![]()
![]()
Semgrepのこの記事、AIモデルのランキング発表に見えて、実はかなり地味で重要な問いを突いています。
「脆弱性検出の性能って、モデルそのものの力なのか、それとも周辺の仕組みの力なのか?」という話です。
![]()
![]()
![]()
これ、地味ですがめちゃくちゃ大事です。
生成AIの世界では、つい「どのモデルが最強か」に目が行きがちです。でも実務では、モデル単体よりも、どうやってコードを読ませ、どこを見せ、どう検索させ、どう結果を整えるかのほうが効いてくることが多い。Semgrepはそこを正面から試したわけです。
![]()
![]()
![]()
対象にしたのはIDORという脆弱性です。日本語でざっくり言えば、「自分には見えないはずの他人のデータにアクセスできてしまう」問題。たとえば、URLの数字を少し変えただけで別ユーザーの請求書やプロフィールが見えてしまう、あの手のやつです。アクセス制御のミスなので、見つけるにはコードの断片を読むだけでなく、認可処理がアプリ全体でどうつながっているかを見る必要があります。ここがややこしい。
![]()
![]()
![]()
Semgrepの内部パイプラインは、ただモデルにコードを投げるだけではありません。アプリのエンドポイントを列挙し、重要そうな文脈を拾い、モデルが見るべき場所へ誘導します。つまり「探偵に地図を渡して現場に案内する」ようなものです。
一方、今回比較したモデルたちは、その手厚い足場なし。Pydantic AIのシンプルなハーネスで、同じIDOR用プロンプトを与えられただけです。ちょっとした検索のコツや、IDORっぽい箇所の見方は教えていますが、基本は「はい、コード。探して」で済ませた形です。
![]()
![]()
![]()
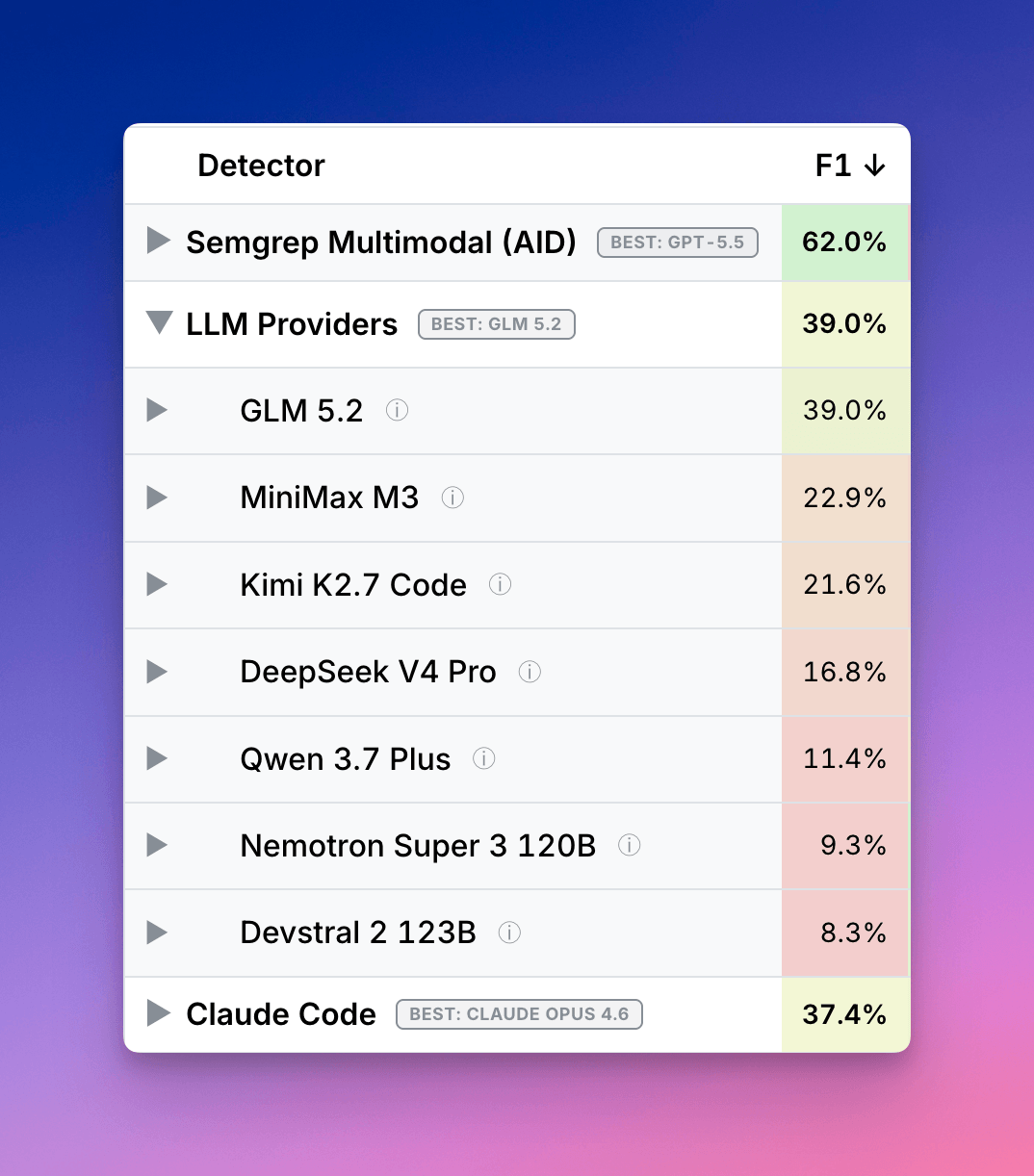
その条件で、GLM 5.2が39% F1を記録し、Claude Codeの32%を上回った。F1スコアは、ざっくり言うと「見つける力」と「見つけ方の正確さ」を合わせた指標です。検出系ではよく使われます。
しかもSemgrepによれば、見つけた1件あたりのコストはおよそ0.17ドル。かなり安い。ここは素直に驚きました。高性能なモデルは高い、という感覚を少し崩してきます。
![]()
![]()
![]()
ただし、ここで勘違いしてはいけないのは、GLM 5.2がSemgrepの自社パイプラインを超えたわけではないことです。Semgrepのmultimodal pipelineは53〜61% F1で、まだ上です。
でもそれは、専用のハーネスの中で、かなり多くの下ごしらえをしているから強い。モデル単体の素の力比べとは、土俵が違う。この記事が面白いのは、そこをあえて分けて見せたところです。
![]()
![]()
![]()
GLM 5.2自体も、セキュリティ用途で気になる要素が多いです。まず open-weight であること。これはモデルの重みが公開されているという意味で、自前の環境に持ち込んで動かしたり、必要なら調整したりしやすい。セキュリティの現場では、コードや機密情報を外に出したくないことが多いので、この自由度はかなり大きいと思います。
ただし、open-weight は open source と同義ではありません。重みは公開されていても、学習データや学習パイプライン全体までは見えないことが多い。ここはよく混同されるので注意です。



