この記事でNathan Lambertが言っているのは、GLM-5.2は「ちょっと良くなった新モデル」ではなく、オープンモデルの見方そのものを変える出来事だ、という話です。
最初はいつもの版番号アップに見えます。GLM-5.1の次なら、せいぜい順当な改善だろう、と。ところが実際には、かなり多くの人が使ってみて「これ、もう普通に強いじゃん」となった。ここが本題です。
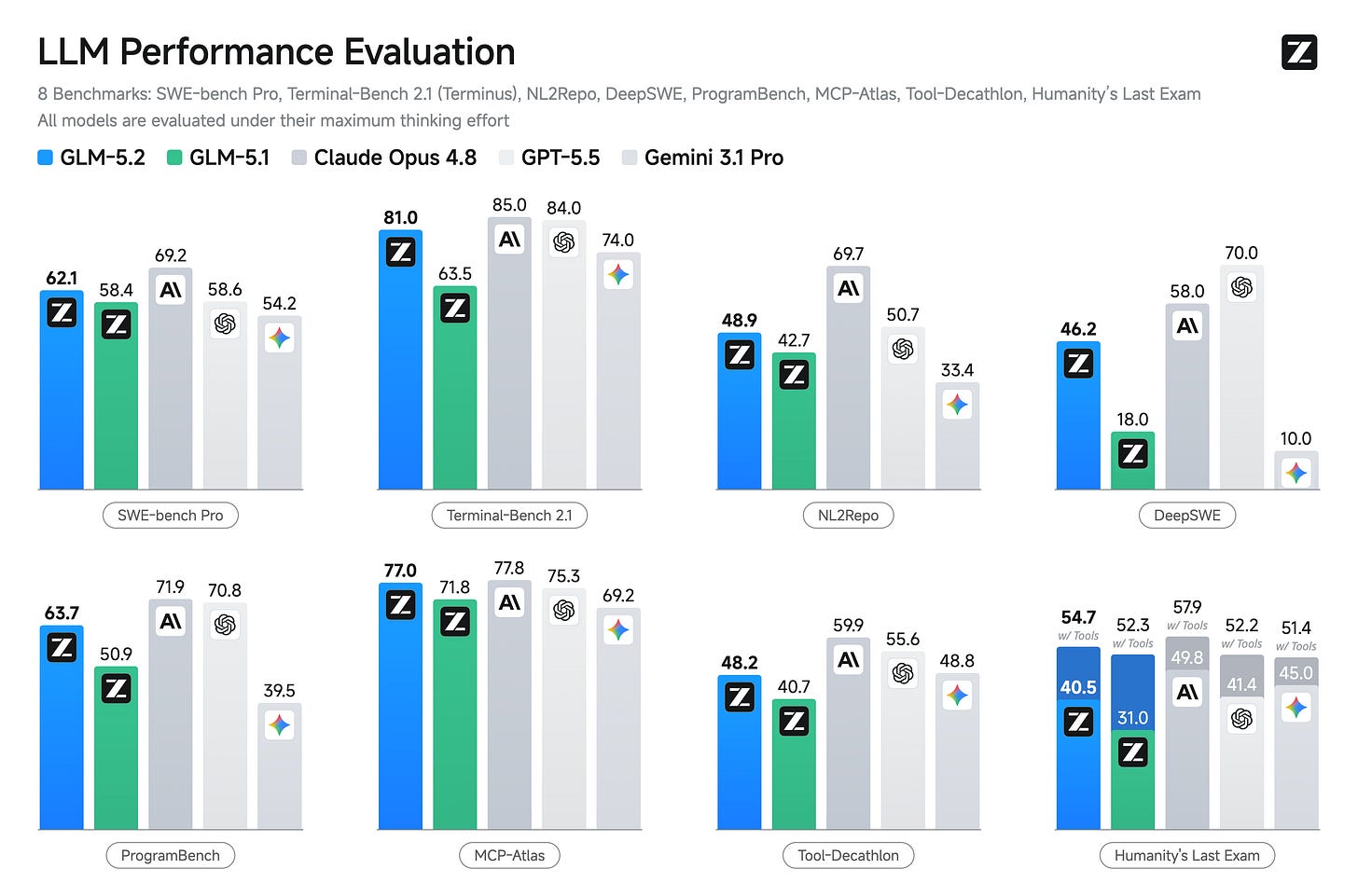
Lambertは、こういうときベンチマークの数字だけを追うのは危ないと言っています。AIの世界では、テストの点が良くても、実際に仕事で使うと全然ダメ、ということが珍しくないからです。逆に、公開直後の公式発表が地味でも、現場で触った人たちが一斉に騒ぎ出すときは、本当に“何か”が起きています。GLM-5.2はまさに後者だった、という見立てです。
面白いのは、この記事が「性能が高い」ことよりも、「open agentとして自然に使える」ことを強く評価している点です。
ここでいうagentは、単にチャットで答えるだけでなく、タスクを分解し、ツールを使い、コードを書き、必要なら何度もやり直す“作業者”のようなAIのことです。AIは賢いだけでは足りません。長い文脈を追い、道具を扱い、途中でつまずいても戻れるか。そこが本当に重要です。GLM-5.2は、その実戦的な部分で「しっくりくる」と感じられた、と著者は言います。
特に大きかったのは、コミュニティでの反応です。
公開後、Arena系のランキングやDesign Arenaのような評価で、OpenAIやAnthropicの最新モデルと真っ向から並ぶ、あるいは一部では上回る結果が出た。しかも、実際に触った研究者や評論家たちの評価がかなり好意的だった。ここまで揃うと、ただの宣伝では済みません。DeepSeek R1が出たときに近い空気があった、というのが著者の感覚です。私はこの手の「空気」は軽く見ないほうがいいと思っています。AIの進歩って、最後はコミュニティが“これは使える”と認定した瞬間に一段進むことが多いからです。
著者が強調しているもう一つのポイントは、これがopen-weightモデルの地位を変えるかもしれない、ということです。
open-weightというのは、モデルの重み、つまり学習済みの中身を公開していて、外部で使ったり調整したりできるモデルのことです。閉じたモデルは会社の中で握られますが、open-weightは外に出ます。これまでは「openは面白いけど、最前線の仕事はまだ閉じたモデルの方が強いよね」という見方が強かった。でもGLM-5.2は、その壁をかなり崩した。著者はこれを、DeepSeek R1が「高性能推論モデルは大企業だけのものではない」と示したのに続く、大きな節目だと見ています。
ここで少し生々しい話をすると、こういうモデルが出るとまず効いてくるのは価格です。
企業は高いAPIを使い続ける理由を失っていきます。特にコード生成や社内の自動化みたいな用途では、「ちょっと高いけど、これしかない」が崩れると一気に競争が激しくなる。Lambertは、Anthropicのようなフロンティア企業の収益にも圧力がかかるだろうと見ています。これは単なる“安い代替品が出た”という話ではなく、高収益の土台そのものを削る可能性がある、ということです。
