ローカルで動くAIモデルって、ここ数年ずっと「惜しいなあ」が続いていました。速いけど賢さが足りない。賢いけど重すぎる。結局、クラウドのAPIに戻る。そんな空気を、QuesmaのPiotr Migdał氏はQwen 3.6 27Bでかなり変わったと感じたようです。
この記事の面白さは、単に「新しいモデルがすごい」で終わらないところです。MacBookやNvidia RTXのような手元のマシンで、実際にコードを書かせたり、ページを作らせたりできる。しかも、ただ動くのではなく、そこそこちゃんと使える。ここが本質だと思います。ローカルAIは長いあいだ「ロマンはあるけど実用は…」という立ち位置でしたが、Qwen 3.6 27Bはその壁をかなり押し下げた、というのが記事の主張です。

著者は以前、ローカルモデルにがっかりしていたと書いています。これ、わかる人はかなり多いはずです。いざ試してみると、文章はそれっぽいけどコーディングでは抜けが多い。指示を無視する。出力が雑。結局、クラウドの強いモデルに戻る。ローカルで動く意味はあるのか、となるわけです。
そこに来てQwen 3.6 27Bは、「一般知能っぽく」使えると感じた、とかなり強めに評価されています。ここは少し大げさにも聞こえますが、文脈としては「単なるデモ用モデルではなく、日常の開発に混ぜられるレベル」という意味合いだと思って読むと腑に落ちます。
![]()
しかもこのモデル、著者の言い方では「マシンを熱くする」。要するに、ちゃんとパワーを食う。でも、そのぶん見返りがある。ローカルAIの世界では、ここがいちばん重要です。軽いだけでは意味がなくて、重くても役に立つなら価値がある。かなり身もふたもない話ですが、結局そこです。
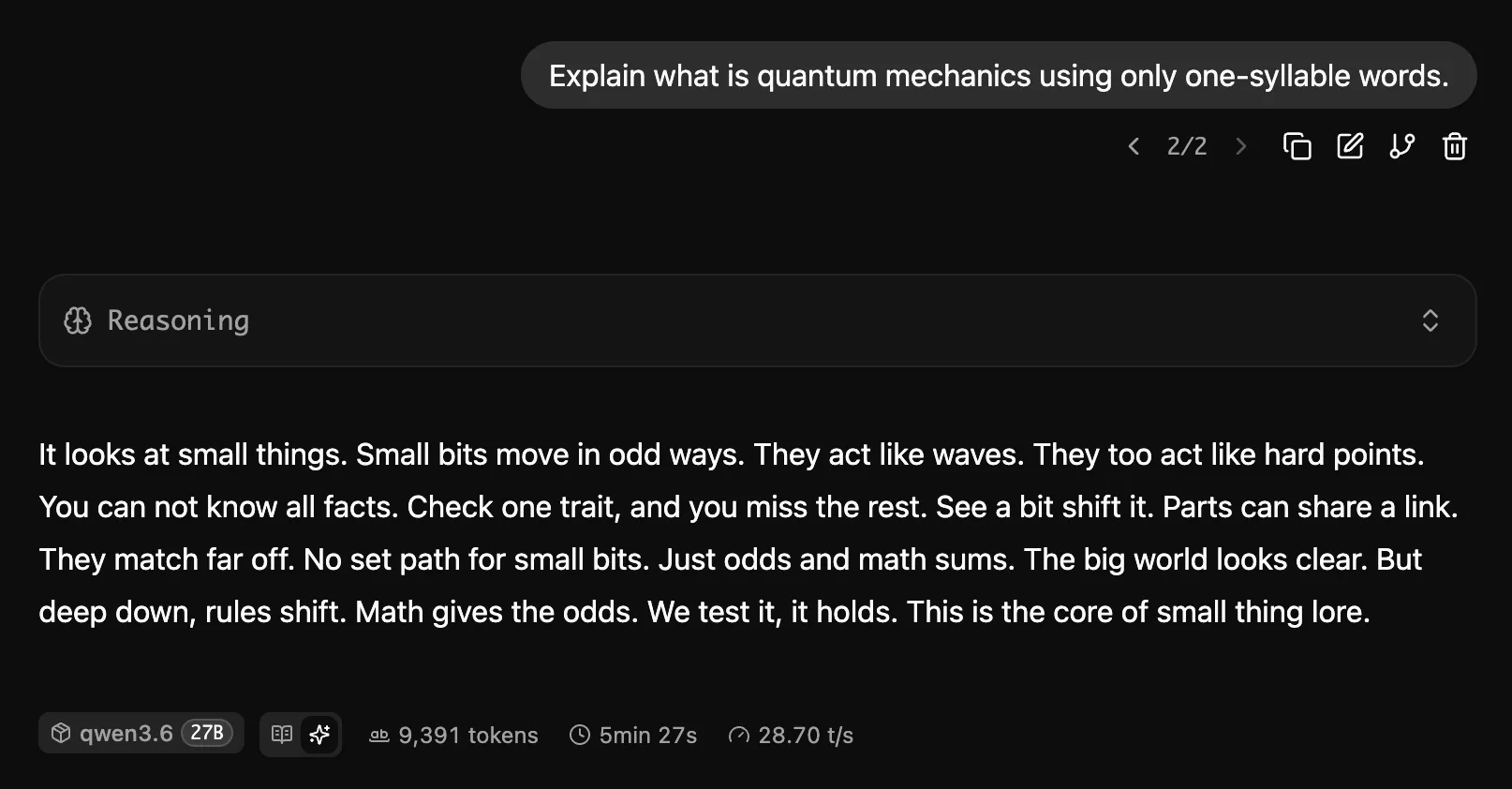