性能面では、GLM 5.2はMoE(Mixture-of-Experts)モデルです。これは、巨大なモデル全体を毎回フル稼働させるのではなく、入力に応じて一部の「専門家」だけを使う方式です。総パラメータは約7500億ありますが、1トークンあたりのアクティブ量は約400億。かなり大きいのに、推論コストを抑えやすい設計です。
さらに、使えるコンテキスト長が20万トークンから100万トークンまで伸びているのも強い。コンテキストとは、モデルが一度に覚えておける読み物の長さのことです。長いコードベースや複数ファイルをまたぐ推論では、ここが効きます。IDORのような問題は、認可ロジックが別ファイルに散っていることも多いので、長い文脈を保てるのはかなり大きい。



ベンチマークの数字も印象的です。Terminal-Bench 2.1では81.0、SWE-bench Proでは62.1。前者はClaude Opus 4.8の85.0にかなり近く、後者でもトップ層に食い込んでいます。
Semgrepが強調したいのは、これが「新興の open-weight モデルだから弱い」という雑な見方を崩している点でしょう。実際、GLM 5.2は素の状態でもかなりやれる。セキュリティの世界では、「閉じた巨大モデルだけが正義」ではない空気が少しずつ現実味を帯びてきた、そんな感じがします。


個人的にいちばん面白かったのは、この記事が“モデル戦争”を煽る記事に見せかけて、実際は「周辺設計の価値」を再確認させる内容だったことです。
AIエージェントはモデルが賢ければ勝てる、と思いがちですが、現実には違います。何を読ませるか、どう検索するか、どこで止めるか、どうループするか。こういう地味な設計が結果を左右する。Semgrepの自社パイプラインが強いのも、その積み上げの結果でしょう。

.jpg)

だからこそ、GLM 5.2の健闘は“ハーネスなしでも戦えるモデルが増えてきた”というサインとして読むのが自然だと思います。セキュリティ用途では、機密性、コスト、性能のバランスが厄介です。そこに open-weight の有力候補が増えるのは、かなり大きい変化ではないでしょうか。

![]()
![]()
![]()
![]()
![]()
参考: We have Mythos at Home: GLM 5.2 beats Claude in our Cyber Benchmarks
![]()
![]()
![]()
