Mistral AIが公開した「Leanstral 1.5: Proof Abundance for All」は、ひとことで言うと、定理証明にかなり強いオープンなAIモデルの話です。
定理証明というと難しく聞こえますが、要するに「数学の主張やプログラムの性質を、機械がきちんと正しいと確認する」作業です。普通の生成AIが「たぶんこう」と答えるのに対して、Leanのような証明支援系では、コンパイルを通る形で論理のつじつまを合わせる必要があります。ごまかしが効かない世界です。
正直、この分野は地味に見えて、かなり重要です。
AIが賢くなればなるほど「それっぽいけど間違っている」回答も増えるので、最後に信頼できる検査役が欲しくなる。その役目を、Leanstral 1.5のようなモデルが担おうとしているわけです。私はここに、AIの次の実用領域のひとつがあると思います。


ふだんのチャットAIは、説明は上手でも、平気で間違えます。
一方で形式証明は、「その答えが本当に正しいか」を機械が厳密に見ます。ここで使われるLeanは、数学やプログラムの証明を記述するための言語です。ざっくり言えば、人間が書いた論理の筋道を、コンピュータが一行ずつ検査する仕組みだと思えばいいです。
Leanstral 1.5の面白さは、この厳しい世界でちゃんと戦えることです。しかも単に「小さな問題を少し解ける」ではなく、かなり手強いベンチマークで結果を出している。ここはかなり印象的でした。

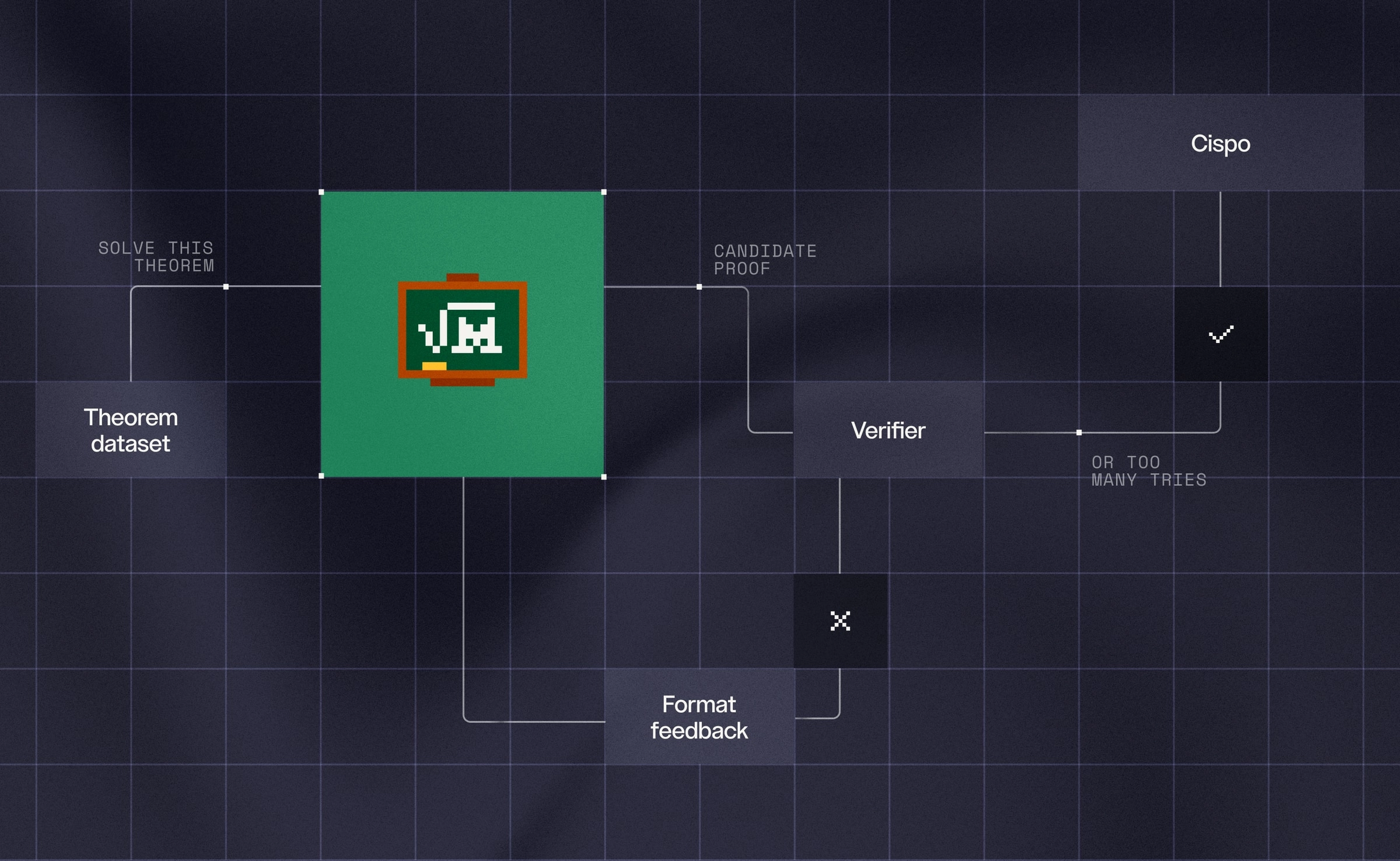
