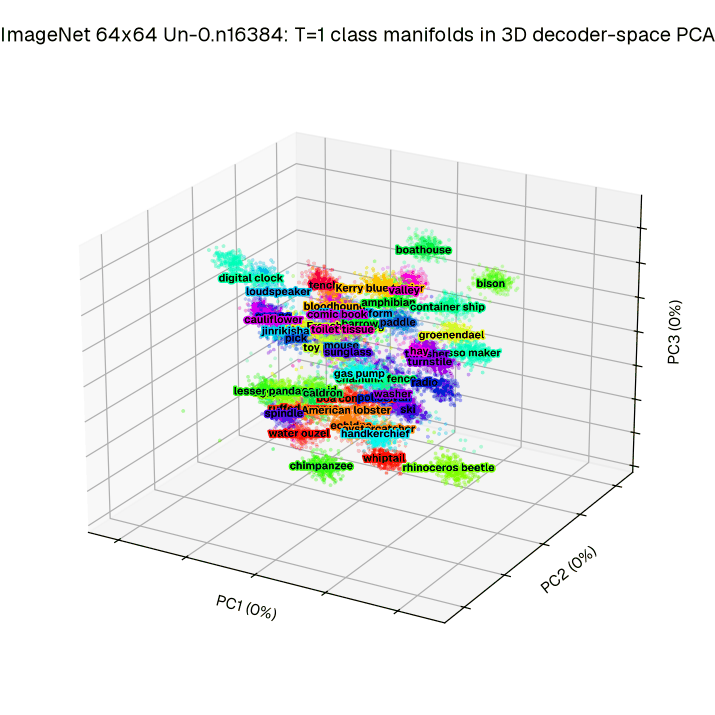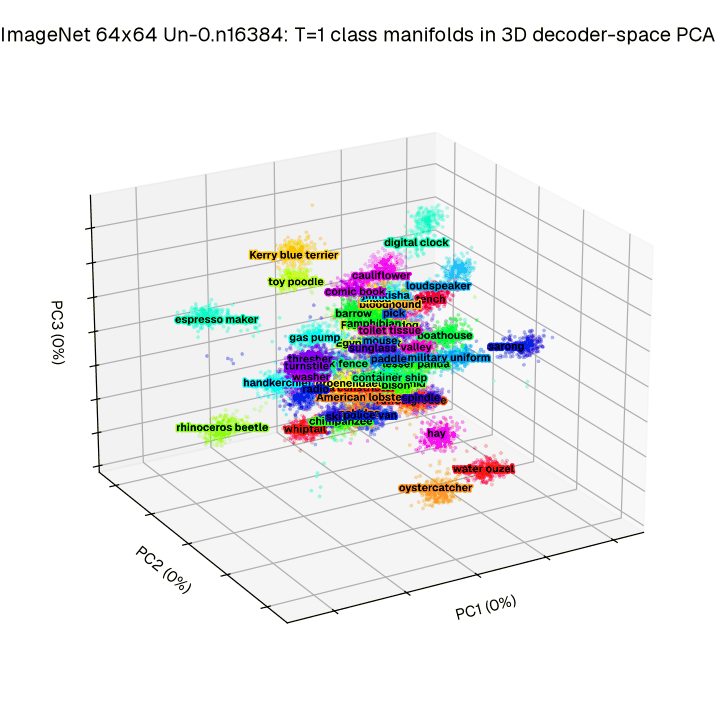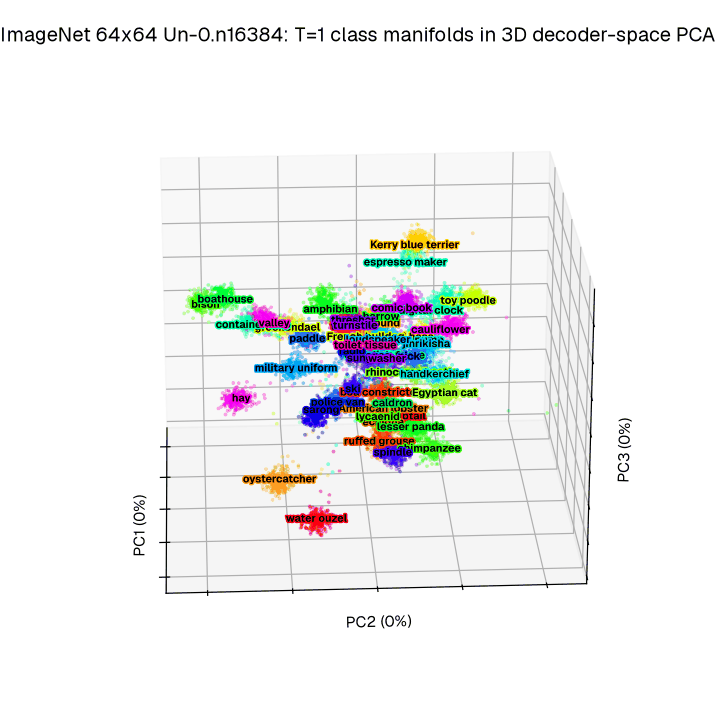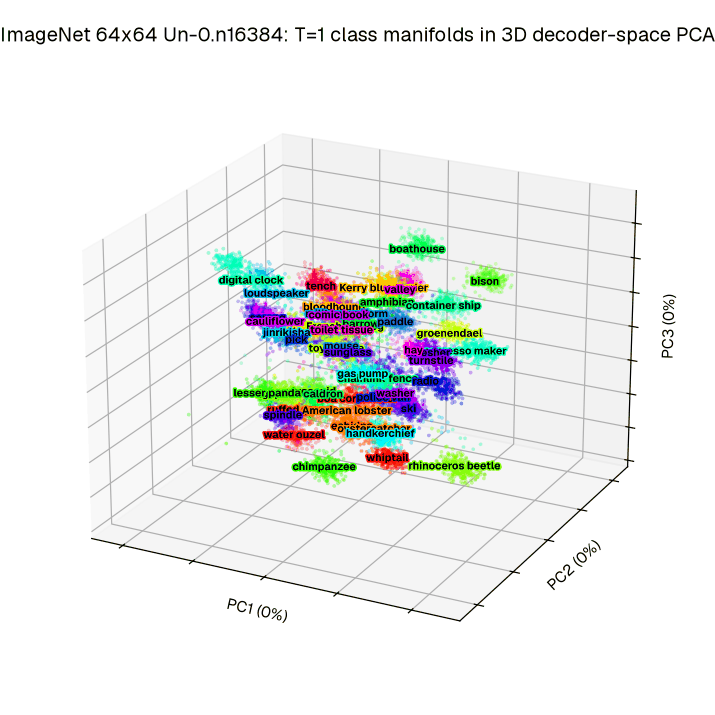
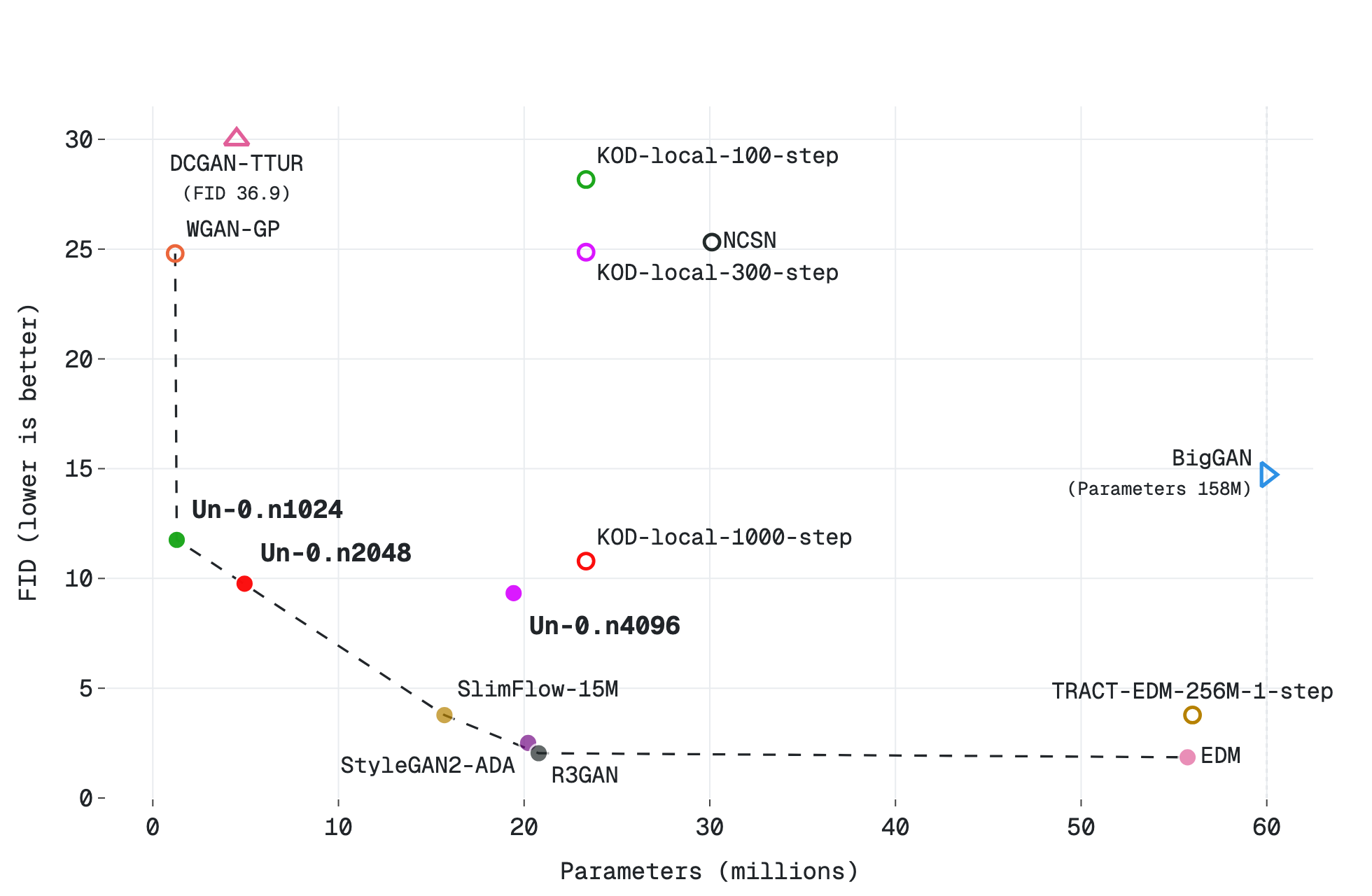
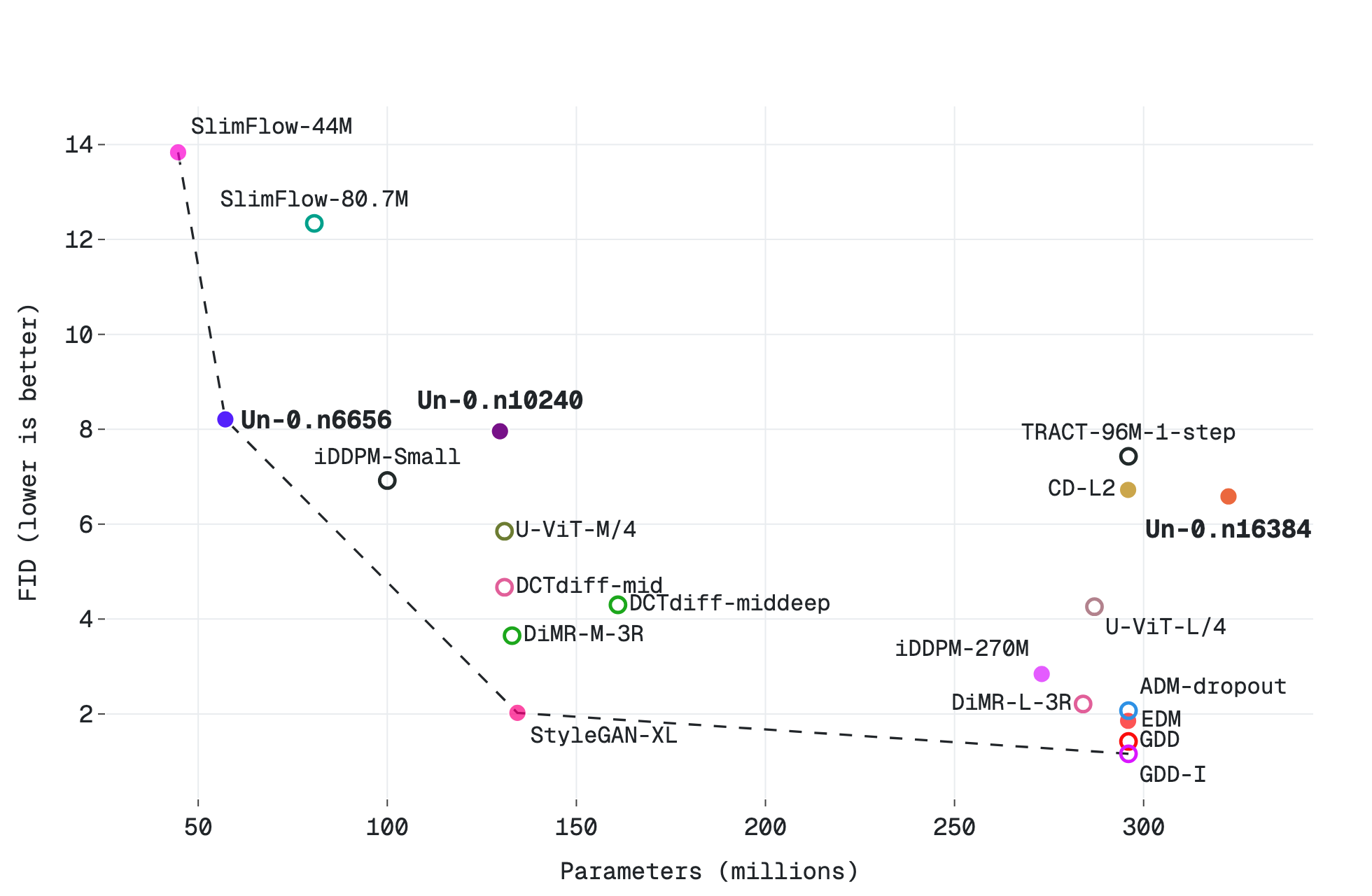
