元記事の主張はかなり明快です。
context window が大きいことと、memory があることは別物だ、という話です。
ここでいう context window は、AIモデルが一度に読める文章量の上限です。
人間でいうと「机の上に広げて見られる書類の量」に近い。広ければ広いほど便利そうですが、だからといって「その机が記憶装置になる」わけではありません。
著者のたとえがわかりやすいです。
巨大な机を買って、ファイルキャビネットを使わずに全部を机の上に置いておくようなものだ、と。
たしかに目の前には全部見える。でも、仕事が終われば片づけられる。次の作業のたびに、また全部広げ直す。これでは“記憶”とは言いにくいですよね。

個人的にも、この感覚はかなり重要だと思います。
最近のLLMはコンテキストがどんどん長くなっていて、「じゃあ全部入れればいいじゃん」と思いがちです。けれど、実際にはそれで解決する問題と、むしろ悪化する問題がある。そこを混同すると、設計が雑になります。
元記事で強調されているのは、LLMは基本的に stateless、つまり状態を持たないという点です。
APIを1回呼ぶたびに、モデルは「前回の自分」を引き継いでいるわけではありません。毎回ゼロから、与えられた入力だけを見て答えています。
だから、たとえば47回目のやり取りで「1回目に決めた変数名は何だったっけ?」と聞きたければ、1回目から46回目までの履歴をもう一度ぜんぶ送る必要がある。
これは地味に見えて、かなり重いです。
著者はここで3つの問題を挙げています。
![]()
まず、長い文章の真ん中が雑に扱われやすいこと。
LLMは長文の最初と最後に強く反応しやすく、真ん中に埋もれた情報を見落としやすい、という経験則があります。人間でも、分厚い資料を最初と最後だけ読んでしまうことがありますよね。あれのAI版です。
次に、会話が長くなるほど、毎回の入力が雪だるま式に増えること。
前の履歴を全部送り直すので、1つ質問するたびにコストも増える。これは効率が悪い。
そして、応答開始までが遅くなること。
長い壁みたいなテキストを毎回飲み込ませると、最初の1語が出るまでの待ち時間が伸びる。著者はこれを brain freeze のようなものだと表現しています。たしかに、かなり実感に合います。
次に出てくるのが Retrieval-augmented generation、いわゆる RAG です。
これは簡単に言うと、必要そうな情報だけ検索して、コンテキストに入れる仕組みです。
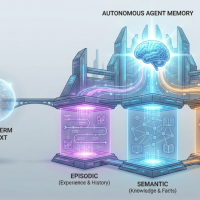
著者の比喩では、RAG は「部屋の中にある大きな本棚」です。
机の上に全部載せるのではなく、本棚から今必要な資料だけ取ってくる。かなり筋がいいやり方です。
ただし、ここにも落とし穴があります。
検索で似ている文書が取れてきても、それが真実として正しいとは限らない。
たとえば、会議を金曜日に移動したという記録と、その後に「やっぱり木曜の件はキャンセル。Alice が病気」といった記録が両方あるかもしれない。ベクトル検索は、意味が近いものを拾うのは得意でも、どちらが最新の事実かまでは勝手に判断しません。
ここが面白いところで、著者はエージェントに「会計士のように扱え」と言っています。
つまり、拾ってきた情報をそのまま信じるのではなく、どちらが今の現実を表しているかを整理する責任が必要だということです。
この指摘はかなり大事です。
RAG は魔法の箱ではありません。検索して終わりではなく、矛盾を解くロジックが要る。
最新のものを優先するのか、信頼度で選ぶのか、ユーザー確認を挟むのか。ここを決めないと、AIは自信満々に古い指示を読み上げます。実務ではこれが一番まずい。
Compression の説明はシンプルです。
ZIP 圧縮をイメージするとわかりやすい。中身の情報はなるべく保ったまま、入力サイズを小さくする。
たとえば大きな JSON の応答が15,000 tokens あるとして、それを圧縮モデルで5,000 tokens くらいに削る。そうすると、context window の余白を節約できる。
元記事では LLMLingua のような手法にも触れています。
ここでのポイントは、中身を「要約」してしまうのではなく、できるだけ情報を保ちながら軽くすることです。
要約だと細部が消えますが、圧縮は「そのまま持っていく」寄りです。もちろん完全ではないけれど、役割が違う。
私はこの発想、かなり現実的だと思います。
AIエージェントって、派手な推論より先に、まず入力が重すぎて詰まることが多いんですよね。
だから、モデルを賢くする前に「机の上を片づける」。この地味な工夫が効きます。

Summarization は、圧縮よりさらに割り切った方法です。
元データを消して、代わりに短い要点を残す。つまり一方通行です。
ここで著者が強調するのは、要約は不可逆だということ。
一度短くしたら、細かいニュアンスは戻りません。だから、要約だけに頼るのは危険です。
元記事では、raw transcript は S3 や SQL のような安いストレージに保存しておき、実際にモデルへ渡すのは要約だけにする「forked storage」の考え方を勧めています。
これはかなりまっとうな設計です。
要するに、原本は別に残し、軽いコピーだけを現場で使う。
これなら後で見直せるし、要約の誤りも検証できます。
実務でありがちな失敗は、要約だけを唯一の真実にしてしまうことです。
すると、要約の時点で落ちた情報はもう二度と戻らない。しかも、要約が少しズレていたら、そのズレがずっと残る。地味ですが怖いです。

元記事の最後の方向性は、かなり示唆的です。
エージェントに必要なのは、「自分がすべてを覚えること」ではなく、どこに何があるかを管理することだ、という考え方です。
つまり、モデル自身を database にするのではなく、
この役割分担が、いわば cognitive stack の設計です。
ちょっと大げさに聞こえるかもしれませんが、実際のところ、ここを雑にするとエージェントはすぐ混乱します。
私の感想を言うと、AIエージェント開発は「賢い会話相手を作る」より、「雑多な事務処理が破綻しないように裏方を整える」仕事に近いです。
派手さはないけれど、ここができているシステムは強い。逆に、ここをサボると、どれだけモデルが大きくても使い物になりません。

この話が面白いのは、単なる技術論ではなく、AIの“勘違い”を正面からほどいているところです。
長い context window は確かに便利です。けれど、それは「広い作業台」であって、「記憶の部屋」ではない。
そして、実用的なAIエージェントを作るには、
検索で拾う、圧縮して軽くする、要約して残す、原本は別に保管する、という複数の層をちゃんと分ける必要がある。
この整理ができると、システムはかなり安定します。
要するに、AIに「全部覚えて」と頼むより、覚えたふりをさせない設計のほうが大事だ、ということです。
ここ、かなり本質だと思います。
