Oppoが発表した「X-OmniClaw」は、Androidスマホの上で直接動くAIエージェントです。
AIエージェントというのは、ただ会話するだけのチャットボットではなく、画面を見て、必要ならアプリを開いて、操作までやってくれる“実行型AI”のことだと思ってください。
これ、地味に見えてかなり重要です。というのも、最近のモバイルAIは「実はスマホの中で動いていない」ことが多いからです。多くはクラウド上のサーバーで仮想的なAndroidを動かし、そこにAIがログインして操作します。
便利そうに聞こえますが、実際の自分のカメラ、写真、ローカルファイル、今見ている画面とはつながりません。要するに、“自分のスマホのコピー”を遠隔操作しているようなものです。

X-OmniClawは、その逆をやろうとしているわけです。
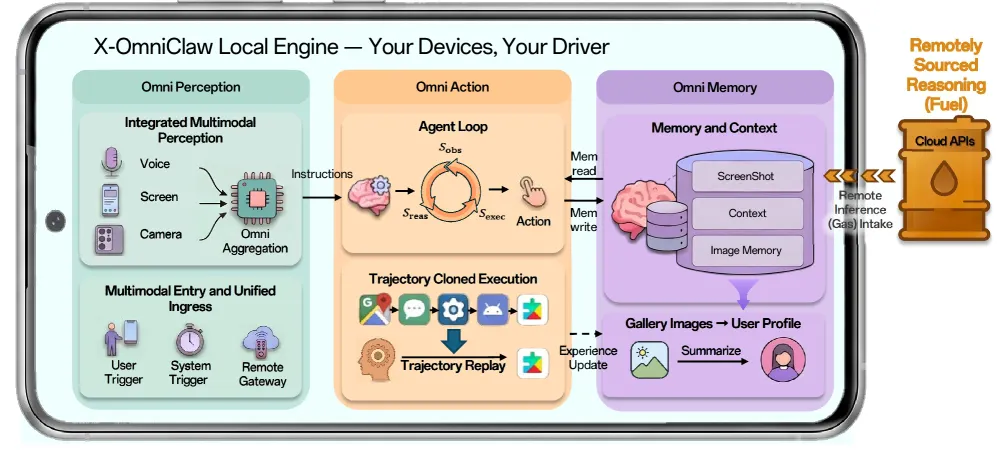
Oppoの技術レポートによると、これは「edge-native architecture」、つまり端末側で完結する設計を採っています。クラウドは“重い推論”が必要なときだけ使い、それ以外は端末内で処理する。かなり筋がいいアプローチだと思います。
Oppoはこの仕組みを、3つの要素で説明しています。
これは「見る・聞く」役目です。
カメラ映像、画面の内容、音声入力をひとつの流れとして扱い、まず状況を理解します。
![]()
たとえば、カメラでボトルを映しながら「これいくら?」と聞いたら、AIはまず“何を見ているか”を理解し、そのあとで買い物アプリを開いて探し始める、という流れです。
ここで大事なのは、単なる画像認識ではなく、「今の状況」をまとめて読むこと。AIっぽさが一気に実用寄りになります。
これは「動く」役目です。
画面上のどこをタップすべきか、どうスクロールすべきかを判断して実行します。
ここで使われるのが、XMLの画面情報、on-deviceのvisual model、OCRです。
OCRは、画像の中の文字を読み取る技術のこと。広告だらけのアプリ画面みたいに、見た目だけではボタンの位置がわかりにくい場面で役立ちます。
![]()
個人的には、ここがいちばん現実的で面白いと思いました。AIは賢くても、実際のスマホ画面って広告やポップアップだらけでかなり意地悪なんですよね。そこをちゃんと突破しようとしているのが良いです。