ただ、この記事が面白いのは、単純な経済競争の話で終わらないところです。
著者は、open modelが広く使われること自体は経済的には良いことだと考えています。安い知能が広がれば、いろいろな人や組織が試せるからです。でも同時に、能力が上がりすぎたopen modelは、規制や安全保障の議論をかなり難しくするとも言っています。
このあたり、かなり重い話です。
今の世界では、米国政府が「安全でない」と判断するレベルのモデルがある一方で、中国のオープンなモデルはどんどん前に進んでいる。しかも、もしその能力差が縮み続けるなら、「公開してよいAIとは何か」を社会として決め直す必要が出てきます。著者は、まだ因果関係がはっきりしているわけではないと注意しつつも、能力が上がれば上がるほど、openとclosedの境界線は政治問題になると見ています。これはかなり現実的な見方だと思います。技術の話に見えて、最後は制度の話になる。いつものAIの面倒くささがここにも出ています。
個人的にいちばん印象的だったのは、著者がGLM-5.2を「中間の性能が少し上がったモデル」ではなく、「オープンモデルの未来を先に具体化したモデル」として扱っているところです。
AI界隈では、性能差が少し縮んだくらいでは大した話にならないことが多い。でも、実際にはその“少し”が、運用現場では天と地の差になります。たとえば、ツール呼び出しが自然にできる、長いタスクで破綻しにくい、コード編集が雑すぎない、こうした差はベンチマークよりずっと大きい。だからこそ、GLM-5.2は「数字が良いモデル」より「仕事の流れに入るモデル」として評価されているわけです。
Lambertは、これからAIシステムはもっと複雑になり、モデル単体の勝負ではなくなるとも示唆しています。
計画用のモデル、コードを書くモデル、補助のsubagentを回すモデル、そんなふうに役割分担が進む。すると、あるモデルが“ちょうどいい”という感覚は、単なる賢さでは決まりません。エージェントとしての癖、レスポンスの形、失敗の仕方まで含めて評価される。GLM-5.2はその文脈で、「オープンなのにちゃんと役に立つ」最初の本命になった、というのがこの記事の核心です。
そして最後に残るのは、少し不穏だけれど大事な問いです。
もしオープンなモデルが急速に強くなり、しかも使いやすくなったら、社会はそれを歓迎するのか。それとも止めに行くのか。著者は、今のうちにインフラやメッセージング、制度設計を考えないといけないと言っています。私はこれ、かなり正しい警告だと思います。技術は勝手に前へ進むので、後から「想定してませんでした」では済まないからです。
GLM-5.2は、ただの新モデルではありません。
open-weightモデルが「研究室の外でも本当に強い」と証明し始めた、その象徴だと読むのが自然です。しかも、これが一回きりの奇跡ではなく、今後の当たり前になりそうだというのが、いちばんぞっとするし、いちばん面白いところでもあります。
