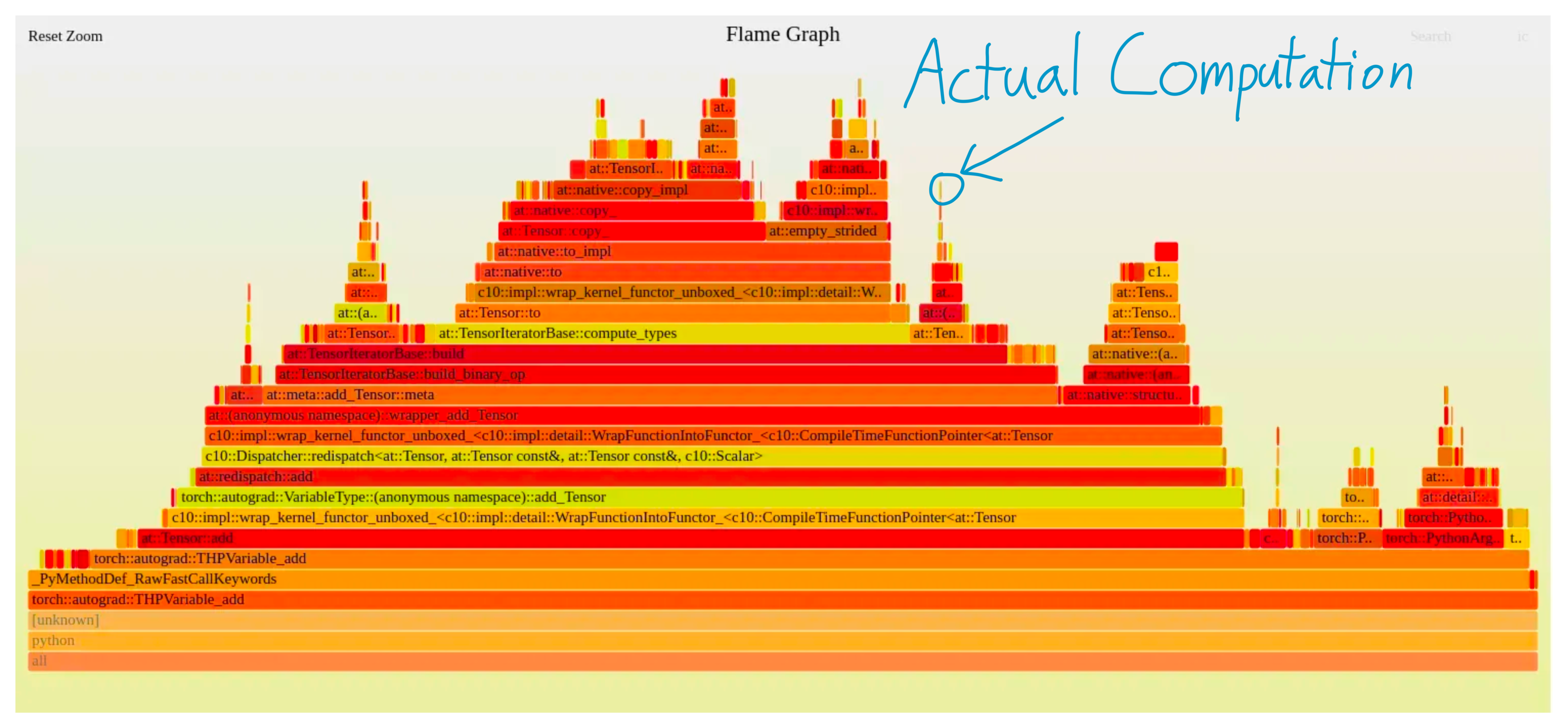
元記事の主張はかなりシンプルです。
深層学習を速くしたいとき、闇雲に「このテクニックが効くらしい」「とりあえず in-place にしよう」みたいな小技を積むのではなく、何に時間を使っているかを第一原理で分解して考えよう、という話です。
ここは個人的にすごく好きなポイントです。
性能チューニングって、経験則が強すぎて魔術っぽく見えがちなんですよね。でも著者はそこに対して、「いや、まずは大きく3分類しようよ」と言ってくる。こういう整理の仕方は、地味だけど本当に強いと思います。
記事では、深層学習システムの効率を次の3要素に分けます。

この切り分けが重要なのは、ボトルネックが違えば効く対策も違うからです。
たとえば、
要するに、「どこが詰まっているのか」を見ないまま最適化すると、だいたい空振りします。
これは深層学習に限らず、あらゆる性能改善で大事な考え方ではないでしょうか。
著者はまず Compute を重視します。理由はわりと単純で、計算そのものは減らしにくいからです。
