この記事、かなり刺さります。なぜなら、AI採用ツールって「公平で効率的」な顔をして入り込んでくるのに、実際にはかなり気まぐれだったりするからです。人間の採用も完璧ではない。でも、AIなら少なくともブレないはず、という期待がある。その期待を、著者は自分の履歴書であっさり裏切られたわけです。
著者の Dan Kinsky は、HackerRank がオープンソース化した ATS を試してみました。ATS は Applicant Tracking System の略で、応募書類を集めたり、整理したり、スクリーニングしたりする採用支援システムのことです。要するに、採用担当者の前段階で候補者をふるい分ける装置ですね。
で、その評価システムが LLM を使って履歴書を採点する。ざっくり言うと、PDF の履歴書をテキストに変換し、そこから「基本情報」「職歴」「学歴」「スキル」「プロジェクト」「受賞歴」を抽出し、さらに GitHub プロフィールや上位リポジトリまで見て、最後にまとめて採点する仕組みです。点数は100点満点で、オープンソース貢献や個人プロジェクト、職歴、技術スキルに配点があり、さらに起業経験やポートフォリオ、技術ブログなどにボーナスがつく設計です。
ここまでは、いかにも「AIっぽい」し、なんとなく賢そうにも見えます。問題は、その賢そうな見た目の裏で、点数がかなり揺れることでした。
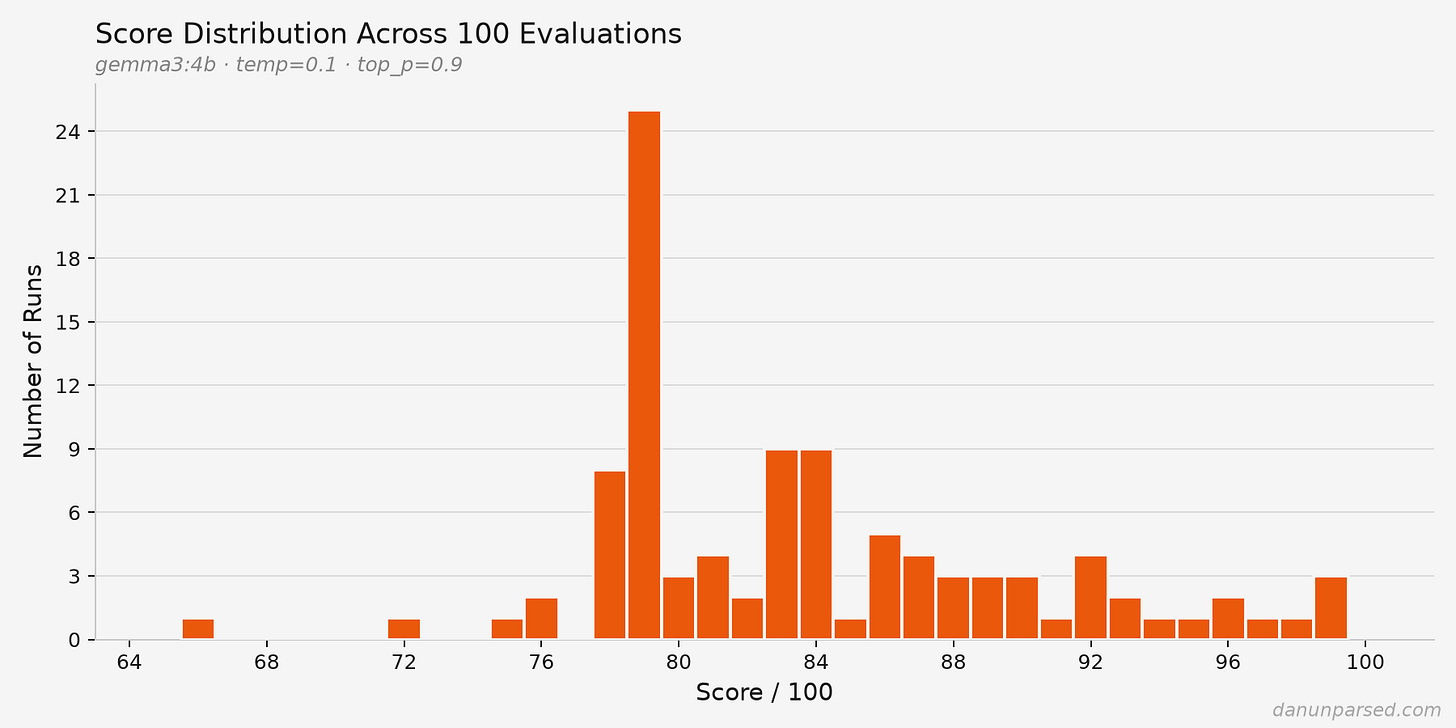
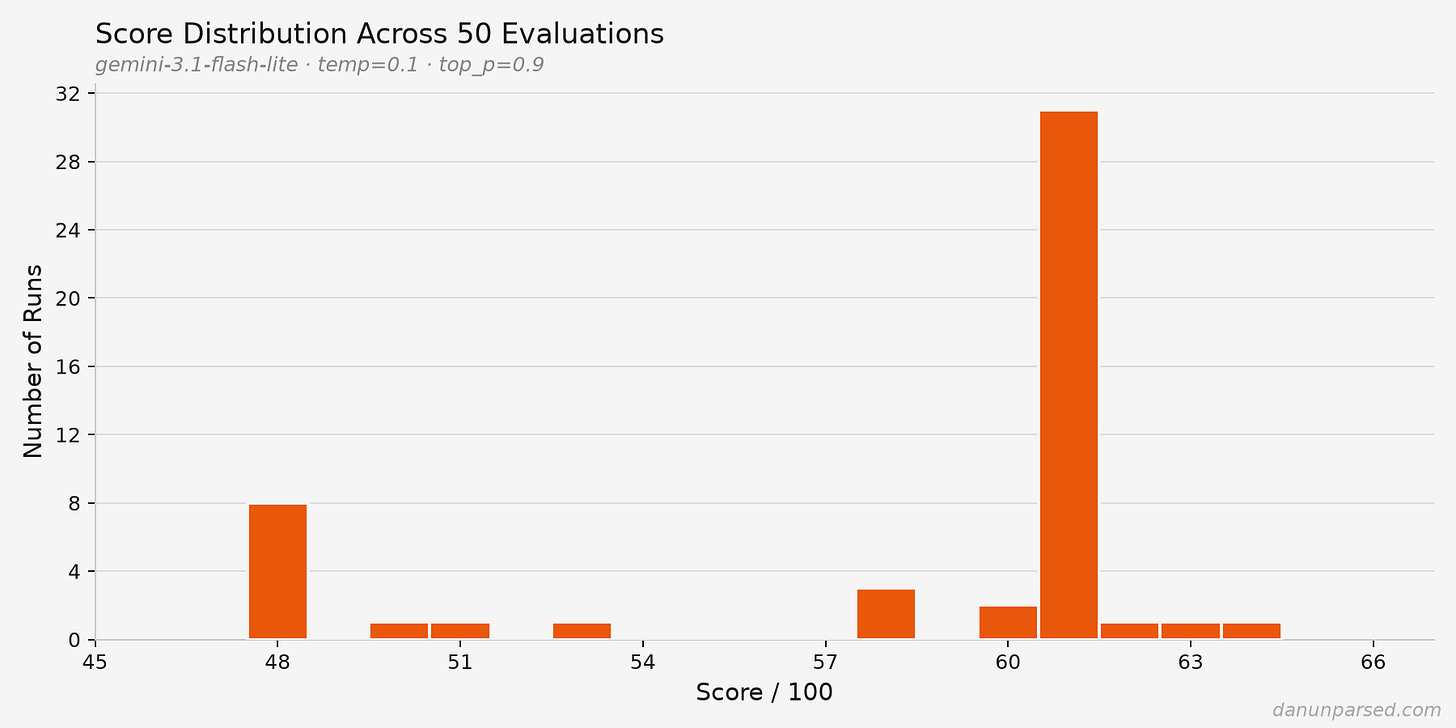
著者が最初に実行したときは 90/100。お、なかなか高い。ところが、デバッグ用の print 文を消して再実行したら 74/100 になった。同じ履歴書、同じコマンドです。違ったのは、余計な出力を消しただけ。さらに DEVELOPMENT_MODE を切って100回ループさせると、点数は 66〜99 まで散らばったそうです。もし採用の足切りが 85 点なら、同じ履歴書なのに 65% の確率で落ちる計算になります。これ、かなり怖いです。
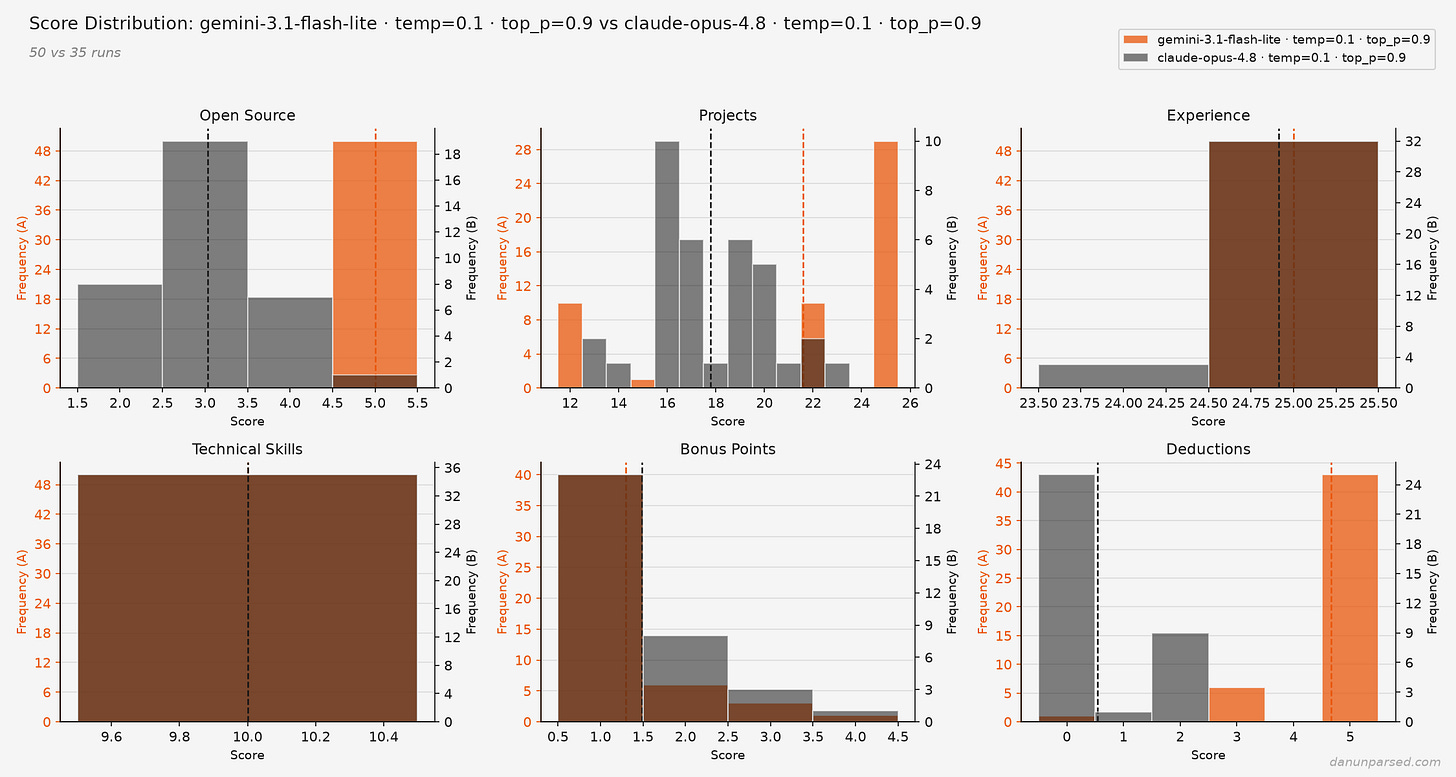
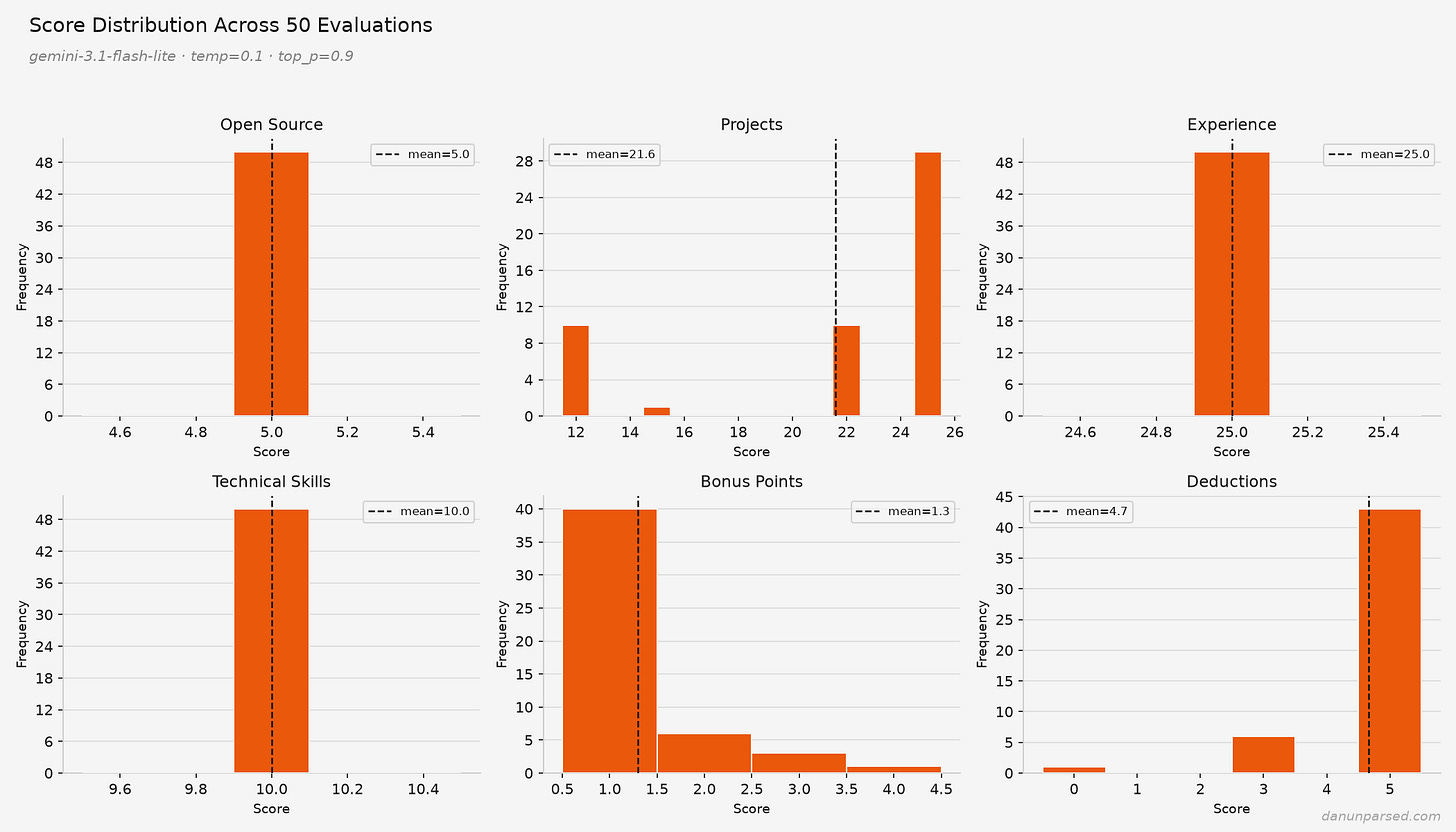