記事では、まず「penguins on a bicycle」みたいな定番の軽いテストではなく、制約のある文章生成を試しています。たとえば、Zouk danceと量子物理学について8行の詩を書かせる、といった遊びです。こういうタスクは、ただ文法が正しいだけではダメで、テーマの保持やリズム感、言葉遊びまで見えてきます。
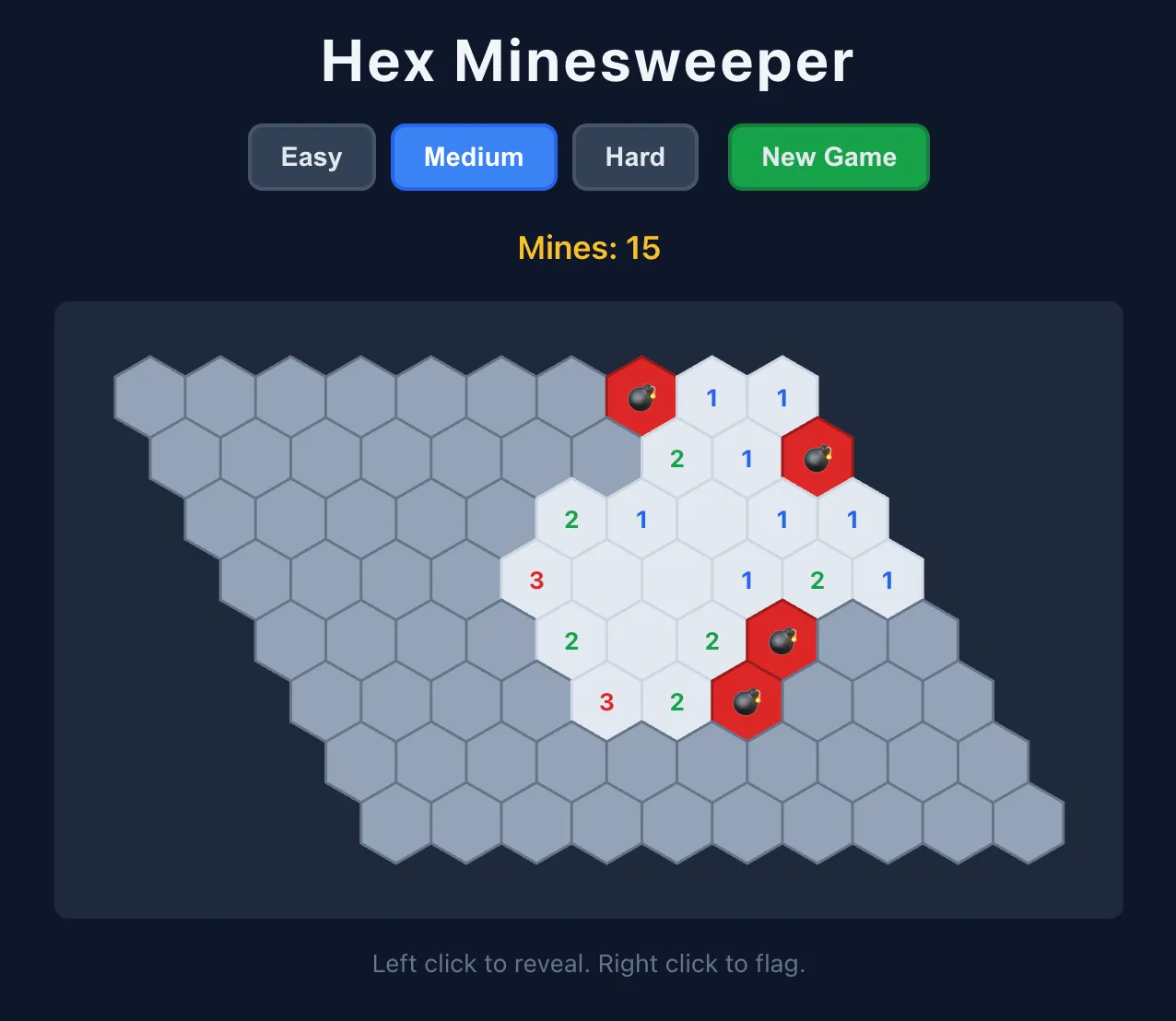
さらに面白いのが、OpenCodeを使って六角形のマインスイーパーを作らせた話です。しかもpnpmでちゃんとNodeプロジェクトとして作った。これは地味にすごいです。AIは「それっぽいHTMLファイルを1枚吐く」方向に逃げがちですが、著者はそこを避けたかった。結果、Qwen 3.6 27Bは一発でうまくいった。一方で、同じ系列のMixture-of-Experts版である35B A3Bは速かったけれど、プロジェクト化の指示を無視して単一のindex.htmlに寄せてしまったそうです。

この差は、実務ではかなり効きます。速さだけだと、結局あとで人間が直す。少し遅くても、仕事の形になって出てくるほうがずっと価値がある。著者が27Bを推すのは、その感覚が大きいのだと思います。
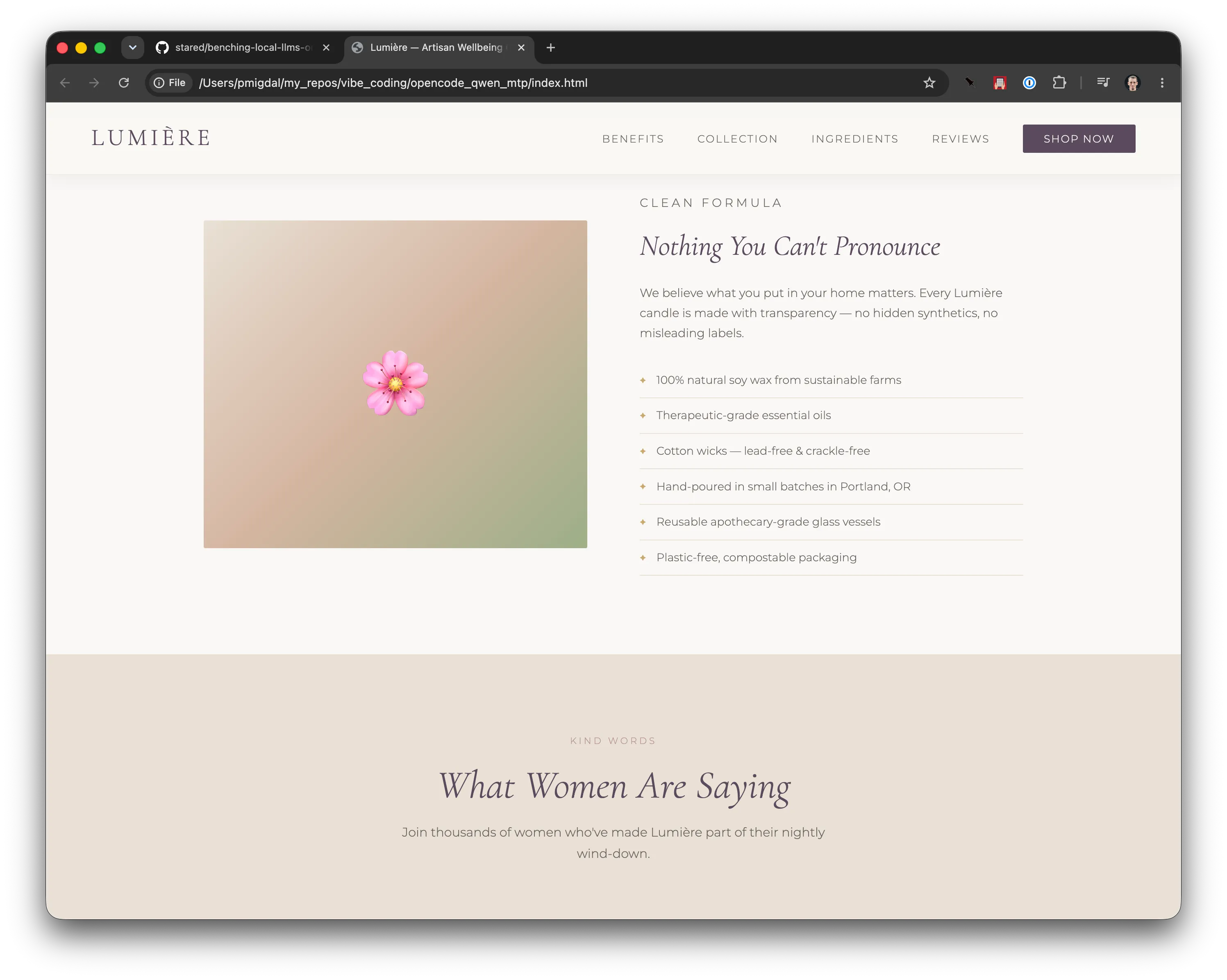
創作系のテストがそこそこ通っても、「で、実際の仕事は?」となります。ここで著者は、友人からのプロンプトを使ってランディングページを作らせています。数分で動くページを生成し、見た目やデフォルトの選び方もまずまずだったとのこと。
正直、これは派手ではありません。でも、現場ではこういう「まあ普通に使える」がいちばん強いです。爆発的に賢いより、短い指示で実用的なものを返してくれるほうがありがたい。AIの価値は、天才芸よりも日常の摩擦をどれだけ減らすかにある、という話です。