Mistralの説明を見ると、Leanstral 1.5は3段階で鍛えられています。mid-training、supervised fine-tuning、そしてCISPOを使った reinforcement learning です。
難しい名前が並びますが、言いたいことはシンプルで、最初に広く学ばせ、そのあと人間のお手本で整え、最後に試行錯誤で粘り強さを身につけた、という流れです。
特におもしろいのは、学習環境が2種類あることです。ひとつは「定理を証明するか反証するか」を繰り返す多段階の環境。もうひとつは、実際のファイルを触りながら進めるコードエージェント環境です。後者では、モデルがファイルを編集し、bashコマンドを走らせ、Lean language serverを使ってゴールやエラーを確認します。
これ、かなり現実の開発に近いです。証明問題を“解く”だけでなく、証明作業そのものを回すように訓練しているのがポイントだと思います。

しかも、証明が長引いても投げずに、何度も試し、ファイルを直し、前提を組み直して進む。その「しぶとさ」が性能に直結しているようです。AIは雑に言えば賢さより根気が効く場面があるのですが、Leanstralはまさにそこを磨いている印象があります。
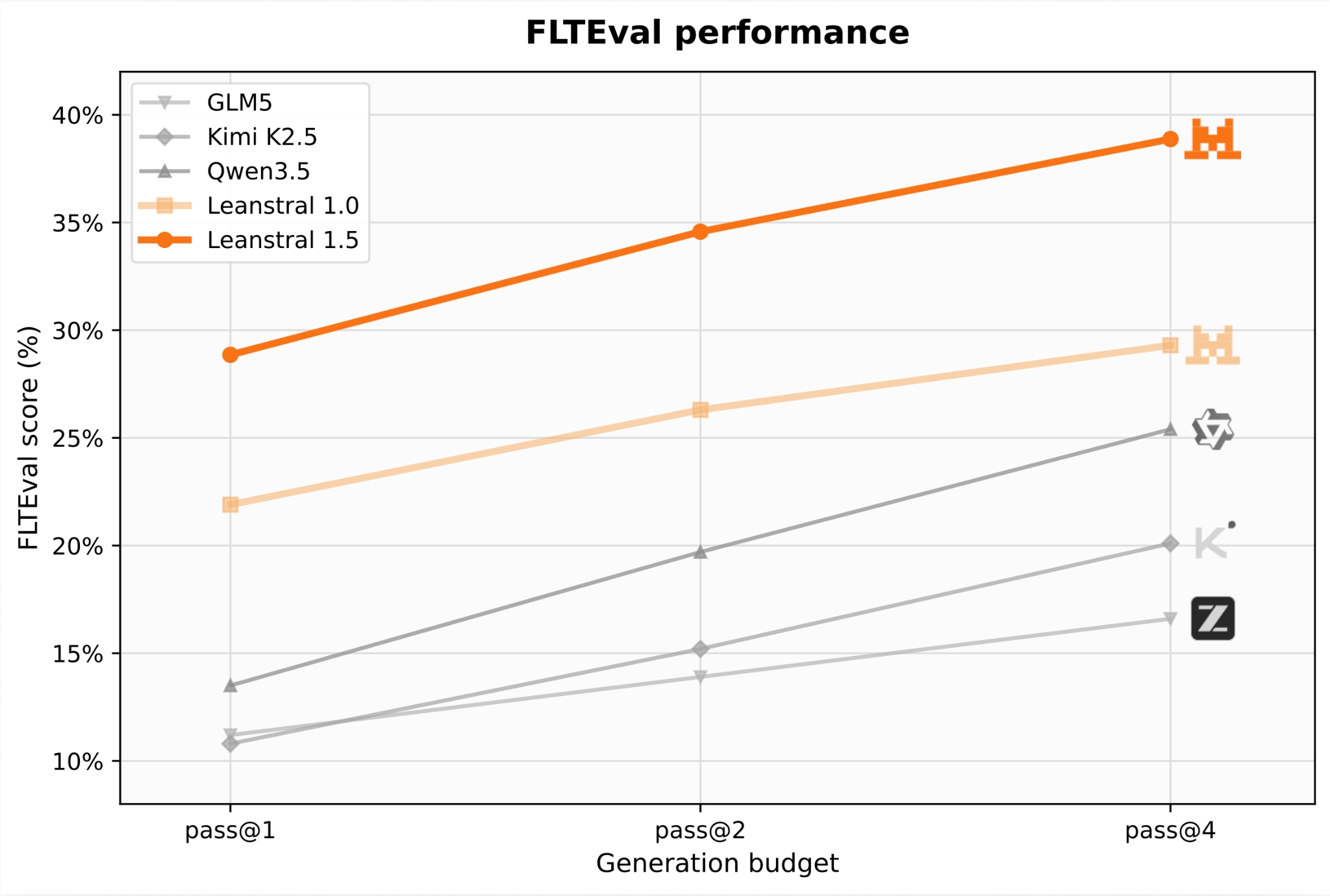
記事ではいくつかの評価指標が紹介されています。
miniF2Fは完全制覇、つまり検証用・テスト用の両方で100%に到達したとあります。PutnamBenchでは672問中587問を解いた。Putnamはアメリカの有名な数学コンテストで、簡単な計算問題ではなく、発想と長い推論が必要です。ここでこの数字はかなり目立ちます。