著者が面白いのは、単に「ブレた」で終わらせず、どの項目がどれだけブレるかを見ているところです。技術スキルはかなり安定していて、98回の実行で 8/10 になった。これは納得感があります。React を書けるか、Python を使った経験があるか、みたいな項目はチェックリストで判定しやすい。AIが迷いにくいんでしょう。
一方で Projects は大きくぶれたそうです。あるときは「アーキテクチャの複雑さが足りない」と言い、別のときは「実世界でのデプロイを示している」と評価する。どっちなんだ、となります。しかも temperature を 0 にしても、完全には安定しない。temperature は AI の「ランダムさ」を下げる設定ですが、ゼロにしても揺れるのなら、単なる設定ミスではなく仕組みそのものの問題だという話になります。著者はそこをかなり強く押しています。これは細かい実装の不具合ではなく、設計上の欠陥ではないか、と。
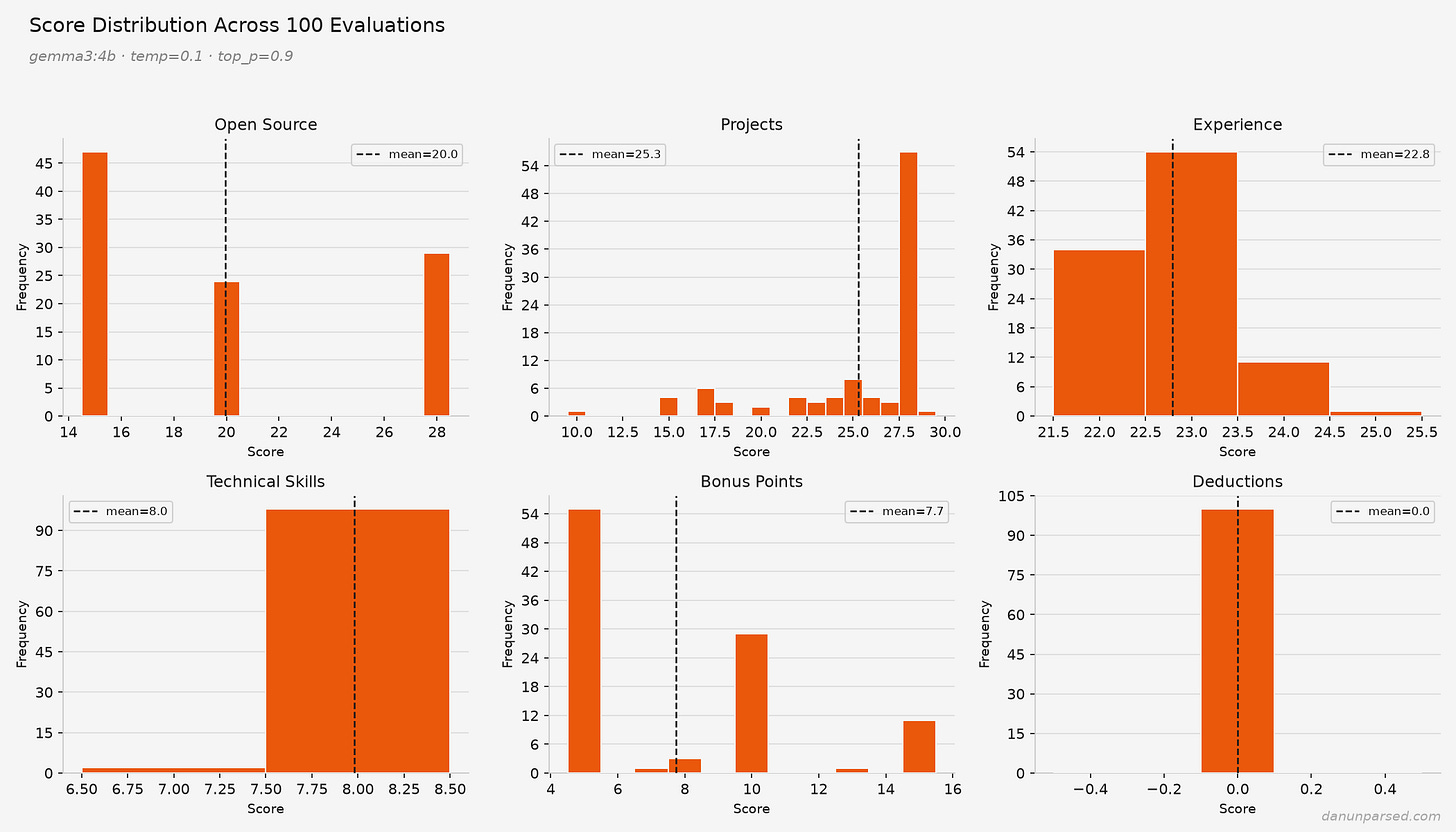