ここで面白いのが、現代GPUはただの汎用計算機ではなく、行列積(matrix multiplication)専用にかなり寄った設計になっていることです。
NVIDIAの Tensor Cores のように、行列積を速くするための特殊なハードウェアが積まれています。
つまり、GPUは「何でも平均的に速い機械」ではなく、matmul に関してだけめちゃくちゃ強い機械なんですね。
逆に言うと、matmul 以外の演算を雑に扱うと、GPUの旨味をかなり取りこぼします。
とはいえ、記事では「非matmul演算が多いから大問題」という話にはしていません。
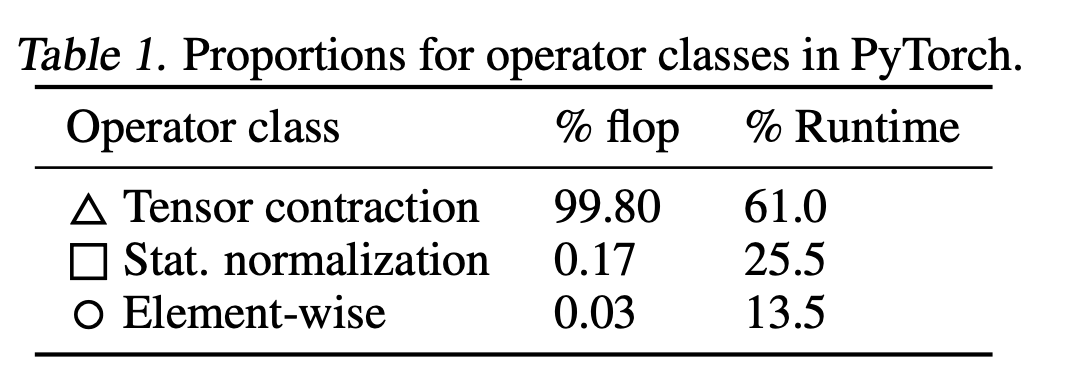
なぜなら、BERT などのモデルでは、全FLOPSのうち非matmulの比率はかなり小さいからです。記事内で引用されている例では、非matmul系は全体のごく一部で、計算量の主役はやはり matmul です。
ここは大事で、
「見た目では小さな演算がいっぱいある」ことと「計算量の大半を占める」ことは別なんですよね。
深層学習では、少数の大きなmatmulが支配的、という構図がよくあります。
計算量が小さいのに遅い。
