スマホで文字を打つとき、指をすべらせて単語を入力する「swipe typing」は、いまや珍しい機能ではありません。QWERTYキーボード上を、h→e→l→l→o のように指でなぞっていくあの入力方法です。慣れるとかなり速い。正直、片手での入力ではかなり気持ちいい部類です。
ただ、この便利さには長いあいだ妙な影がありました。まともな swipe typing は、プライバシーに踏み込むキーボードアプリか、あるいは閉じた非公開ライブラリの中に閉じ込められていた、というのが FUTO の見立てです。そこで同社が公開したのが FUTO Swipe。オープンなモデルとアルゴリズムの集まりで、Android のオフラインキーボードアプリ FUTO Keyboard の中で実際に使われています。
このプロジェクトでまず面白いのは、データ集めのやり方です。FUTO は 2024年8月に swipe.futo.org というドメインで、スマホから自発的に参加できる収集ページを公開しました。参加者は説明を読んで同意し、主に Wikipedia 由来の文章を、単語ごとに swipe していったそうです。
こういうデータ収集は、雑にやると品質が落ちます。でも FUTO は低品質な swipe を少し除外したうえで、最終的に 100万件以上 の swipe を集め、2025年3月に MIT ライセンスで公開しました。HuggingFace でも利用できます。

ここはかなり重要です。なぜなら、入力補助の性能って、結局は「どれだけ現実の指の動きに近いデータを持っているか」に左右されやすいからです。論文上の賢いアイデアだけでは、指が曲がって迷う現場のクセは拾いにくい。実際に人がなぞったデータを大量に集めて公開した、というのはかなり筋がいいと思います。
しかも FUTO は、このデータをモデルの学習だけでなく、さまざまな swipe typing システムの評価にも使ったと説明しています。要するに「学習用の材料」であると同時に、「腕試しの共通ベンチマーク」でもあるわけです。
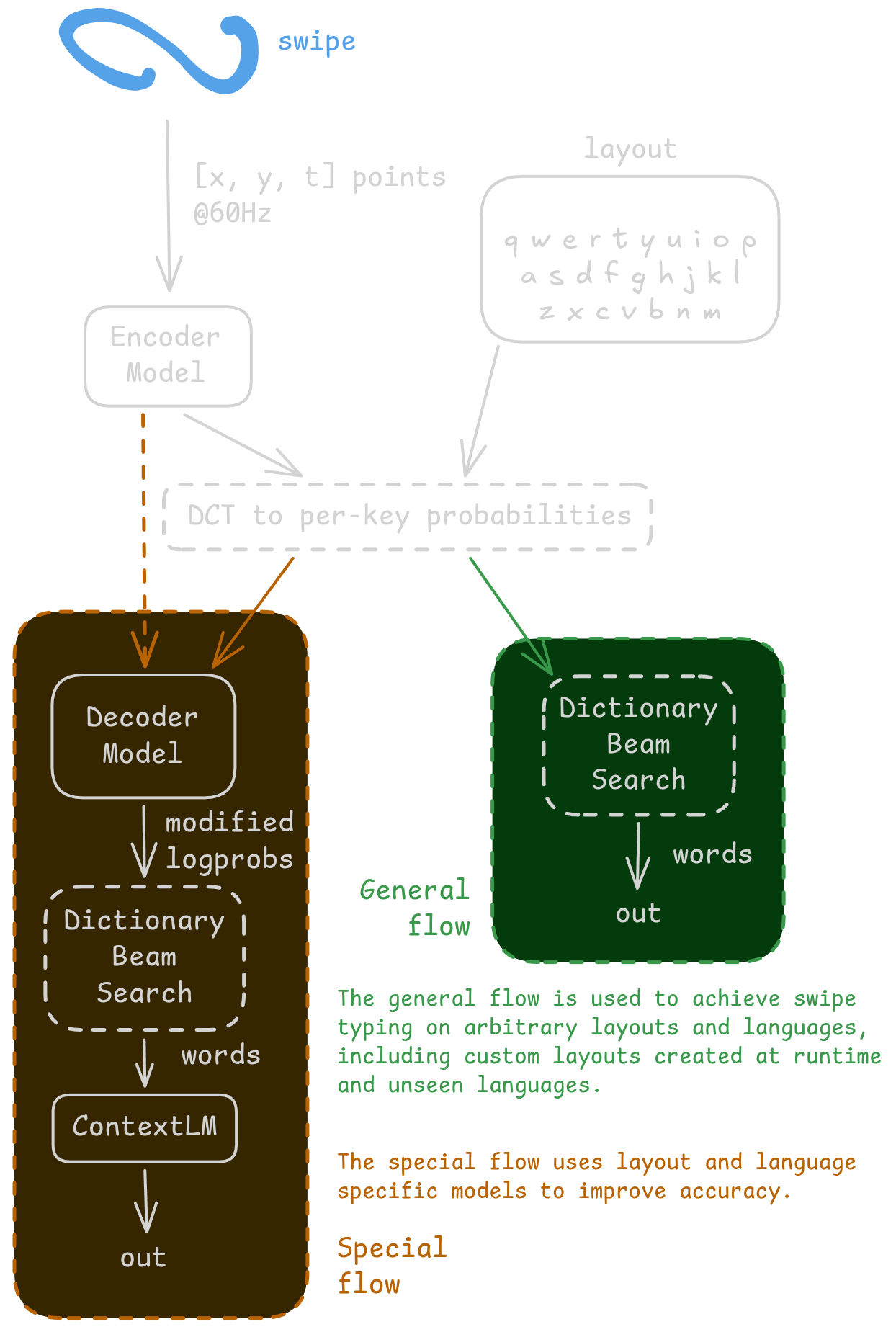