さらに「behavior cloning」という機能もあります。
これは、一度自分がたどった操作手順を記録しておき、次回からAIがそのルートを再現する仕組みです。しかもAndroid deeplinkを使えば、アプリ内の深いページへ一気に飛べます。
毎回「アプリを開く→メニューを押す→さらに探す」という作業を繰り返さなくていいのは、かなり気持ちよさそうです。
これは「覚える」役目です。
X-OmniClawは、タスクの途中でアプリをまたいでも、セッションが変わっても文脈を保持します。さらに、写真ギャラリーから長期的なsemantic memoryを作るとしています。
![]()
semantic memoryは、ざっくり言うと「画像や出来事を意味のあるメモとして覚える記憶」です。
ただ写真を保存するだけではなく、「この場所でこのイベントがあった」「この物体はこれ」といった情報として整理するイメージです。
ここはかなり未来っぽいです。
スマホの写真って、撮った瞬間は大事でも、あとから探すのが大変なんですよね。もしAIがそれを文脈ごと覚えてくれるなら、「昔の写真から関連するものを探して、次の作業に使う」という流れが自然になります。これは単なる便利機能ではなく、スマホの使い方そのものを変える可能性があると思います。
Oppoはデモ例をいくつか示しています。
![]()
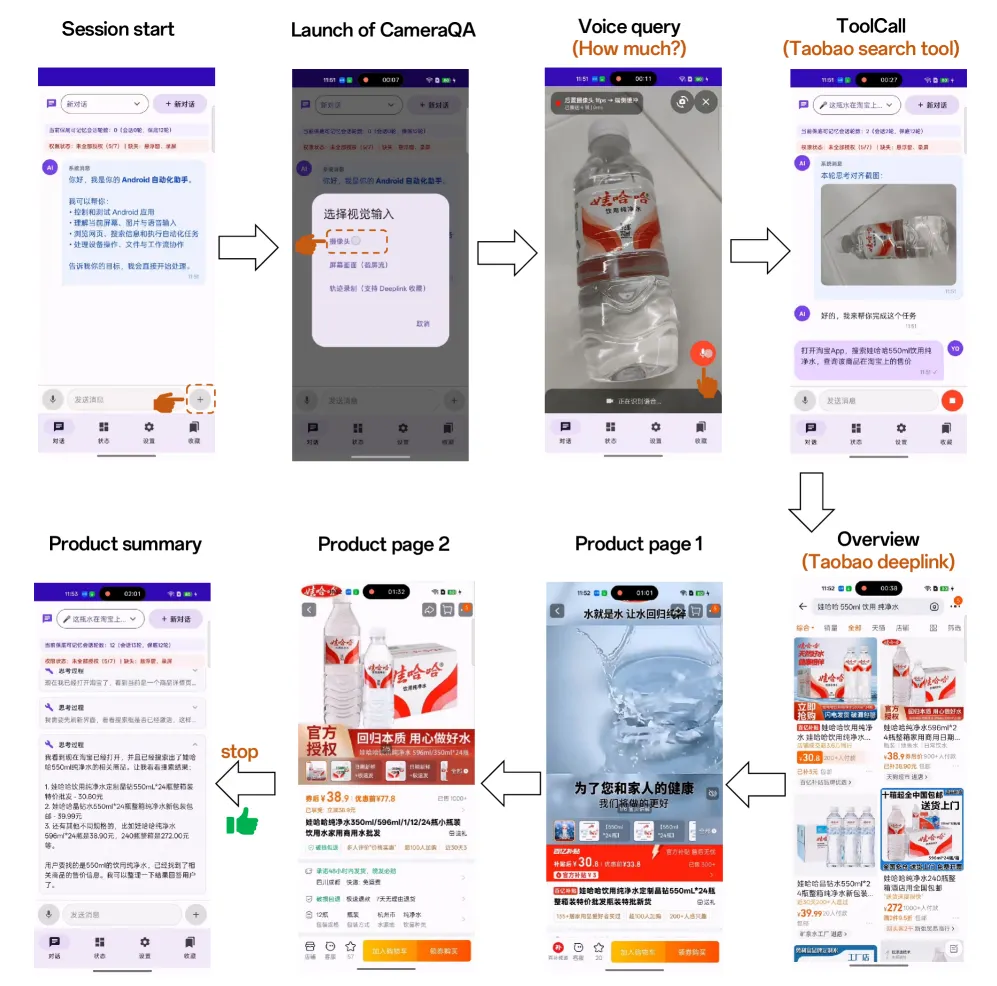
たとえば、実物の商品をカメラで映すと、AIがそれを識別してTaobaoを開き、検索結果を見て価格をまとめて返す。
ユーザーはほとんど入力しなくていい。これはかなり「AIアシスタント」っぽい使い方です。
数学の問題を画面上で解くのを、AIが横で手伝うデモも紹介されています。
画面を読み取り、問題を処理し、終わったら次へ進む。
家庭教師というより、“スマホの中の補助輪”みたいな感じかもしれません。

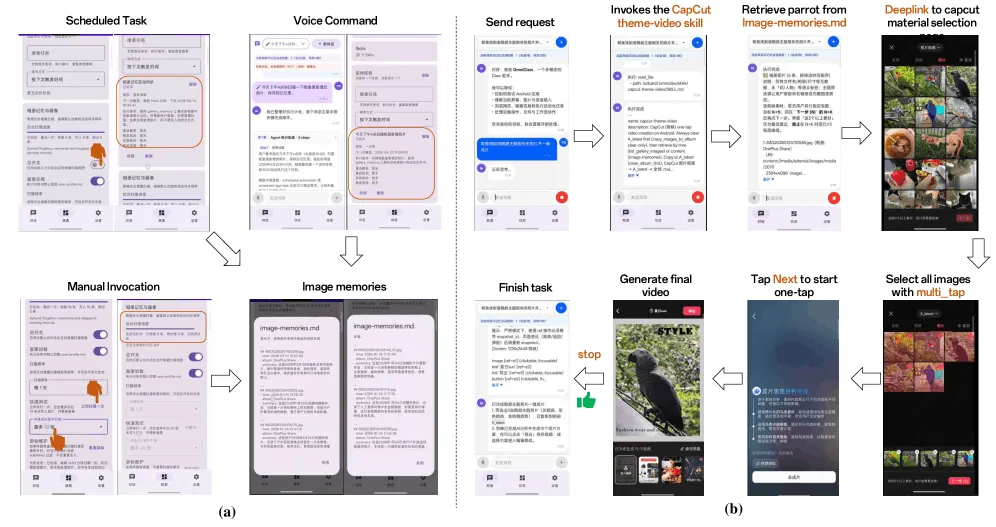
さらに面白いのが、パロット関連の写真を使ってハイライト動画を作る例です。
AIがギャラリーを見て、semantic memoryを使って関連画像を探し、CapCutの動画編集機能をdeeplinkで開き、複数ファイルをまとめて選んで動画化する。