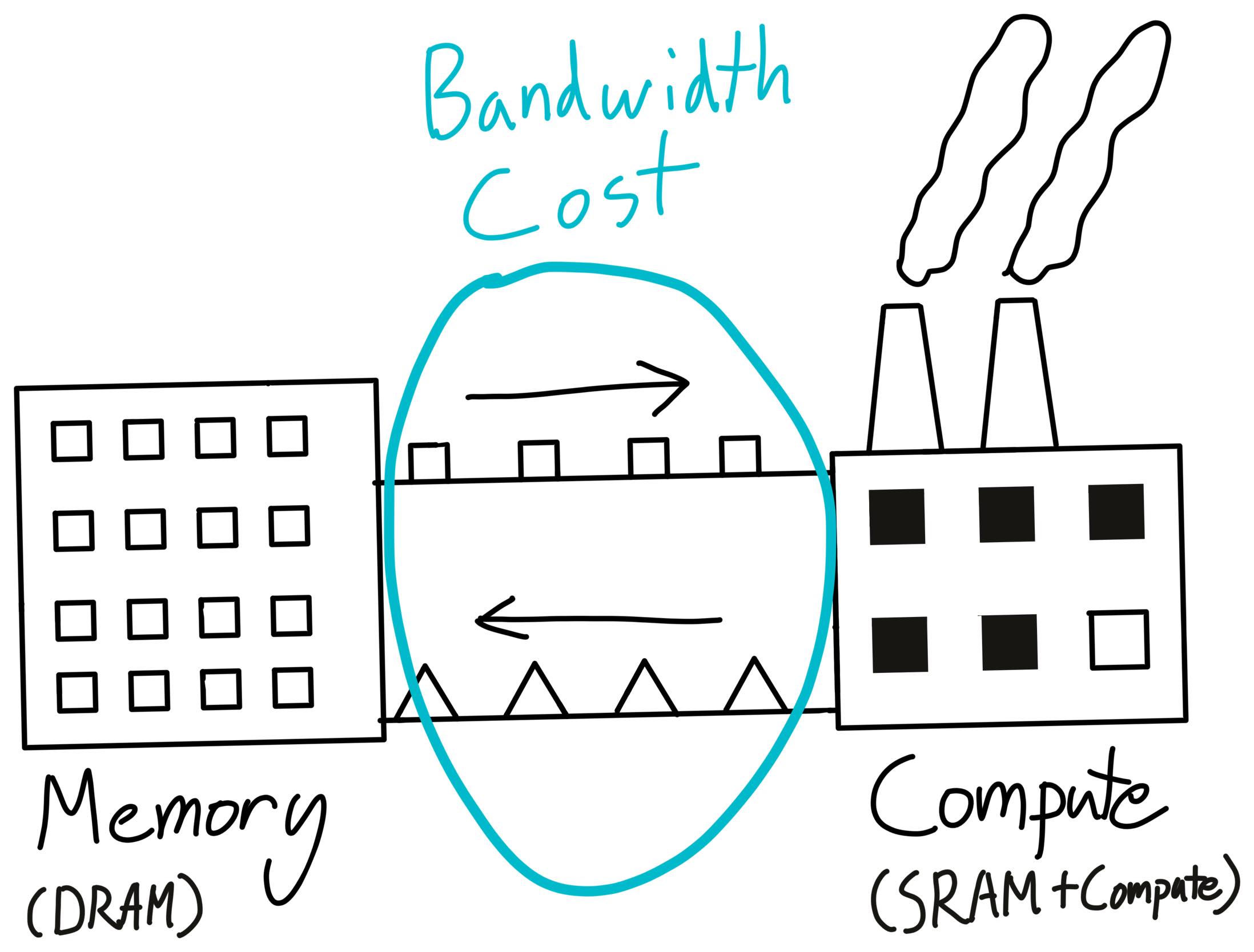
この違和感の原因として記事が挙げるのが memory bandwidth です。
ざっくり言うと、データをどれだけ速く運べるかです。
工場のたとえでいうと、
GPUの中で計算するとき、データは常にどこかから持ってきて、どこかへ戻さないといけません。
しかもGPUでは、演算ユニットよりも、データ移動のほうが高くつく場面がかなりあります。
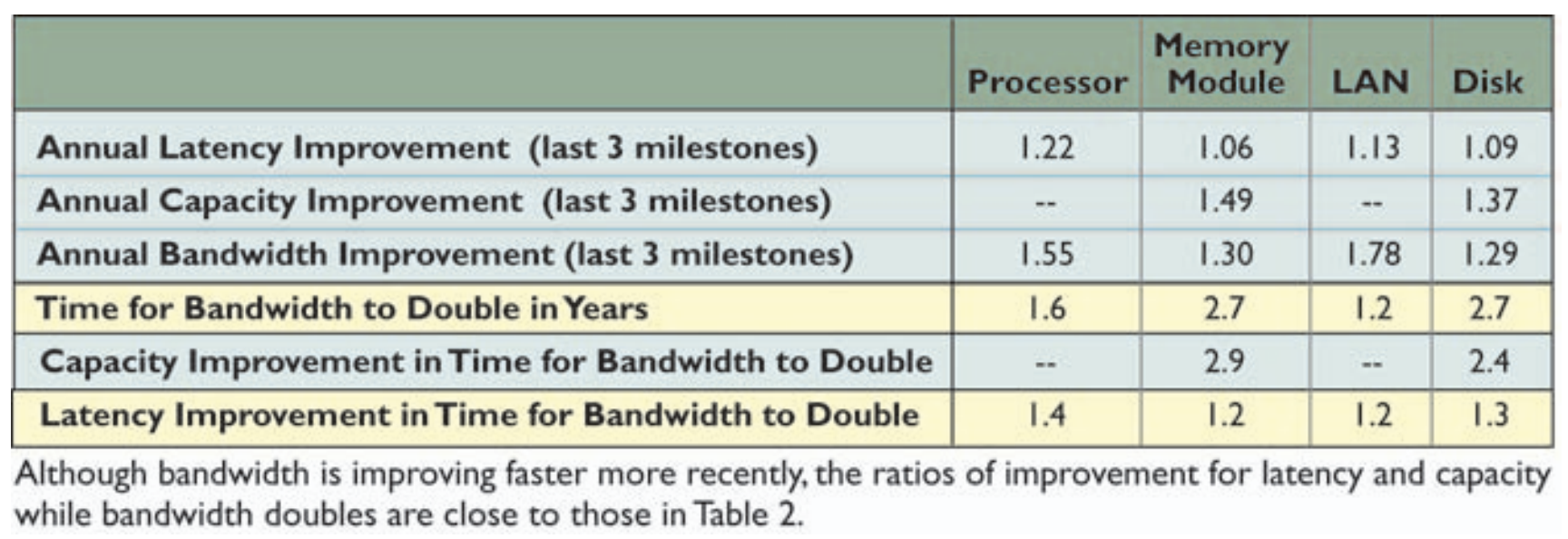
著者はここで、GPUの高速な計算部分を工場、DRAMを倉庫に例えています。
この比喩はかなりわかりやすいです。工場がどれだけ巨大でも、材料が倉庫から来なければ働けません。
つまり、材料供給が追いつかないと工場はフル稼働できないわけです。
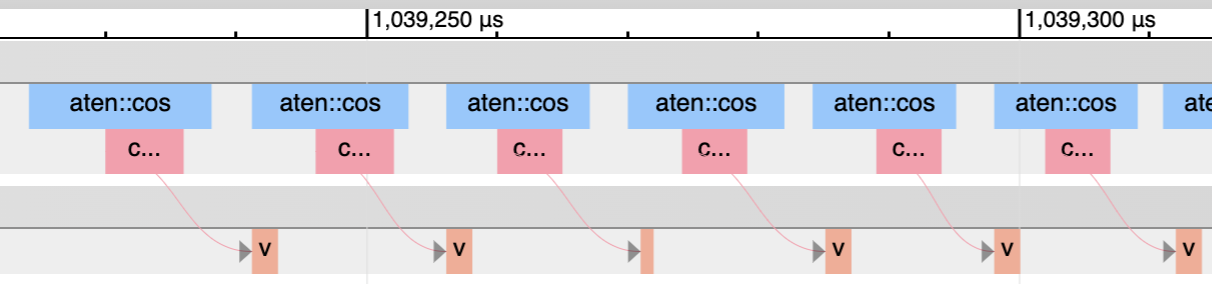
たとえば torch.cos のような unary operation(入力1つの演算)を考えます。
これは計算自体は軽いのに、実際には次のような処理が起こります。
