ノルウェー国立図書館が、ノルウェー語を理解する大規模言語モデル、いわゆるLLMを作っている――この記事の主役はこの一文に尽きます。
しかも、その裏側で使われているのが 2PB(ペタバイト) ものHuawei製フラッシュストレージ。数字だけでもかなりの迫力ですが、話の面白さは「AIを作るにはGPUだけあればいいわけじゃない」というところにあります。
![]()
元記事によると、ノルウェーの国立図書館は、ノルウェー語を理解する「主権的なAI」、つまり自国の言語と文化に根ざしたLLMを開発しています。
背景にあるのは、商用のLLM提供企業が、ノルウェー語に特化したモデルをほとんど作っていないという事情です。

ここ、かなり本質的だと思います。
今の生成AIは英語圏の情報には強い一方で、各国の歴史、ニュース、文化、しかもその国の言語で書かれた細かな文脈には弱いことがある。
「世界共通のAI」があるように見えて、実は“英語中心のAI”になっている、というわけです。
ノルウェーの文化省はこの課題を国立図書館に託しました。理由はシンプルで、国立図書館には ノルウェーの本、新聞、Webページなど、国内最大級のデジタルコレクション があるからです。
しかも法定納本制度があるため、出版物や放送コンテンツを収集・保存する役割も持っています。つまり、AIの燃料になる「国の知識の倉庫」を、最初から持っている組織なんですね。
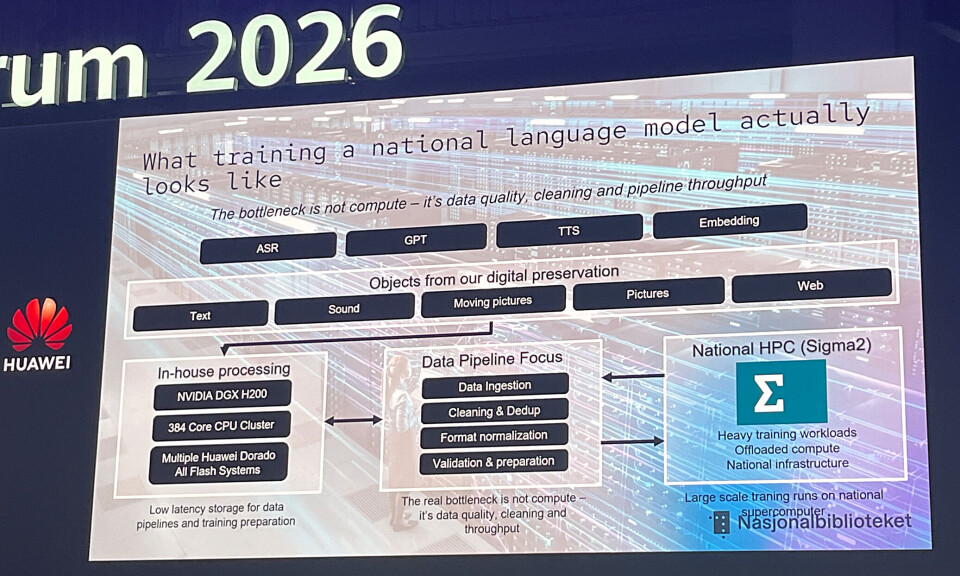
ここで出てくるのが、Huawei OceanStor Dorado という all-flash array です。
all-flash array は、ざっくり言うと「HDDではなくSSD/flashを使った高速な保存装置」のこと。データの読み書きが速く、AIの前処理や学習データの受け渡しに向いています。

記事によると、国立図書館は 合計2PBのflash capacity を持つこのストレージを、AI training data pipeline に使っています。
この pipeline というのは、データを集めて、きれいにして、重複を消して、形式をそろえて、検証して、学習できる形に整える流れのことです。

ここが地味に重要です。
LLM開発というと、みんな「GPU何千枚!」みたいな話を想像しがちですが、実際には 学習前のデータ整備がめちゃくちゃ大変 です。
むしろ、この記事では「ボトルネックはcomputeではなく、data quality、cleaning、pipeline throughputだった」と明言されています。つまり、計算資源よりもデータの中身と流れのほうが詰まりやすい。
これはかなりリアルです。AIは魔法ではなく、大規模な“お掃除と仕分け”の延長線上にある、という感じがします。

国立図書館は、2005年からコレクションのデジタル化を進めてきました。
その結果、20PBのユニークデータ を保有し、それを 3-2-1形式 で保存しているそうです。

3-2-1というのは、
という、データ保護の定番ルールです。
なので、20PBのユニークデータがあると、全体では 約60PB になる計算です。これはもう「図書館」というより、国家レベルの記憶装置ですね。