![]()
FATE-HとFATE-Xでは、それぞれ87%、34%で新しい最高性能。ここは抽象代数学、つまり群・環・加群といったかなり理屈っぽい分野のベンチマークです。一般向けに言えば、「考えが複雑に絡む数学でも、筋道を崩さずに進める力」が問われる領域です。
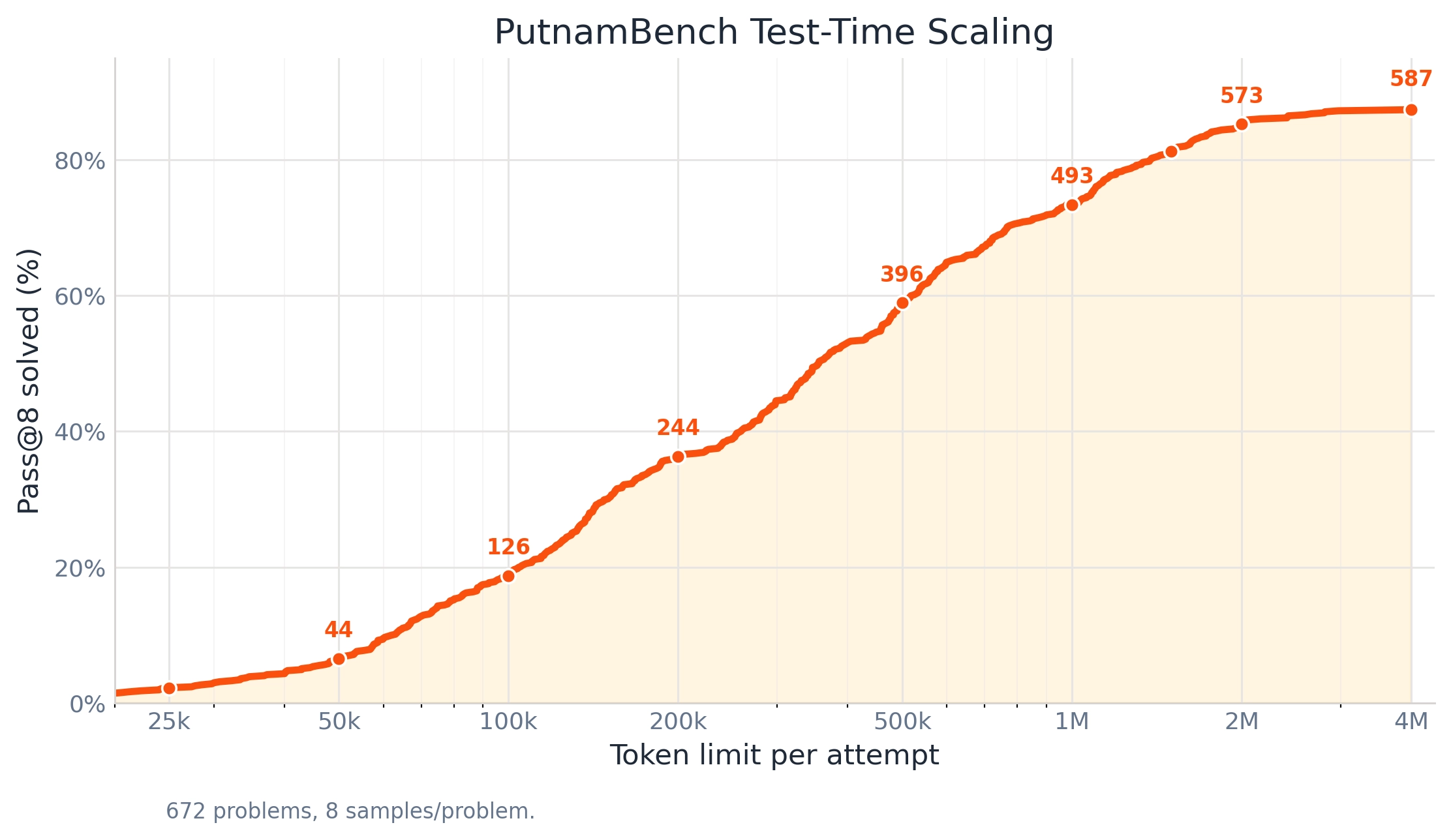
個人的には、ここで重要なのは単なるスコアよりも、test-time scaling が効いている点です。
要するに、与えるトークン予算を増やすと、性能がかなり素直に伸びる。記事では、PutnamBenchで25kから4Mまで予算を増やしたときに、解ける問題数が滑らかに増えていく様子が示されています。これは「もっと考えさせれば、まだ伸びる」タイプのモデルだということです。
私はこういう性質のモデルは、実運用でかなり強いと思います。時間と計算資源をかけた分だけ成果が出るなら、使いどころが明確だからです。
![]()
数字で特に興味深いのが、PutnamBenchでSeed-Prover 1.5 highを7問上回りつつ、1問あたり約4ドルという説明です。比較対象のSeed-Prover側は、1問に300ドル以上かかる見積もりだと書かれています。
ここはかなり大きい差です。研究ベンチマークで「強い」だけなら珍しくないですが、強くて安いとなると話は変わります。使える場面が一気に増えるからです。
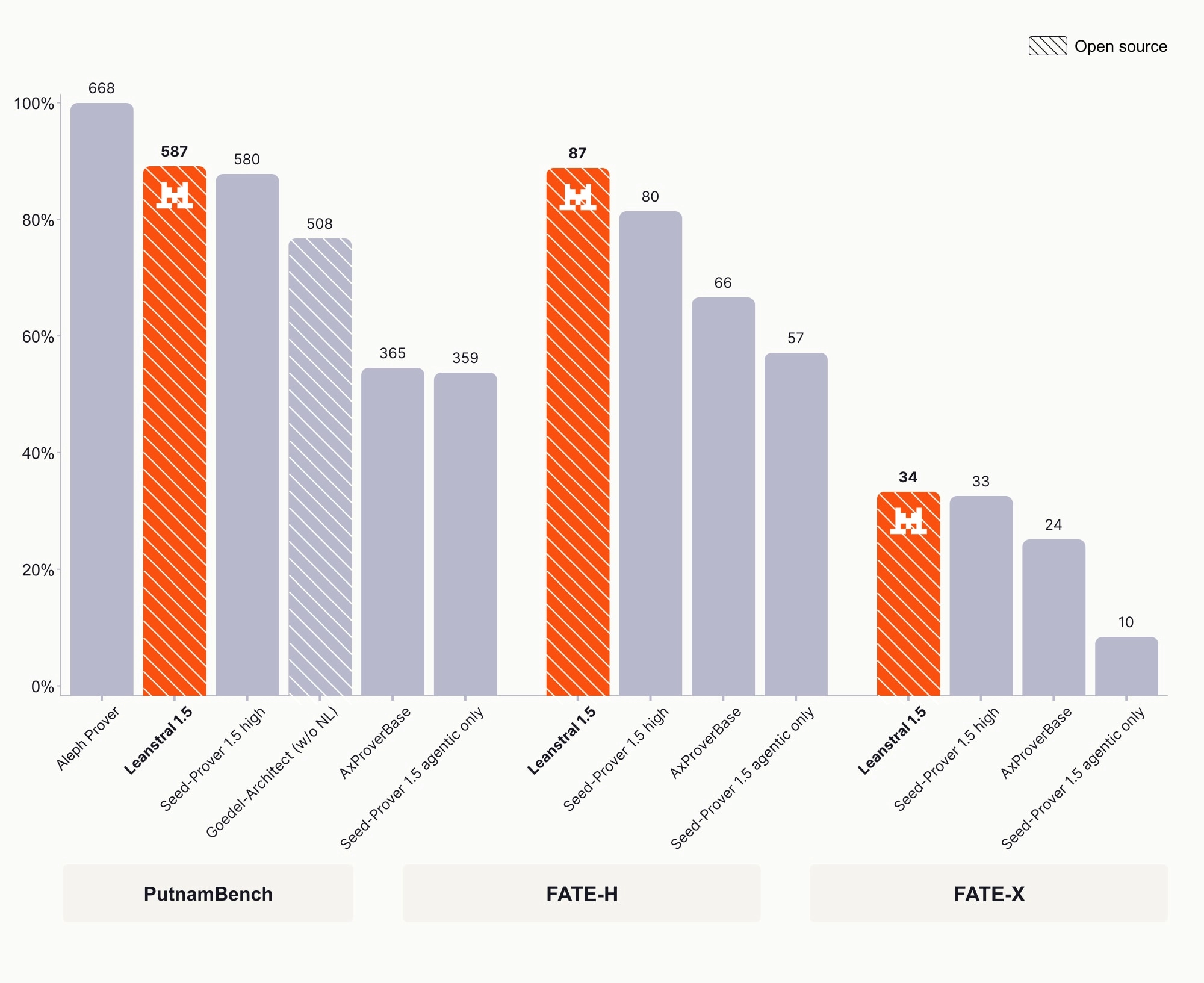