この「読む・書く」の往復がけっこう高い。
そのため、計算よりメモリ転送の時間のほうが長くなりやすいのです。
こういう状態を memory-bound と呼びます。
つまり「速くなる余地が計算側ではなく、メモリ側に縛られている」ということです。
個人的には、ここがこの記事のいちばん実務的なポイントだと思います。
「演算は軽いのに遅い」という現象の正体が、だいたいここで説明できるからです。
ではどうするか。
記事の答えは operator fusion です。
これは、複数の演算をまとめて一気に実行し、中間結果をいちいちグローバルメモリに書かないようにする最適化です。
x.cos().cos()普通に書くと、
x を読むcos の結果を書き出すcos の結果を書き出すという感じで、メモリの読み書きが増えます。
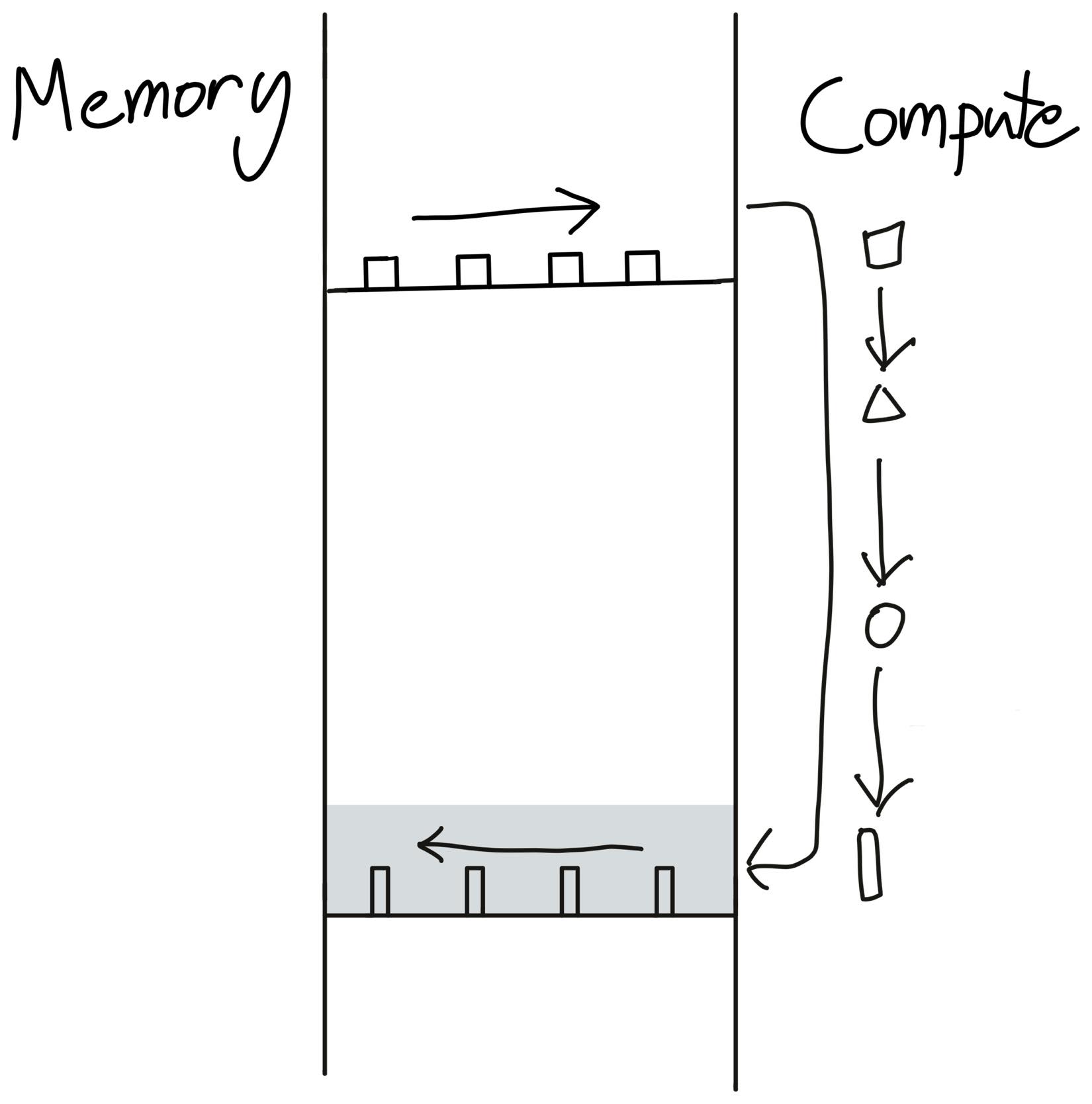
でも fusion できれば、
x を1回読むcos を実行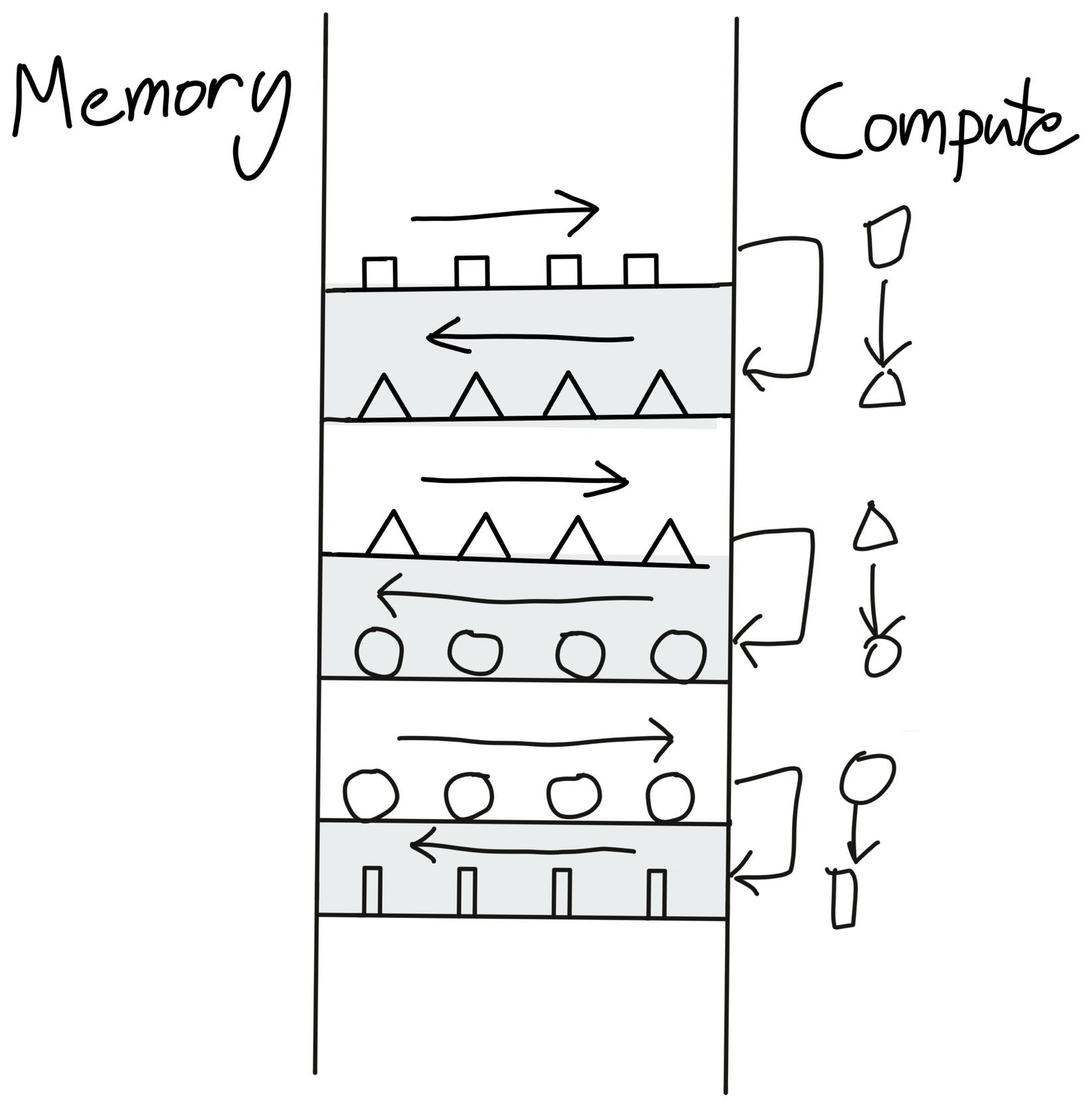
で済みます。
要するに、途中結果をわざわざ倉庫に戻さない。