さらに厄介なのが Experience の扱いです。著者はそこが 25/25 で、毎回まったく変わらなかったと書いています。しかも昔の、インターンが1つだけ載った履歴書でも 25/25。なぜか。理由はプロンプトにある、とのことです。
記事中で引用される Experience の評価基準は、かなり雑です。ざっくり「work や volunteer の欄を見て、実務経験やインターン、プロダクション経験を評価しろ」「スタートアップの創業者や初期メンバーなら特別に考慮しろ」という程度。基準が薄すぎる。15点と25点の違いが何なのか、例も境界線もない。これでは、経験豊富なシニアエンジニアも、新卒に近い人も、みんな 25 点になってしまっても不思議ではありません。
ここがこの記事の一番の嫌味であり、一番の本質だと思います。
「安定している」ことと「意味がある」ことは別、ということです。
Experience は安定しているけれど、雑にしか見ていないから役に立たない。Projects はそれなりに細かいルーブリックがあるけれど、今度はぶれすぎて使い物にならない。つまり、安定してもダメ、細かくしてもダメ、という嫌な現実です。
著者は、LLMを使うなら向いている用途と向いていない用途を分けるべきだと考えています。履歴書を構造化データに変える、つまり「どこに何が書いてあるか」を抜き出す用途ならかなり有用。Python が書けるかどうかのような、比較的はっきりした判断も向いている。でも、「この人の経験は18点か24点か」みたいな曖昧な採点は向いていない。そこでは結局、雰囲気採点、つまり vibe-check になってしまう。
この表現は少し皮肉ですが、かなり本質的です。採用の現場って、もともと人間の主観や印象でぶれやすい。そこにAIを入れたら、もっと機械的に、もっと公平になるのでは、と期待してしまう。でも実際には、AIのほうが「それっぽい理由」をつけてブレることがある。しかも本人には理由が見えにくい。これは人間の偏見より見えにくいぶん、厄介だと思います。
著者は特に、Open Source と Projects に 65% の重みがある設計を問題視しています。30年の経験があって、S3 のような大きなものを作ったエンジニアより、インターン2回と GitHub プロジェクトだけの人が高く出るかもしれない。