Aleph Alpha の記事「Model Training as Code」は、かなり地に足のついた話です。派手な新技術の宣伝というより、「巨大なモデルを本気で作ると、もう人間の記憶とSlackだけでは無理だよね」という現場感が前面に出ています。ここがまず良い。実際、モデル学習は昔の“研究っぽい実験”から、今では立派な大規模エンジニアリングになっているのだと思います。
記事の中心にあるのは、Savanna という社内の model factory です。名前はかわいらしいですが、中身はかなり本格的です。Aleph Alpha は、pre-training から post-training までを含む学習パイプライン全体を code で実装し、それを Model Training as Code(MTaC) と呼んでいます。要するに、「学習手順を人の頭の中や雑多な運用に置かず、最初から最後までソフトウェアとして管理する」という発想です。
![]()
この記事がうまいのは、なぜそれが必要かを、かなり具体的な失敗パターンで見せているところです。
ひとつは単純なミスです。データチームが Slack でパスを送り、pre-training チームが長い学習を始める。ところが途中でストレージが満杯になって止まる。古いデータセットを消していいのか誰も分からない。GPU は遊ぶ。再開するころには、当初の設定を Slack と記憶から復元する羽目になる。こういう話、笑えますが、たぶん現場では笑えません。高価な GPU 時間が溶けるので、かなり痛いはずです。
もうひとつは、学びが残らない ことです。SFT(supervised fine-tuning。人手で正解例を与えて調整する工程)や RL(reinforcement learning。報酬を使って振る舞いを改善する工程)の試行錯誤をやっても、その判断理由が Slack、Wiki、実験管理ツール、ファイルシステムに散らばる。すると、数か月後に同じ試行をまた繰り返してしまう。これは地味ですが、かなり大きな損失です。人は忘れるし、組織はもっと忘れる。ここをコードと履歴で残すのは、かなり筋がいいと思います。
さらに厄介なのが、チームが自分の担当範囲だけを最適化してしまう ことです。SFT チームは SFT だけ、RL チームは RL だけを見ていると、最終的なモデル全体の品質がズレる。しかも手動の引き継ぎは頻繁にできないので、1か月分の差分を毎回まとめて解消することになる。これは組織設計の問題でもあります。技術の問題に見えて、実はかなり人間くさい。