FUTO Swipe の中核は、1つの巨大モデルではありません。役割の違う 3 種類のモデルを組み合わせています。
ひとつ目は Encoder。これはレイアウト非依存、言語非依存の汎用モデルです。つまり、キーボードの配置や言語の細かい事情をあまり気にせず、まず「このなぞり方はどの単語っぽいか」をざっくり予測する役目を持っています。ただし、最先端の精度を出すタイプではない、と FUTO 自身が説明しています。
ふたつ目は ContextLM。これはとても小さな language model で、特定の1言語向けに学習されます。日本語でいうと文脈補正係です。たとえば、前の単語から見てありえない候補をはじく。単語単体ではそれっぽくても、文としてはおかしいものを落とす役です。訓練にはテキストデータだけで足りる、というのも扱いやすいところです。

三つ目が decoder。これが一番「現場寄り」です。言語とキーボード配列の両方に依存するモデルで、その配列特有のクセを覚えて、精度を引き上げます。FUTO は今のところ QWERTY English 用の decoder しか持っていない、と明言しています。
この分担は、かなり地味ですが実用的です。全部を一発で解こうとするとモデルは重くなりがちですし、逆に軽さを優先しすぎると精度が落ちる。そこで「ざっくり見る層」「文脈で絞る層」「配列の癖を覚える層」に分けるのは、かなり納得感があります。私ならこういう設計のほうが、ちゃんと端末で動かしやすくて好きです。
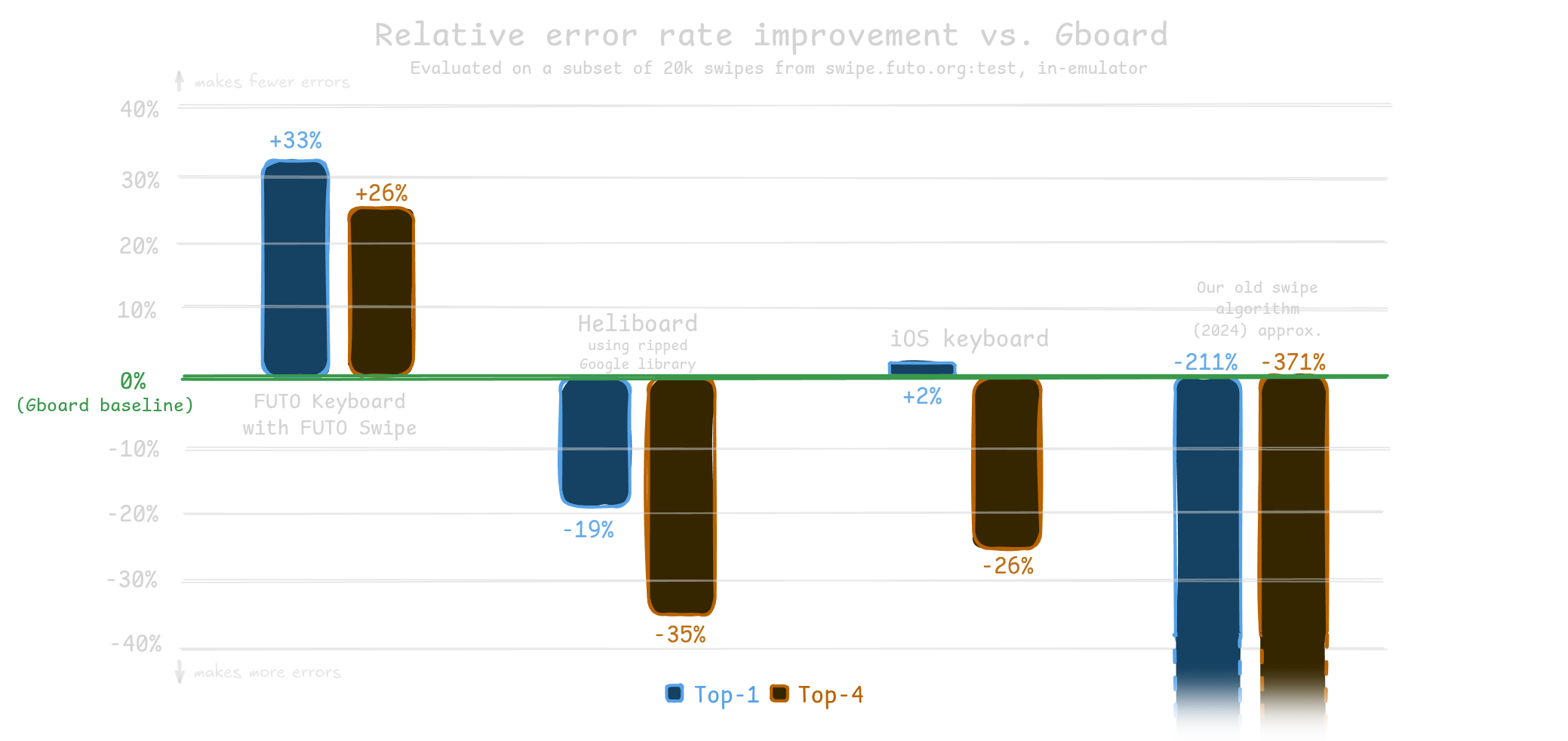
FUTO の公開値では、3つのモデルを使い、beam width を 300 にしたとき、テストセットでの top-4 fail rate は約 4% だそうです。さらに、語彙外の単語を除けば、エラー率は 1% 未満とされています。
beam search というのは、候補を一気に全部見るのではなく、有望そうな候補を広めに残しながら探索する方法です。ここでは単語候補の山をたどって、最も自然な組み合わせを探しているわけです。300 という幅はかなり広めで、精度を優先している感じがします。