しかも、GitHub に成果物を残していない優秀なエンジニアは普通にいる。つまり、GitHub に載せやすい仕事をしてきた人に有利で、そうでない人には不利です。これ、かなり偏っています。
個人的には、ここがいちばん「AI採用の危うさ」が出ていると思いました。
AIが公平そうに見えるのは、数字が出るからです。でも、その数字が何を見ているのかが怪しいなら、むしろ危険なんですよね。0か100かの単純な話ではなく、「点数化された偏り」が発生する。しかも本人はその基準を確認できない。採用でこれをやるのは、かなり慎重であるべきだと思います。
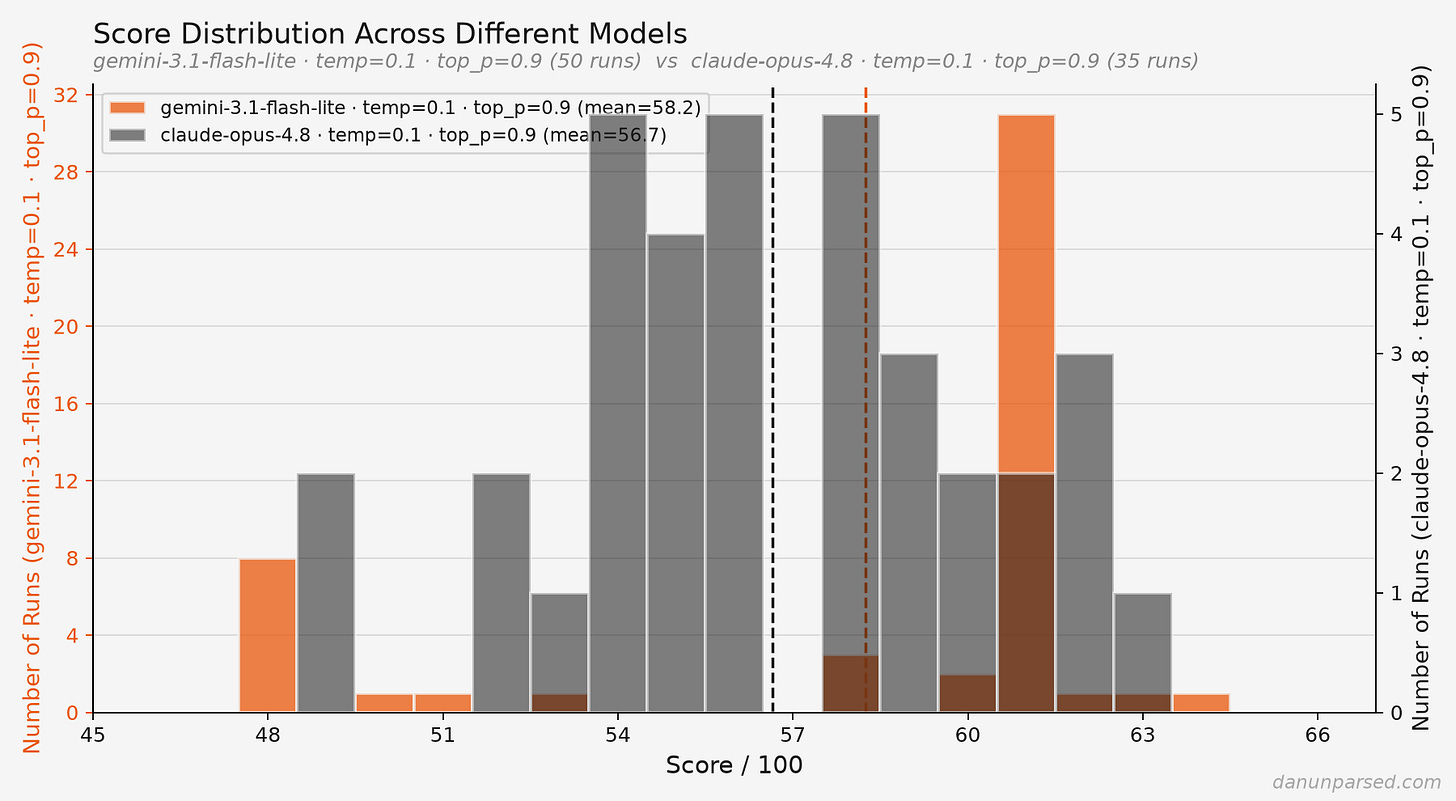
記事の後半では補足も入ります。読者からの指摘で、テンプレートに「Software Intern」とあるらしいことが見つかり、著者は Senior SWE を明示して再実行したが結果は同じだったと説明しています。つまり、この採点は肩書きにそこまで依存していない。さらに、その後 Claude を使うようにした PR を試したところ、点数のぶれは少し狭まったものの、やはり Projects は不安定で、Skills は完璧に安定したままだったそうです。モデルを変えても、問題の核はあまり変わらない、ということです。
著者の結論はかなり率直です。AIスクリーニングツールを使うなら、かなり気をつけたほうがいい。判別できないツールは、質を見分けるフィルターではなく、ただのフィルターにすぎない。悪く言えば、履歴書の半分を運任せで捨てているだけかもしれない。
この話、単なる「LLMはまだ未熟でした」で終わらないのが面白いところです。むしろ逆で、LLMは構造化や要約のような仕事には向いている。でも、採用のように人生に影響する判断を、しかも点数でやらせると、急に雑になる。そのギャップがかなり生々しい。
AI採用は、効率化の顔をした luck filter になりうる。著者の言い方を借りるなら、まさにそこがこの文章の核です。採用にAIを入れるなら、「便利そうだから」で進めるのではなく、何を判定させて、何を絶対に判定させないかをはっきり分けるべきだと思います。そうしないと、優秀な人を見逃す理由が、実力ではなくたまたま出たスコアになってしまうからです。