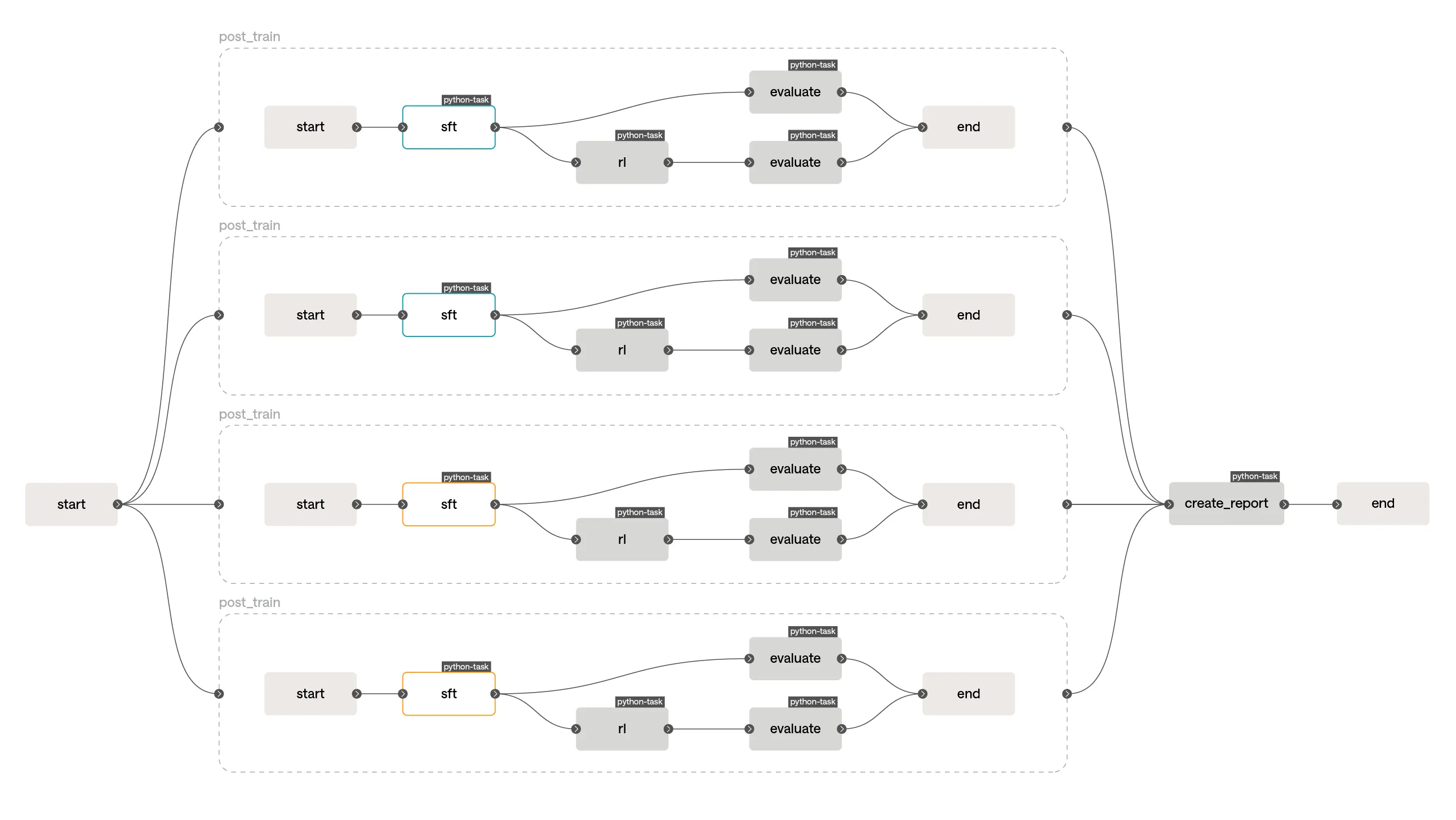
そこで登場するのが MTaC です。記事では、post-training の例を擬似コードで示しています。SFT の checkpoint を作り、その結果を評価し、次に RL を走らせ、また評価する。こういう流れを関数として書く。すると何が起きるかというと、単なる“自動化”以上のものが手に入るわけです。
Aleph Alpha が挙げている利点は3つで、これはどれも納得感があります。
まず composability。日本語でざっくり言えば「部品としてつなぎやすいこと」です。各ステップを typed inputs / outputs を持つ関数として扱えるので、パイプラインを組み合わせやすい。途中の checkpoint だけを評価する、といった部分実行もしやすい。ここはソフトウェア開発の世界では当たり前でも、学習パイプラインだと途端に難しくなるので、コード化の価値が出ます。
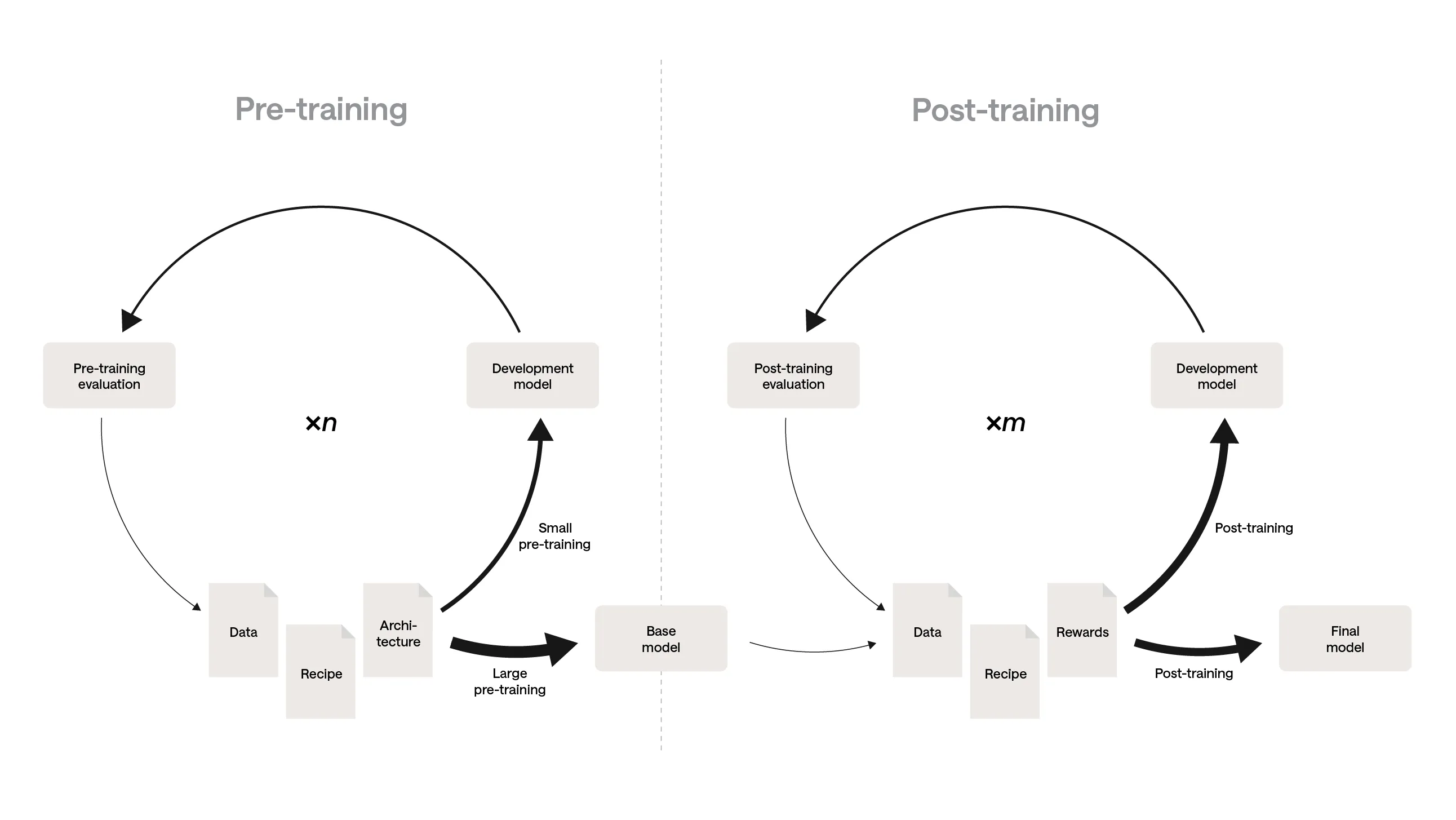
次に consensus。これは version control、つまり Git の強みです。main branch が「いまチームとして最も正しいと考えている学習手順」になる。学習を始めるときに、設定を誰かの記憶から復元する必要がない。正直、ここはかなり大きいです。人間の脳内に“本番設定”を保存しておくの、危険すぎます。
最後が provenance。ざっくり言うと「その結果がどう生まれたかの来歴」です。コメント、commit history、実行した commit の固定、これらで「このモデルはどのコードとどの判断から生まれたのか」を追える。研究でもプロダクトでも、この追跡可能性は本当に強い。個人的には、AI の現場で一番足りなくなりがちなものの一つがこれだと思います。
記事の後半で面白いのは、MTaC が単なる“きれいな設計”に留まらず、チームの分け方まで変える と言っている点です。従来は「工程ごと」にチームを分ける。pre-training、SFT、RL のように縦割りです。でも MTaC があると、「多言語対応を改善するチーム」「特定の振る舞いを end-to-end で持つチーム」といった、能力ベースの分解がしやすくなる。これはかなり発想がいい。工程ではなく、モデルの性質で責任を持つわけです。現場の自由度が上がりそうですし、チーム同士の接続も自然になるはずです。