これはめちゃくちゃ筋がいいです。工場のたとえに戻るなら、途中工程を工場内で完結させるイメージですね。
ここ、地味に面白いです。
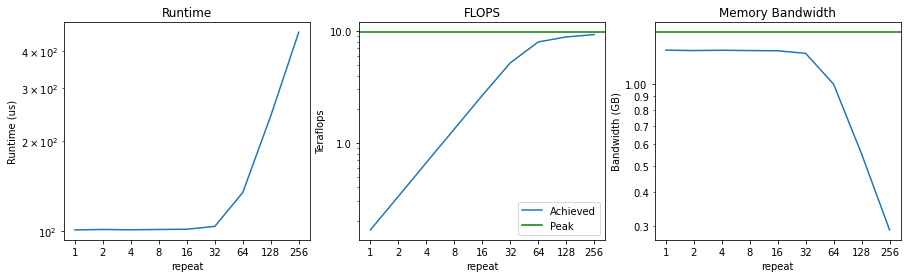
gelu は relu より計算が複雑に見えます。普通に考えると gelu のほうが遅そうですよね。
でも実際には、fusion された状態だと、かなり近い時間で終わることが多い。
理由はシンプルで、こうした演算はだいたい メモリ帯域のほうが支配的だからです。
つまり、
演算の数が少し増えても、ボトルネックがメモリにある限り、全体時間はあまり変わらない。
これは直感に反しやすいけれど、かなり重要な話です。
記事では、operator fusion にも注意点があると述べています。
また、fusion は pointwise op だけの話ではありません。
reduction や matmul との組み合わせでも有効です。
ここで記事が示すのは、deep learning compiler の本質は operator fusion にあるという見方です。
NVFuser や XLA などのコンパイラは、こうした単純なfusionを自動でやります。