ただし、ここで大事なのは、保存用システムとAI用システムは求められる性質がまったく違う ことです。


つまり、「昔からある保存庫」から「今まさに学習に使う作業場」へ、大量データをどう運ぶかが難しい。
この記事でも、PB規模のデータをアーカイブからAIパイプラインへ移す問題について、誰も十分に語っていなかった とされています。
たしかに、ここは見落とされがちです。AIの話なのに、実際は“巨大な引っ越し作業”に近い。しかも引っ越し先では、荷物をただ置くだけでなく、すぐ使える形に整理しないといけないわけです。

記事では、処理は大きく2段階に分かれています。
ここでは、

が使われています。
この段階で、データの取り込み、クリーニング、重複排除、形式の正規化、検証、学習用の準備が行われます。
要するに、LLMに食べさせる前の下ごしらえです。
生の本、新聞、Webページ、音声、動画、画像、メタデータなどが混ざった巨大な素材を、そのまま学習に放り込むわけにはいきません。
OCR(文字を画像から読み取る処理)も多く必要だったようで、文字起こしの精度も当然効いてきます。

前処理を終えたデータは、ノルウェーの国立スーパーコンピュータ Sigma2 Olivia に送られ、そこで実際の training runs が行われます。
このシステムは HPE Cray Supercomputing EX ベースで、448 GPUs と 64,512 CPU cores を搭載。ストレージは 5.3PBのCray ClusterStor E1000 です。
GPUの数だけ見ると、さすが国家プロジェクトという感じです。
でも個人的には、むしろ「学習の前にここまでデータを整える必要がある」という事実のほうが面白いです。AIは、派手な計算の前に、かなり泥臭いデータ作業を食べて成り立っているんだな、と再確認させられます。


記事の後半で挙げられている課題も、かなり重要です。というか、ここが本丸かもしれません。
ノルウェー語の国産LLMを評価する標準ツールがまだないそうです。
さらにノルウェー語は、2つの書き言葉 があり、方言も多く、歴史的変化もある。
つまり、「このLLMは良い」と判定するのが、英語よりずっと難しい。

なのでチームは、評価ツールも自作している とのこと。
これは地味ですが、とても大きい話です。モデルを作るのはスタート地点で、本当に難しいのは「どう良し悪しを測るか」なんですよね。
「誰がこの主権的LLMへのアクセス権を持つのか」「何に使ってよいのか」を誰が決めるのか。
これは技術というより、制度や政治の問題 です。

たしかに、国の文化資産から作ったAIなら、誰でも自由に商用利用していいのか、という話は簡単ではありません。
ここは“便利だから作れば終わり”では済まない。AIに管理者、つまり custodian が必要だという指摘はかなり的確だと思います。
保存アーカイブ、オンプレのAI環境、国家スーパーコンピュータの 3つのシステムを滑らかにつなぐ のが継続課題。
これも、実務ではすごく厄介です。
組織が違い、目的が違い、性能特性も違うシステムをつなぐのは、技術だけでなく運用設計そのものの勝負になります。

個人的に面白いのは、この記事が「AIの話」に見えて、実はかなり ストレージとデータ基盤の話 になっていることです。
しかも、その中心にあるのが“ノルウェー語”という、すごくローカルなテーマなのがいい。

世界中が同じLLMを使うようになると便利そうに見えますが、実際には言語や文化の違いが無視できない。
ノルウェーのような非英語圏の国が、自分たちの言語で、自分たちの歴史や文化を反映したAIを作ろうとすると、必要なのはモデルだけではなく、

まで全部含まれる、ということがよくわかります。
Huawei storage が欧州市場でかなり存在感を持っている、というのも記事のまとめとして触れられていました。
そこは政治的・商業的な含みもある話ですが、少なくともこの記事が示しているのは、AIインフラは“どのGPUを使うか”だけで語れない ということです。

ノルウェー国立図書館の取り組みは、単なる「国産LLMの開発事例」ではありません。
むしろ、自国の言語と文化を守りながらAIを作るには、データの保管、移送、整備、評価、統治まで含めた総力戦になる という現実を見せてくれます。
.svg)
そして、そこに2PBのHuawei flash storageががっちり噛んでいる。
派手さはGPUに負けるかもしれませんが、実際にはこういう基盤こそがAIを支えている。個人的には、かなり“わかっている”話だと思いました。
AIの時代は、モデルを作る人だけでなく、データを守り、整え、渡す人が主役になる――この記事はそんなことを静かに教えてくれます。
.svg)
参考: Norway’s 2 petabytes of Huawei flash storage and LLM training
