この記事、かなり好きです。理由は単純で、「お金をかければ解決する問題」を、中古パーツと少しの工夫でねじ伏せているからです。
著者はもともとRTX 4080を持っていました。16GBのVRAMは、ゲーム用途なら十分です。でも、最近の大きめのLLMをローカルで動かそうとすると、16GBでは足りなくなることが多い。ここがまずポイントです。
LLMは「賢さ」だけでなく、モデルの重さをどれだけGPUメモリに載せられるかが超重要です。VRAMが足りないと、そもそも動かなかったり、極端に遅くなったりします。
そこで著者が選んだのが、普通の人ならまず思いつかない方向。
データセンター向けGPUを中古で買って、デスクトップPCに載せるという力技です。
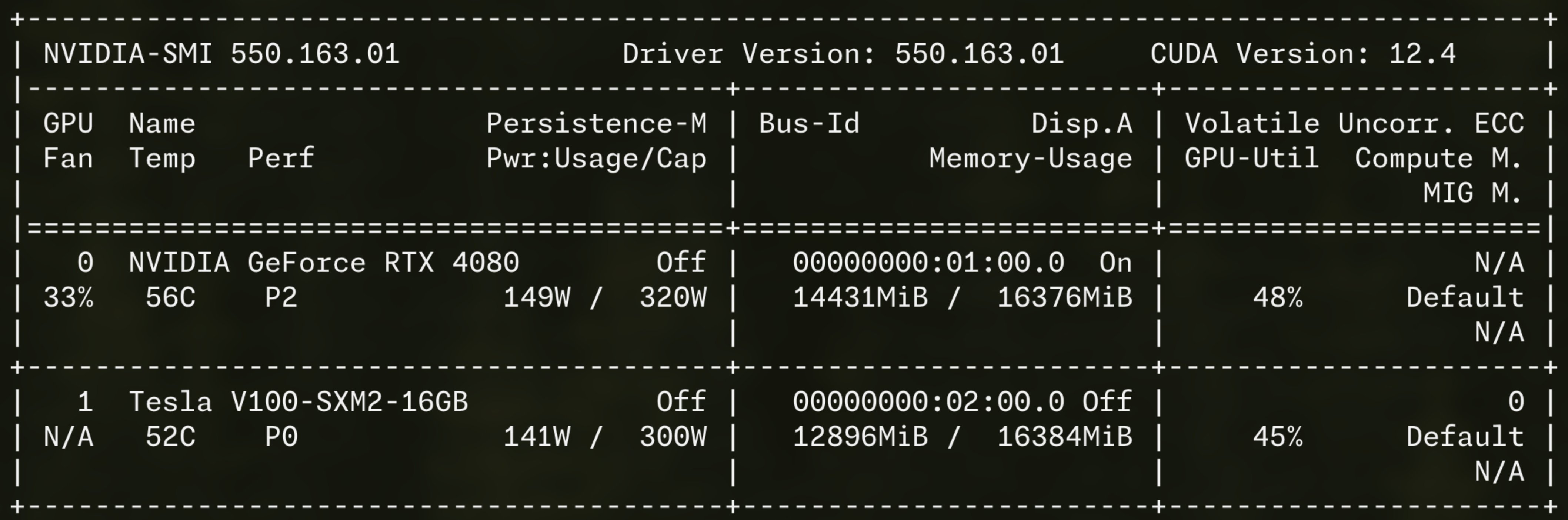
買ったのは Tesla V100 SXM2 16GB。
これはNVIDIAのデータセンター向けGPUで、DGXサーバーや大規模ラック向けに作られたものです。
普通のGPUと違って、かなりクセがあります。
つまり、そのままではPCに挿せません。
ここで必要になるのが SXM2-to-PCIe adapter です。要するに、「サーバー用GPUを、無理やりデスクトップで使うための変換基板」です。