もちろん、ベンチマーク間の条件は完全に同じではありません。記事でも、上位のproverの中には自然言語のヒントをもらっているものや、かなり高コストなものがあると触れています。なので単純比較には注意が必要です。
それでも、Leanstral 1.5のコスト感はかなり魅力的です。研究室のデモではなく、実際に回す道具として見えてくる。ここが重要です。
このモデルのもうひとつの面白さは、数学専用で終わっていないことです。
記事では、実際のコードに対して「この実装はこういう性質を満たすはずだ」と証明しにいくケーススタディが紹介されています。つまり、バグを探すためのAIとしても使っているわけです。
ひとつはAVL木の時間計算量の証明。AVL木は、データを効率よく探したり追加したりするための木構造で、バランスを保つことで処理を速くしています。Leanstral 1.5は、実装に対して本当に O(log n) の性質を証明したとされています。
この手の証明は、アルゴリズムの理想形を説明するだけでは済みません。実装の細部、モナド、分岐、再帰、補助補題まで追わないといけない。かなり泥臭いです。そこを2.7百万トークン以上、22回のcompactionをまたいでやり切ったというのは、地味にすごい。
もうひとつはバグ発見です。Aeneasという仕組みでRustコードをLeanに変換し、Leanstralがそのコードの性質を推論して証明を試みる。失敗したら反証も試す。
この流れで57リポジトリを調べ、47件の性質違反を見つけ、そのうち11件が本物のバグ、さらに5件はGitHub上で未報告だった、としています。

