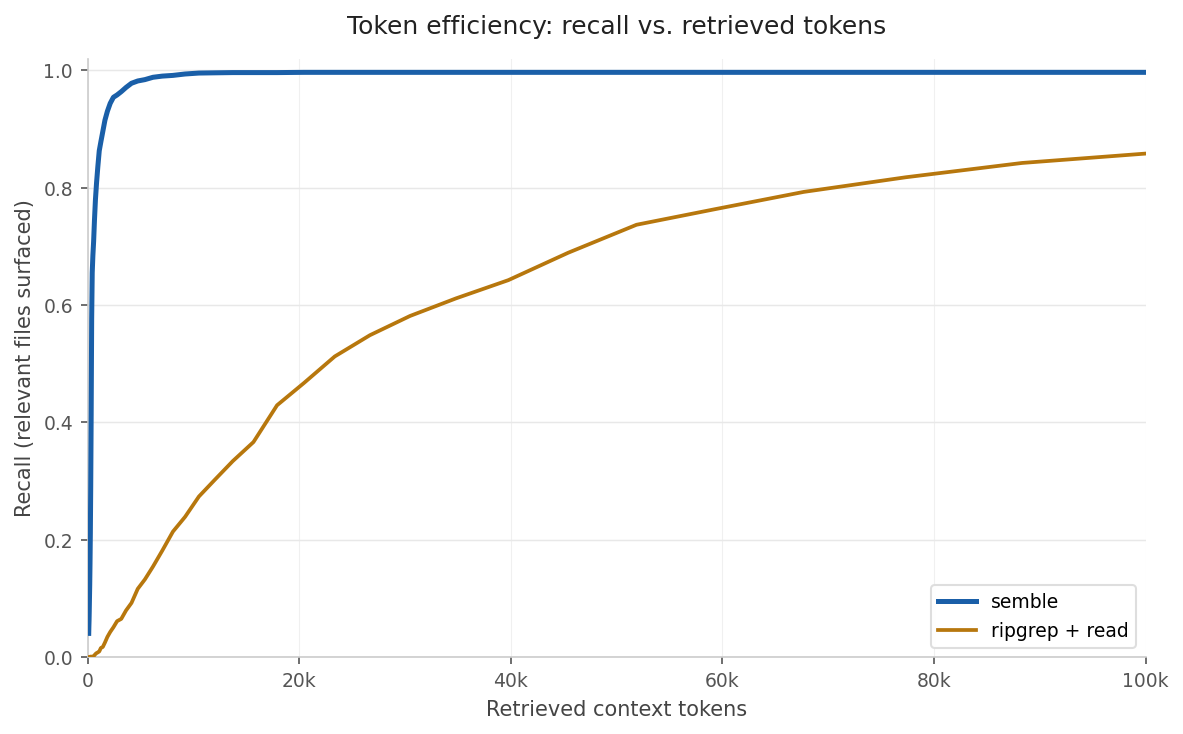
grep + read より 約98%少ない token で必要なコード断片を返すAGENTS.md を使って、Claude Code や Cursor などの agent から使えるGitHubで公開されている Semble は、ひとことで言うと「AIエージェントのためのコード検索エンジン」です。
ここでいう AIエージェントは、Claude Code や Cursor、Codex みたいに、コードを読んで修正案を考えたり、関連箇所を探したりする“賢い開発アシスタント”のことです。
こういうエージェントにとって、いちばん地味だけど重要なのが どこに目的のコードがあるか素早く見つけること なんですよね。
普通は grep で文字列を探して、見つかったファイルを read で開く、という流れになります。
ただ、このやり方はシンプルな反面、大量のファイルや長いファイルを読むと token をかなり消費する のが弱点です。LLM系のエージェントにとって token は「読み書きできる量」みたいなものなので、無駄に食うとかなり痛い。
Sembleはそこをかなり真正面から改善していて、必要なコード片だけを返す ことで、grep + read に比べて 約98%少ない token で済む、としています。これはかなり野心的で、正直おもしろいと思いました。
SembleのREADMEで強調されているポイントは次の通りです。
このへんを見ると、Sembleは「単なる検索ライブラリ」ではなく、エージェントの作業効率を上げるための実用品として設計されているのがわかります。ここが重要です。
個人的にいちばん魅力を感じるのは、**“エージェントにちょうどいい情報量”を返す設計**です。
コード検索って、昔からある問題なのに、AIと組み合わせると急に難しくなるんですよね。
人間なら検索結果が多少多くても「まあ、ざっと見ればいいか」で済みます。でもAIは、読む量が増えるとすぐ token を食い、文脈が散らかり、結果として精度も落ちやすい。
Sembleは、そこを「全文を読ませる」のではなく、必要な断片だけを返す という発想で解いています。
この考え方はかなり筋がいいと思います。AIに大量のコードを丸投げするより、最初から狙い撃ちで絞るほうが賢い。人間のペアプロでも、まず関連箇所だけ見せてもらえたほうが助かりますしね。
![]()
READMEでは、Sembleは自然言語で検索できると説明されています。
たとえば、
"authentication flow""save_pretrained""save model to disk"のようなクエリを投げると、grep のように単語一致だけで探すのではなく、「その機能を実装している場所」っぽいコード断片を返してくれます。
これは地味ですが、実はかなり大きいです。
たとえば「認証の流れどこだっけ?」というとき、文字列として auth が入っている場所だけでは不十分なことが多い。login、session、token、middleware など、関連語はたくさんあります。Sembleのようなツールは、そこを意味ベースで探すのが売りです。
find_related も面白いSembleには find_related という機能もあります。これは、あるファイルと行番号を指定すると、そこに似たコードを探してくれるものです。