それでも、著者は「人間の工夫はまだ強い」と言っていて、Triton のようなツールで自前の kernel を書く価値にも触れています。
このあたり、かなり“現場感”がある主張だと思います。
自動最適化は強いけれど、定番パターンを超えると、まだ人間が一歩先を行ける余地がある。そんなニュアンスです。
普通、「再計算」は無駄に見えます。
でも記事では、recomputation / activation checkpointing によって、むしろ速くなる場合があると説明します。
理由は、再計算しても中間結果を保存するよりメモリ帯域の消費が減るからです。
つまり、
という逆転現象です。
これはかなり面白い発想です。
「計算を減らすのが最適化」という思い込みを壊してくれるからです。
深層学習では、計算よりメモリが高いことが普通にあるので、再計算が得になる場面があるわけですね。
記事は最後のほうで、ざっくりした見積もりの大切さにも触れています。
たとえば A100 のようなGPUでは、
といった比較ができます。
これを使うと、何個の数値を運ぶ時間で、どれだけの演算ができるかをざっくり見積もれます。
その結果、単純な unary op では、かなり多くの演算を詰め込まないと、メモリアクセスのほうが支配的になりやすいことがわかります。
この「計算機で概算してみる」態度は、実務でとても大事だと思います。
最適化って、感覚でやると沼に落ちやすい。
でも、ざっくりした数字を置くだけで「何を頑張るべきか」が見えてくることは多いです。

元記事のメッセージを一言でまとめるなら、たぶんこうです。
深層学習の高速化は、GPUを気合で速くする話ではなく、
Compute / Memory / Overhead のどれが詰まっているかを見極めて、そこに効く手を打つ話である。
この考え方は、とても地味です。
でも、地味だからこそ強い。
派手な小技より先に、まず「今の自分のモデルはどの瓶の首で詰まっているのか」を見る。これだけで無駄撃ちがかなり減るはずです。
個人的には、この記事は「GPU最適化の入門」であると同時に、性能問題にどう向き合うべきかの哲学を教えてくれる文章でもあると思いました。
“Brrrr” というタイトルは冗談っぽいですが、中身はかなり真面目で、しかも実戦的です。