ただし FUTO も書いている通り、こうした数字はベンチマーク次第で大きく変わります。現実の使い勝手がそのまま数字に一致するとは限りません。とはいえ、FUTO は「大手のキーボードと同等レベルだと考えている」と述べています。これは強気ですが、オープンに近い立場からそこまで言うのは面白い。挑戦状っぽさがあります。
個人的にいちばん惹かれたのは、このプロジェクトが「軽い」ことをちゃんと価値にしている点です。
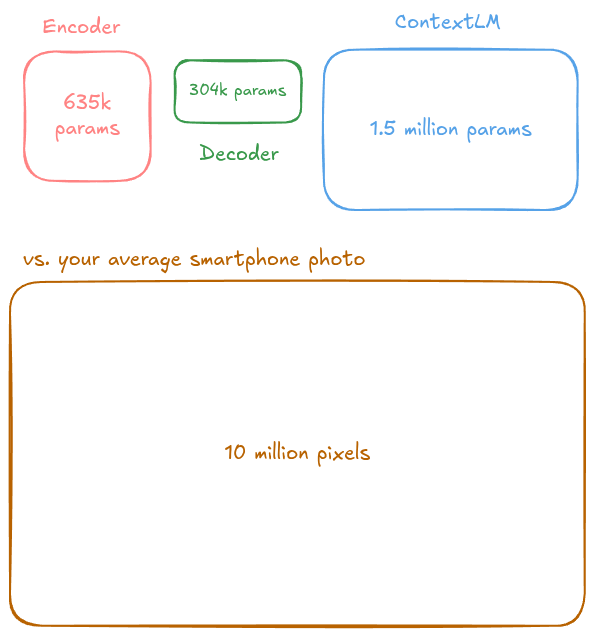
Encoder は 635,140 parameters、decoder は追加で 304,155。ContextLM は 150万 parameters ありますが、そのうち 110万は embedding だそうです。合計では 2,494,767 parameters、実際に動く active parameters は 1,364,271。数字だけ見るとピンと来ないかもしれませんが、要するに「巨大AIモデル」とはまったく別物です。ずっと小さい。
その結果、低性能な端末でもミリ秒単位で動く、と FUTO は説明しています。しかも学習に必要だった GPU も、最大で 1 台の workstation GPU で済んだとのこと。これは環境負荷の面でもかなり健全です。最近の AI はどうしても「大きければすごい」に流れがちですが、入力支援はむしろ、こういう小型・高速・省電力のほうが本来の姿ではないかと思います。
キーボードは毎日使う道具です。遅いと一瞬でストレスになるし、バッテリーを食うのも困る。そう考えると、FUTO の「軽さを武器にする」方針はかなり理にかなっています。
FUTO Swipe が単なる研究成果で終わっていないのも良いところです。モデルが出す予測は、それだけではまだ実用的ではありません。そこから辞書制約付きの beam search をかけて、候補の単語列を評価していく必要があります。
そのために公開されているのが swipe-library という C++ ライブラリです。推論、デコード、beam search をまとめて面倒見てくれるので、開発者は swipe の軌跡から単語予測までを比較的簡単に組み込めます。