本来なら数分以上かかる作業が、かなり自動化されるわけです。
正直、これが本当に安定して動くなら、かなりすごいです。
スマホって「やればできるけど面倒だからやらない」ことが多いので、その面倒をAIが肩代わりしてくれるのは大きいです。
AIエージェントは今、かなり注目されている分野です。
記事では、PC向けのOpenClawやHermes Agentの流れにも触れています。OpenClawはオープンソースのエージェントフレームワークとして大きく広まり、Hermes Agentは自己改善型の学習ループを持つことで注目されました。
ただ、これらは主にデスクトップ向けでした。
X-OmniClawが新しいのは、同じ発想を「いつも持ち歩くスマホ」に持ってきたところです。
ここが本質だと思います。
AIが賢いだけでは足りなくて、いちばん使う端末で、リアルな画面、リアルな写真、リアルな音声を扱えることが重要なんですよね。
クラウド上のコピーではなく、自分の手元の端末で完結するからこそ、実用性が出る。これはかなり大きい差です。
もちろん、記事だけを見る限り、X-OmniClawがどこまで実運用で安定するかはまだ未知数です。
AIエージェントは、デモでは気持ちよく動いても、実際にはアプリのUI変更、広告表示、通信遅延、誤認識などで簡単にコケます。
それでも、今回の方向性はかなり好感が持てます。
「全部クラウドで処理する」のではなく、端末内でできることを増やし、必要なときだけクラウドを使う。しかもオープンソースで公開する。
この姿勢は、単なる製品デモ以上の意味があると思います。
X-OmniClawは、スマホを「話せる端末」から「見て、聞いて、動ける端末」へ進化させる試みです。
しかも、その中心をクラウドではなく端末側に置いているのがポイントです。
個人的には、AIの未来は“巨大なクラウド頭脳”だけではなく、こういう“端末にしみ込んだAI”にあるのではないかと思います。
毎日触るスマホが、ただのアプリの箱ではなく、ちゃんと空気を読んで手を動かしてくれる存在になる。そう考えると、かなりワクワクします。
参考: This Open-Source Phone AI Agent Sees, Hears and Acts—All Without Touching the Cloud - Decrypt
