Liquid AIが新しく公開したのは、LFM2.5-8B-A1B というモデルです。
ざっくり言うと、スマホやノートPCのような手元の機械で、なるべく速く、なるべく賢く動くAI を目指したモデルです。
ここでのポイントは「8B」という数字です。これはモデルの規模感を表していて、一般には大きいほど賢くなりやすいが、動かすのに重いという傾向があります。
ただしこのモデルは単純な巨大モデルではなく、Mixture-of-Experts(MoE) という方式を使っています。これは、全部の脳みそを毎回フル稼働させるのではなく、必要な専門家だけを呼び出すような仕組みです。私はこの考え方、かなり筋がいいと思っています。端末AIの世界では「賢さ」と「軽さ」を両立するのが命なので、MoEは相性がいいんですよね。
Liquid AIはこのモデルを、consumer hardware(一般向けのPCや端末)で高速かつ安定して tool calling をこなすことに最適化した、と説明しています。
tool calling というのは、AIが検索、計算、外部API呼び出しなどの“道具”を使いながらタスクを進めることです。いまのAIエージェントにはかなり重要な能力です。
今回のモデルは、前の LFM2-8B-A1B を大きく強化したものです。主な変更点は次のとおりです。
この中でも、地味だけど効きそうなのがtokenizerの改善です。
tokenizer は、文章をモデルが扱える単位に分解する仕組みです。日本語やタイ語、アラビア語のように、英語と文字の性質が違う言語では、ここが弱いとムダが増えます。
Liquid AIは、トークンを数えたときの効率がかなり上がったとしています。特に改善が大きかったのは:
このへんの言語で大きく効率が上がっているのは、かなり実用的です。正直、こういう改善はベンチマークの派手さよりも現場で効くことが多いと思います。多言語対応を本気でやるなら、モデル本体だけでなく tokenizer の作り込みがかなり重要なんですよね。
context window は、モデルが一度に参照できる文章量の上限です。
これが 128K というのは、かなり長いです。長文の資料、長い会話ログ、複数ファイルをまたぐ指示、長いエージェント実行履歴などを扱いやすくなります。
Liquid AIは、まず 32K まで伸ばし、その後さらに 128K まで拡張したと説明しています。
この拡張のために、RoPE base θ を増やし、追加の midtraining を行ったとのことです。RoPE は長い文脈の中で位置関係を扱うための仕組みで、ここを調整すると長文対応がしやすくなります。
要するに、「長い話を途中で忘れにくくなった」という理解で大丈夫です。
もちろん魔法ではないので、128K だから無限に賢いわけではありません。ただ、実務ではこの差がかなり大きいはずです。
今回のモデルは reasoning-only model だとされています。
これは、最終回答の前に、内部で「どう考えるか」を明示的に出すタイプの設計です。
この方式は好みが分かれるところですが、Liquid AIは MoE モデルは計算コストを抑えやすいので、reasoning token を増やしても速度を落としにくい という考え方を取っています。
つまり、考える量を増やしても、巨大な dense model よりは軽く済む という発想です。
個人的には、この判断はかなり自然だと思います。
端末AIで重要なのは、単に答えが出ることではなく、途中で変なループに入らず、必要な道具を順番に使い、ちゃんと完走することです。reasoning を強めるのは、そのための王道の一つだと思います。
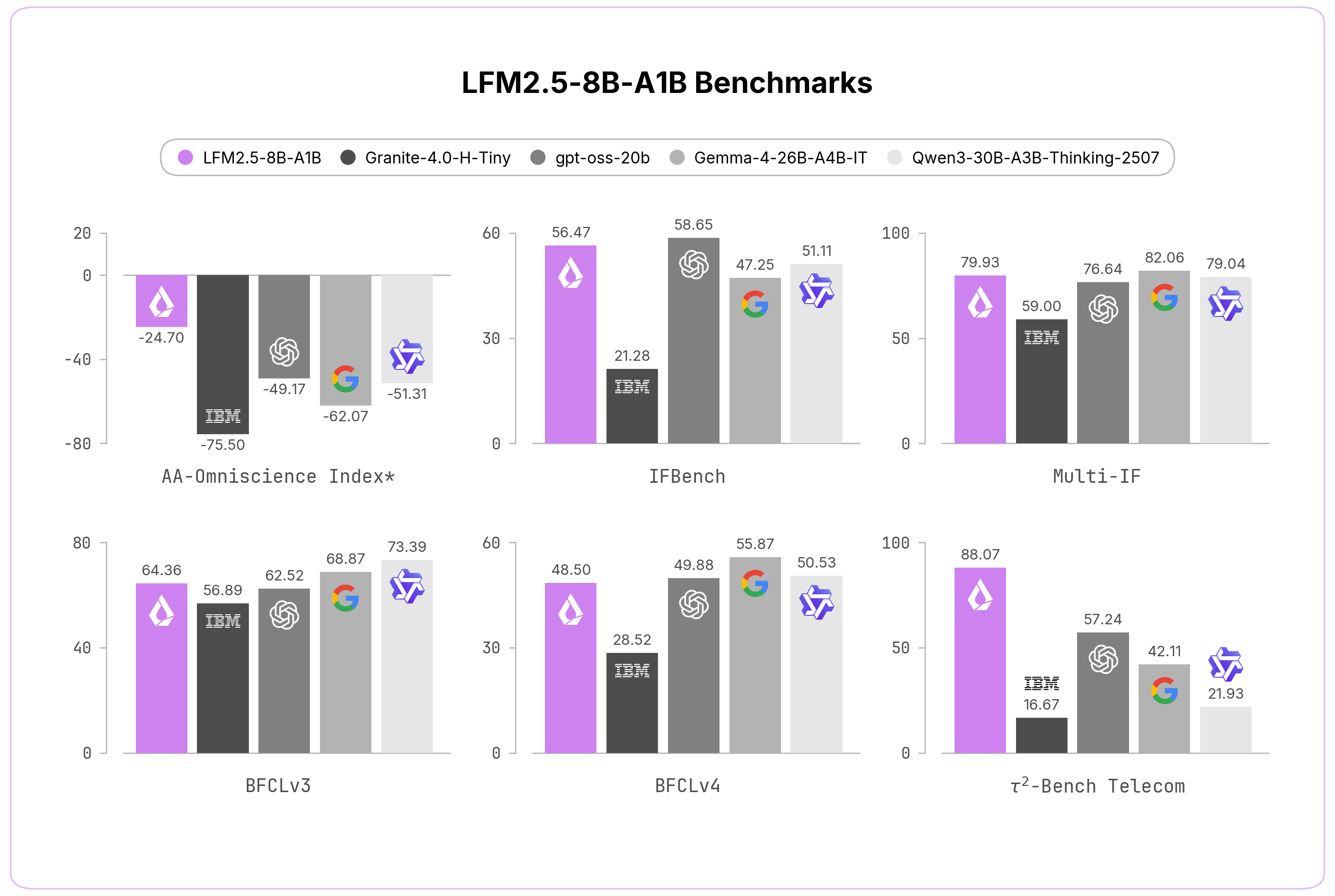
Liquid AIは、以前のモデルと比べて、いくつものベンチマークで大きな改善があったと示しています。特に印象的なのは次のあたりです。
.svg)
とくに Non-Hallucination Rate の改善は目を引きます。