記事のもう一つの見どころは、実際にどう動かすかをかなり具体的に示している点です。ここで使われるのが llama.cpp。これはオープンソースの実行ツールで、いろいろな端末やGPUでモデルを走らせやすいのが特徴です。著者はOllamaよりもこちらを勧めています。理由まで含めてかなり強い言い方ですが、少なくとも「ローカル実行の自由度」を重視する人には筋が通っています。
モデルはHugging Faceから、量子化済みのものを取ってきます。量子化というのは、ざっくり言えば「精度を少し落として、そのぶんサイズを小さくする」工夫です。たとえば8-bit量子化なら、元の精度よりは軽いけれど、品質の低下は比較的小さい。さらに軽くすると動かしやすくなる一方で、賢さが少しずつ削れる。この記事でも、そのトレードオフが前提になっています。
著者は Qwen3.6-27B-MTP-GGUF:Q8_0 を使い、llama-server でローカルサーバーを立てています。MTP は multi-token prediction の略で、先のトークンをまとめて予測して速度を上げる仕組みです。細かいところですが、こういう実装の工夫が効いているのが今のローカルAIです。単に「モデルが強い」だけではなく、「どう回すか」で体感が変わる。
OpenCodeにつなぐ設定も載っていて、要するにローカルの http://127.0.0.1:8080/v1 をOpenAI互換のAPIとして扱う形です。こういう「クラウドAPIっぽく見せる」設計は、道具の再利用性が高くて好きです。私はこういうところに、ローカルAIの実用化が見えてくると思います。モデルそのものより、周辺の接続が実務に乗るかどうかのほうが大事だからです。