これ、かなり便利そうです。
「この関数と似た実装を他にも探したい」とか、「同じパターンを別の場所でどう書いているか見たい」という場面は多いです。
コードベースが大きくなるほど、こういう“似たもの探し”の価値は上がります。個人的には、単純検索よりこっちのほうが AI 時代っぽいなと思いました。
Sembleは MCP server として動かせます。MCPは、ざっくり言うと「AIツールが外部機能とやり取りするための共通の接続口」みたいなものです。
これを使うと、Claude Code や Cursor などから Semble を呼び出せます。
さらに README では、AGENTS.md や CLAUDE.md に設定を書いて、Bash 経由で使う方法も案内されています。
つまり、エージェントに“コード検索の標準装備”として組み込める わけです。
これが何を意味するかというと、エージェントが何かを調べるたびに、毎回雑に全ファイルを読む必要がなくなる、ということです。
AI開発のボトルネックって、意外とモデルの賢さそのものより、適切な情報を適切な量だけ渡すことだったりします。Sembleはその問題にかなり正面から取り組んでいる印象です。
READMEには、次のような数字が書かれています。
この手のベンチマークは、もちろん条件を見ないと断言しすぎは禁物です。
ただ、それでも「速さ」と「精度」を両立しようとしているのはわかります。検索ツールって、速いだけだと雑、精度だけ追うと重い。そのバランス調整が難しいんですよね。
その意味で、Sembleはかなり実戦志向のプロダクトに見えます。
Sembleは、特に次のような人に向いていそうです。
grep では拾いきれない“意味での検索”を試したい人逆に言うと、「とにかく何でも全文検索したい」「細かい文字列一致だけで十分」というケースなら、そこまで強く刺さらないかもしれません。
でも、AIエージェントと組み合わせるなら、かなり理にかなっていると思います。
Sembleのいちばんの魅力は、AI時代のコード検索をちゃんと“エージェント基準”で作っていることだと思います。
従来の検索ツールは、人間が使う前提でできています。
でも今は、コードを読む主体が人間だけじゃなくなってきた。AIが“先に探して、絞って、必要なところだけ読む”時代です。
そのとき、検索ツールの設計も変わらないといけない。Sembleは、その変化をかなり素直に受け止めている感じがします。
「98% fewer tokens」という数字は派手ですが、単なるキャッチコピーというより、AIに無駄を読ませないための設計思想の表現として見ると納得感があります。
この方向性は今後もっと重要になるんじゃないか、と思いました。
Sembleは、AIエージェント向けに最適化された、速くて軽くて実用的な code search library です。
grep + read のような従来型の検索よりも、関連するコード断片だけを素早く返すことで、トークン消費を大きく抑えられるのが強みです。
しかも CPU だけで動き、外部サービスも不要。
MCP server や AGENTS.md と組み合わせれば、Claude Code や Cursor などの agent に“賢い目”を与えるような使い方ができます。
AIがコードを書く時代だからこそ、コードをどう探すかの価値が上がっている。
Sembleは、その変化にかなりうまく乗っているプロジェクトだと感じました。