モデル規模を見ると、CIFAR-10 と ImageNet 64×64 で複数サイズを試しています。
ImageNet 側では、oscillator 数が 6656 / 10240 / 16384 のモデルがあり、最大のものが FID 6.74 です。
この表を見ていると、Un-0 は「小さな原理実験」ではなく、大きいモデルとしてちゃんと勝負しにいっている のがわかります。
そこが地味に重要です。新しいアイデアは、小規模デモだと“面白いね”で終わりがちですが、Un-0 は一応、画像生成の本丸に足を突っ込んでいる。
一方で、学習コストのボトルネックは drifting loss の計算だと書かれています。ここには、物理系を使うからといって学習が魔法のように簡単になるわけではない、という現実が見えます。
新しい計算基盤は、たいてい最初は面倒です。面倒だけど、そこを越えた先に面白いものがある。Un-0 はまさにその途中にある感じです。
Un-0 を見ていて一番感じるのは、「完成品」よりも「入口としての強さ」です。
今すぐ実用の王座を取るというより、AI を動かす土台を別のものに置き換えられるかもしれない という可能性を示した点が大きい。
もし本当に将来、物理基板で modern AI を回せるようになれば、計算機の設計思想はかなり変わります。
モデルを大きくする前に、そもそもどういう物理現象に計算を担わせるか、という話になるからです。これはGPU最適化の延長では絶対に出てこない発想です。
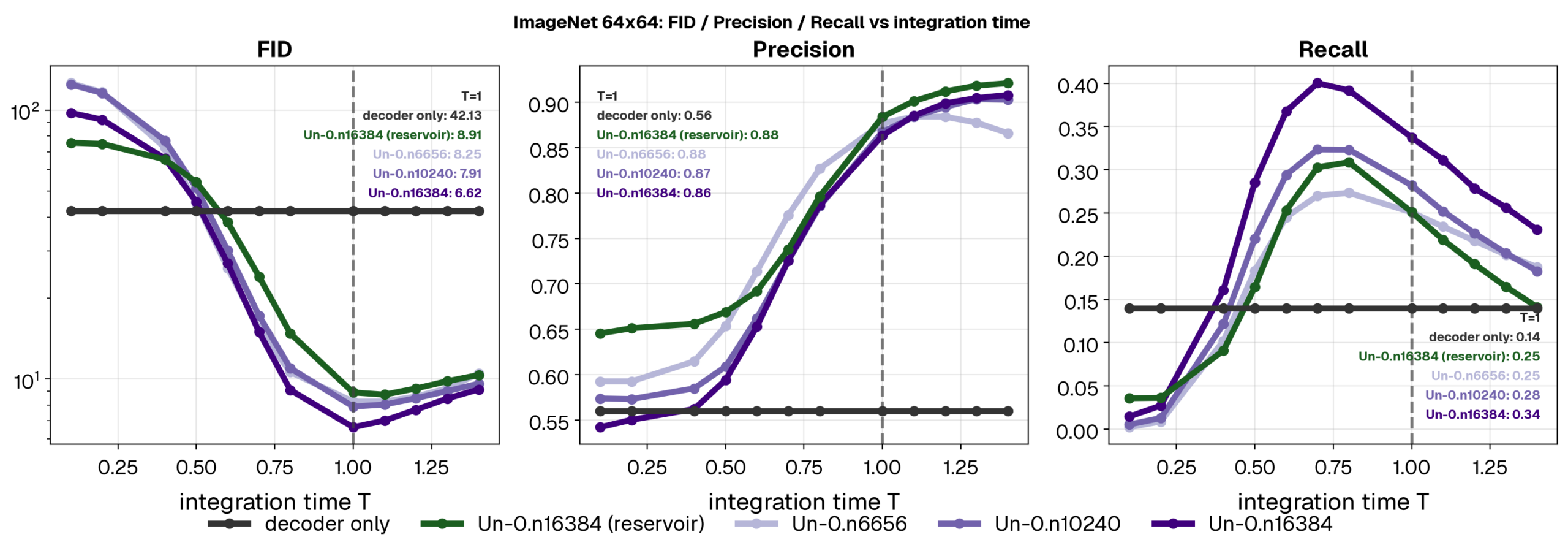
もちろん、まだ道のりは長いです。
シミュレーションで成立したことと、実際のハードウェアで低消費電力に動くことの間には、かなり大きな溝があります。しかも画像生成は、精度も多様性も両方求められる厳しいタスクです。
それでも、こういう研究が出てくるのは素直に楽しい。AIが「巨大な行列計算」だけではない方向に広がっていくのを見るのは、技術好きとしてかなりわくわくします。
参考: Introducing Un-0: Generating Images with Coupled Oscillators