著者はMacBook Max M5 128GBで速度比較をしています。ざっくり言うと、Qwen 3.6 27Bはllama.cppでおよそ18 tokens/s、MTPを使うと32 tokens/s程度。30 tokens/sなら、体感としてはかなり使えます。チャットが「もっさりして待てない」という感じにはなりにくいはずです。
一方で、同じく比較対象のQwen 3.6 35B A3Bはもっと速く、85〜105 tokens/sあたりまで出ています。これはかなり魅力的ですが、著者はそれでも27Bを好んでいます。理由はシンプルで、「3分の1くらいのコード量でも、質が高いほうがいい」から。これ、かなり人間らしい判断です。速さの数字だけ見れば35B A3Bに軍配が上がっても、開発体験としては27Bのほうが気持ちいい場面がある、ということですね。
メモリ消費も重要です。記事では、Qwen 3.6の両モデルがApple Siliconの共有メモリ48GB以内で動き、4-bit量子化なら32GB機でも見えてくる、とされています。Nvidia RTX系ならもっと攻めた量子化で回せるので、個人のハイエンドPCでも現実味があります。ここはかなり希望があります。少し前まで、こういうモデルは「研究室の話」でした。それが、今は「個人のデスクトップで触れる話」になっている。
著者は体感だけでなく、Artificial Analysisのベンチマークにも触れています。そこではQwen 3.6 27Bはかなり高い位置にあり、以前の有力モデルより一段上の世代に相当する、といった並びで示されています。もちろんベンチマークは万能ではありません。数字が高いから、必ず現場で勝つとも限らない。とはいえ、ここで面白いのは「人の感想」と「数字」が同じ方向を向いていることです。