ここ、地味だけどかなり大事です。研究でありがちなのは、「モデルは公開しました、あとは頑張ってください」で終わること。でも実際のアプリ開発では、モデルそのものより周辺の処理のほうが面倒だったりします。FUTO はそこをちゃんとライブラリとして押さえていて、実装の再利用をしやすくしている。オープンソースらしい誠実さを感じます。
FUTO は、VR での swipe typing や、ノートPCの trackpad 上での入力デモにも触れています。正直、これは発想としてちょっと楽しい。指でなぞるという行為は、スマホ専用のものだと思いがちですが、軌跡を入力として読むなら、別の画面や入力デバイスにも応用できるわけです。
もちろん、実際にどこまで広がるかはまだ未知数です。FUTO も「技術レポートを読んでほしい」と案内しているので、本格的に組み込みたい開発者向けの性格が強いのでしょう。ただ、少なくとも「スマホのキーボード精度を上げる」だけで終わらない余地はあります。ここは今後の広がりが少し楽しみです。
FUTO Swipe は、派手な生成AIのような華やかさはありません。でも、日常の道具をちゃんと良くしようとしている感じがあって、私はかなり好きです。しかも、プライバシーをうたうだけではなく、データ・モデル・ライブラリまで公開している。言っていることと出しているものがつながっています。
特にいいのは、オフラインで動くことを前提にしている点です。キーボードは入力した瞬間に空気のように反応してほしいし、手元の端末から文字列が外に出ないほうが安心です。そういう基本をちゃんと守ったうえで、精度も軽さも取りに行っている。こういうプロダクトは、もっと評価されてよいと思います。
一方で、現時点では decoder が QWERTY English しかないので、すぐに多言語対応の夢を見すぎるのは早いかもしれません。とはいえ、基盤が公開されているなら、コミュニティが広げていく可能性はあります。そこに期待したくなる、というのが正直な感想です。
参考: FUTO Swipe