ただし、ここで終わらないのが記事の誠実なところです。コードにしただけで全部うまくいくわけではない。むしろ、コード化したからこそ、ちゃんとした開発文化が必要になる と言っています。特に重要なのが trunk-based development、つまり長く分岐したまま放置せず、小さな変更を早く main に入れるやり方です。パイプラインが code になったなら、普通のソフトウェアと同じで、統合を先延ばしにすると結局 debt が積み上がる。これはその通りだと思います。技術的な正しさより、運用の地味な律儀さのほうが効くことは多いです。
Savanna の運用もかなり実戦的です。GitHub 上にあり、CI が学習の入口になっている。push でも手動実行でも学習を起動でき、main に対して CI を回せば本番の大規模 run が走る。pull request では小規模な end-to-end 実行をして、5分未満でパイプライン全体を確認する。さらに夜間には大きめのテスト run を回して、モデルが評価スイートで改善しているかを見る。こういう“速い確認”と“重い確認”の二段構えは、かなり現実的です。

そして地味にすごいのが、artifact lineage です。データ、モデル、tokenizer などの非コード資産を immutable かつ versioned に扱い、どの run が何を使って何を出したかを追える。要するに、Slack 検索ではなく lineage graph で辿る。これ、当たり前に見えてなかなかできない。データセットがどのモデルに使われたかを機械的に追えるのは、後から見ると相当ありがたいはずです。
実験のやり方も、いかにも code らしいです。たとえば learning rate を変えた sweep を、for ループで複数回の run として書ける。しかも workflow engine が同じ入力の stage を見つけると cache を使うので、重複計算を避けられる。ここはかなり賢い。学習の実験って、少し条件を変えただけで計算が爆発しがちですが、cache が効くなら試しやすさが全然違います。
全体を読んで感じるのは、Aleph Alpha は「モデル学習を研究の延長ではなく、巨大な共同開発ソフトウェアとして扱う」方向にかなり踏み込んでいる、ということです。これは派手さはないけれど、スケールする組織にはかなり効くはずです。個人的には、AI 開発の本質がだんだん「モデルを作ること」から「モデルを継続的に作り続ける仕組みを作ること」へ移っているように見えます。この記事は、その流れをとても素直に示しています。
![]()