ローカルモデルの評価でありがちなのは、ベンチマークは良いのに触ると微妙、あるいはその逆です。でもこの記事では、Qwen 3.6 27Bがその両方で筋が通っている。だからこそ、「ほんとうにローカル開発の甘いところに来たのでは」と感じさせます。
記事の後半は、少し未来の話になります。著者は、今後は自分の手元で動くモデルがもっと当たり前になるだろうと見ています。企業にとっては機密データや社内情報を外に出さずに済むし、個人にとってもオフラインで使えるメリットは大きい。医療情報のような、外部に出したくないデータを扱うときにも意味があります。
それに加えて、著者は「知識」と「推論」を同じ重みで抱え込む現在の作り方が、今後は変わるかもしれないとも示唆しています。つまり、モデル自身に全部を覚えさせるのではなく、ツール呼び出しで必要な知識を取りに行く形です。これはかなり筋がいい見方だと思います。AIが賢くなるというより、AIの周辺が賢くなる。そうなると、ローカルで動かせる範囲も広がっていくはずです。
著者は、将来的にはスマートフォンでも動くほど賢いモデルが出るかもしれないとまで書いています。さすがにそこは夢も入っていると思いますが、今の流れを見ると完全な空想とも言い切れません。数年前の「このサイズでここまでできるの?」が、今では何度も現実になっているからです。

Qwen 3.6 27Bの記事は、単なる新モデル紹介ではありません。ローカルAIが「趣味の実験」から「ちゃんと使う道具」に変わりつつある、その境目をうまく切り取った記事です。個人的には、ここがいちばんおもしろい。AIの話はどうしてもトップ性能ばかりに目が行きますが、実際に日々使うのは、その少し下の「ちょうどいい」層です。Qwen 3.6 27Bは、まさにそこに刺さっているように見えます。
参考: Qwen 3.6 27B is the sweet spot for local development - Quesma Blog