具体例として紹介されているのが、Std.U64.MAX入力時にオーバーフローしてしまうケースです。value + 1 が桁あふれして、debugではクラッシュ、releaseでは静かに壊れる。こういうバグは、テストやfuzzingだけでは見逃されやすい。
ここはかなり実務っぽい話で、私は非常に面白いと思いました。AIが「会話」ではなく「検査」に入ると、急に価値がはっきりするんですよね。
Leanstral 1.5はApache-2.0ライセンスで、Hugging Faceでも配布されています。無料APIもある。
この手の高度なモデルは、たいていクローズドか、触るのに敷居が高いことが多いので、オープンである意味は大きいです。研究者も、ツール開発者も、Lean 4を使う人も、かなり試しやすい。
「証明できるAI」が一部の巨大企業の中だけに閉じず、外に開かれているのは、かなり健全だと思います。
もちろん、万能ではないでしょう。
形式証明の世界はそもそも難しく、問題設定も特殊です。自然言語の雑談や、ふんわりした企画書づくりにそのまま効くわけではない。けれど、正しさが命の領域では話が別です。ソフトウェア検証、数学、セキュリティ、コンパイラ周り。そういう場所では、こうしたモデルがかなり実用的になりうるのではないかと思います。
Leanstral 1.5を見ていると、AIの進化は「もっと上手にしゃべる」だけではないと改めて感じます。
むしろ、間違えにくい、粘る、検証できる方向の進化が、今後はますます効いてくるのではないでしょうか。派手さはないけれど、実はそっちのほうが社会を変える。そんな気配があります。