hallucination は、AIがそれっぽいけど間違ったことを自信満々に言ってしまう現象です。ユーザー体験を壊す最大級の要因の一つなので、ここを強く改善しているのはかなり重要です。
AA-Omniscience Index は「正解は加点、幻覚は減点」という指標で、数値が高いほど良いそうです。
今回この値が大きく改善しているのは、単に賢くなっただけでなく、変なことを言いにくくなったという意味合いが強いです。これは実運用ではかなり効きます。
本文の中で面白かったのが、hallucination 対策に targeted RL stage を入れたという部分です。
ここでは、知識が怪しい問いに対しては無理に答えず、「わからない」と言えるように学習させているようです。
さらに、長い reasoning trace でループしやすいトークンを見つけて、そこへの偏りを抑える工夫も入っています。
たとえば “Wait…” みたいな、再開っぽい単語がループの引き金になることがあるので、それを抑えるようにしたとのこと。
これ、地味ですがかなり実戦的です。
AIを使っていてイライラする瞬間って、回答が遅いことよりも、同じことを延々と繰り返すことだったりするんですよね。そういう不快さにちゃんと向き合っているのは好印象です。
このモデルは、単に質問応答をするだけではなく、agentic workflow、つまり「AIが複数ステップを自律的に進める」用途を強く意識しています。
ベンチマークでは、以下のような項目が評価されています。
.png)
特に Tau² Telecom で非常に強い結果を出しているのが目立ちます。
このあたりは「AIが実際の業務フローをどこまでこなせるか」を見る指標なので、単なる知識問題よりもかなり実用寄りです。
つまりこのモデルは、会話がうまいだけのAIではなく、仕事を進めるAI を狙っているわけです。ここはかなり重要な方向性だと思います。
Liquid AIは、day-one support として複数の推論環境への対応を発表しています。
これはかなり大事です。
モデルがどれだけ良くても、実際に使える環境が少ないと普及しません。逆に、最初から主要フレームワークに乗るモデルは、試しやすく、組み込みやすく、現場に入りやすいです。
特に llama.cpp 対応は、端末AIの世界ではかなり強い意味があります。
ノートPCやローカル環境で軽く試せるからです。
Liquid AIによると、このモデルは CPU inference でもかなり速いです。
たとえば、M5 Max で 253 tokens/s、Ryzen AI Max+ 395 で 146 tokens/s を出しつつ、6GB未満で動くとしています。さらに、スマホでも 約30 tokens/s を維持できるとのことです。
この数字が本当なら、かなりインパクトがあります。
“端末で動くAI” は最近よく聞きますが、実際には重くて待たされることも多いです。そこを速さで押してくるのは、かなり好戦的でいいなと思います。

もちろん、ベンチマークの条件や実装次第で体感は変わるので、実機での検証は必要です。
それでも、「ローカルでちゃんと速い」ことを最初から売りにしているのは、競争力としてかなり強いです。
LFM2.5-8B-A1B を一言でいうなら、
「小さいのに、長文・多言語・tool calling・エージェント処理が強く、しかも端末で速く動くモデル」 です。
特に重要なのは、ただ小型化したのではなく、
という、実運用で効く部分をまとめて磨いていることです。
個人的には、このモデルは「ベンチマークで少し強い」だけではなく、ローカルAIの使い勝手そのものを前に進めるタイプだと思います。
いまのAIはクラウド依存がまだ強いですが、こういうモデルが増えると、プライバシーを保ちながら高速に動く個人用AI がかなり現実的になります。そこがすごく面白いところです。
参考: LFM2.5-8B-A1B: an Even Better on-Device Mixture-of-Experts | Liquid AI