著者はV100本体を約£150、アダプタを約£50で購入。
合計で 約£200。かなり安いです。中古市場ならではの面白さですね。
この話の本質は、単に「安いGPUを買った」ことではありません。
16GBのVRAMを追加したことにあります。
RTX 4080の16GBと、V100の16GB。
これで合計32GB。しかも、LLMの推論ではメモリ帯域幅(データをどれだけ速くやり取りできるか)も効いてきます。
記事では、V100の HBM2 がかなり強いと説明されています。
HBM2は、ざっくり言えば超高速なGPUメモリです。V100は 900 GB/s の帯域幅を持ち、RTX 4080の 736 GB/s を上回る。2017年のGPUが、2022年のカードよりメモリ帯域で強いというのは、ちょっとロマンがあります。古いけど侮れない、まさにそういうやつです。
もちろん、最新のRTX 5090みたいなモンスターには負けます。
でも、2,000ポンド超のGPUと戦うために200ポンドで対抗するという発想が、かなり痛快です。
ここ、地味に一番おもしろいです。
データセンターGPUだからといって、静かで上品なわけがない。むしろ逆です。
V100はサーバー内で強制冷却される前提なので、アダプタについているファンがとにかくうるさい。
著者はこれを 82dB と測定しています。これは、かなりざっくり言うと掃除機や芝刈り機に近い世界です。寝室に置く音ではありません。かなり嫌です。率直に言って、こんなのが机の横で回っていたら集中できないと思います。

しかも厄介なのは、最初はファンを制御できなかったこと。
nvidia-smiでもダメ、WindowsのAfterburnerでもダメ。
つまり「うるさいならソフトで回転数を下げればいいでしょ」が通じない。
そこで著者は、配線を調べ、9V電池でファンを試し、PWM制御が効くことを確認します。
PWMというのは、電圧を細かく切り替えて回転数を制御する仕組みです。普通のPCファンでも使われています。
最終的には、マザーボードのファンヘッダにつなげることで制御可能にし、10%程度の回転数でも50℃を超えない状態まで持っていったそうです。
これはかなり気持ちいい成功体験だと思います。
「うるさい産業機械」を「ちゃんと使える道具」に変えた感があります。
ファン問題を解決すると、V100はRTX 4080の隣にそのまま入りました。
ここで使っているのが llama.cpp の tensor splitting です。
これは、モデルの計算を複数GPUに分けて実行する仕組みだと思えばOKです。
1枚のGPUに全部載せるのではなく、レイヤーを分担するわけです。
もちろん、単一の32GB GPUに全部載せるよりは遅くなります。
でも、「そもそも載らない」よりは圧倒的に良い。
この記事はずっとこの思想です。高級品を買うのではなく、載るようにする。

しかも著者によれば、V100の消費電力は最大でもおおむね150Wくらい。
「安いのに実用的」というのは、かなり強いです。
記事では、V100には 32GB版もあると触れています。
これを使えば、さらに大きなモデルも視野に入る。
たとえば2枚使えば64GB。
もちろん全体の構成は複雑になりますが、発想としては「中古のデータセンターGPUを積み増す」ことで、かなり安く大容量VRAMを確保できるわけです。
このへん、個人的にはかなり“自作PCの醍醐味”だと思います。
最新パーツを買って終わりではなく、制約のある機材をどう使い切るかが楽しい。
ハードの無茶ぶりに比べると、ソフト面は意外と整理されていました。
ただし、古いGPUが絡むので、そこはそれなりに面倒です。
問題は、V100がVolta世代で、NVIDIAの新しいドライバではサポートが切られていること。
さらに、RTX 4080(Ada世代)とV100を両立させるには、古いドライバ枝を使う必要がありました。
著者がやったことをざっくり言うと:

最後のやつはかなり変です。
ヘッドレス(画面なし)で使うのにX serverを有効化しないとドライバが載らない。
こういう「理屈では分からないけど、現実には必要」な設定、ほんと好きじゃないけど現場ではよくあります。
NixOSが良かったのは、こうした構成を再現可能な設定として管理できること。
一回つながると、再起動しても同じ環境を作りやすい。これはローカルLLM用途ではかなり大事です。
何しろ、CUDA・ドライバ・llama.cpp・モデルの組み合わせがぐちゃぐちゃになりやすいので。
著者が動かしているのは Qwen3.6-27B-MTP を Q5_K_M で量子化したもの。
量子化というのは、モデルを少し軽くしてVRAMに載せやすくする工夫です。
Q5_K_Mはその中でも、性能とサイズのバランスを取る形式です。
モデルサイズは約 19GB。
32GBのVRAMがあるので、モデル本体に加えてコンテキスト(文脈情報)も入る余裕があります。
設定としてはこんな感じです。

速度は 約32 tok/s。
tok/s は「1秒あたりに何トークン出せるか」で、ざっくり言えば生成速度です。
32 tok/sなら、体感としてはかなり快適です。実用的なローカルLLMだと思っていいレベルです。
著者は、ネット越しのAPIと違って待ち時間が少ない分、クラウドのモデルより体感が速いと述べています。
これはかなり納得感があります。APIは推論そのものより、通信待ちが邪魔になることが多いですからね。
ここも重要です。
この記事は「安く動いた」というだけでは終わりません。
Qwen3.6-27Bは、著者によると Claude Sonnet 4.6 にかなり近い位置にあるとのこと。
もちろん、用途によってはClaudeのほうが上だし、SWE-Benchみたいな評価では差もあります。
でも、27B級のローカルモデルが、最新の商用モデルと比較対象になるという事実はかなり衝撃です。
昔は「ローカルLLMはお遊び」「小さいモデルは便利だけど精度はそこそこ」という感じでした。
でも今は、少なくとも一部の用途では、本気で実用圏に入ってきている。
この記事は、その空気をすごくよく伝えています。
モデル名の MTP は Multi-Token Prediction のことです。
普通のLLMは、1トークンずつ順番に予測します。
でもMTPは、複数の次トークンをまとめて予測して、合っているものを採用するという仕組みです。
これにより、理論上は 1.5〜2倍くらい速くなることがあります。
とくにコードのような予測しやすい出力では効きやすいそうです。

ただし、この記事では llama.cpp のサポートがまだ新しく、
Qwen3.6のMTPに対応した特定のコミットでビルドする必要があったと書かれています。
こういうときNixOSはやっぱり強いですね。
バージョン固定がしやすいので、「昨日動いたのに今日は壊れた」みたいな泥沼を避けやすい。
ローカルLLM界隈は依存関係が壊れやすいので、これはかなりありがたいと思います。
記事の後半では、Qwen3.6-27Bが 画像入力 にも対応していることが紹介されています。
これは別ファイルの mmproj を使う仕組みです。
ざっくり言うと、画像そのものをLLMが直接見るわけではなく、
vision encoder が画像を「言葉と同じような内部表現」に変換し、それをLLMが処理します。
つまり、画像は人間のように“見ている”わけではなく、
画像を数値の列に変換して理解していると考えると分かりやすいです。
この追加で約1GBほどサイズが増えるそうですが、
テキストだけでなく画像も扱えるなら、ローカルでできることはかなり広がります。
この記事で一番印象的なのは、著者のやり方が単なる節約術ではないことです。
安い中古GPUを買って終わりではなく、
という、全部入りのDIYになっている。
そして何より面白いのは、結果としてかなり実用的なところです。
「変な構成だけど動く」ではなく、普通に使える速度と性能に到達している。
これは本当に強い。
個人的には、こういう記事を見ると「GPUは最新モデルだけが正義ではない」と改めて思います。
中古のデータセンターGPUは癖が強いですが、うまく扱えば驚くほど安く大容量VRAMを手に入れられる。
ローカルLLMを本気で遊びたい人にとって、かなり夢のある話ではないでしょうか。
