Appleの最新研究を眺めると、「Vision Proはもう終わった」と切り捨てるには早すぎる、という空気がはっきり見えてきます。
今回のAppleInsiderの記事では、AppleのMachine Learning Blogに公開された3本の研究を中心に、LLM(大規模言語モデル)を空間認識や手話処理にどう活かすかが紹介されています。
正直、かなり面白いです。というのも、ここでAppleがやっているのは単なる「AIチャットを賢くする」話ではなく、現実の空間を理解し、目の前の物をどう扱うかまで考えるAIを育てようとしているからです。これはVision Proのような空間コンピューティング製品と相性がよすぎる。むしろ、ここを狙わずしてAppleのAI戦略は語れないのではないか、と思います。


今回の研究で目立つのは、AppleがAIに求めているのが単なる文章生成能力ではないことです。
Appleは、空間を理解する力や物の役割を理解する力を重視しています。
たとえば、人間は部屋を見たときに「机がここにある」「リモコンはテレビを操作するもの」「洗濯機のこの状態はエラーかも」と自然に判断できますよね。
Appleは、AIにもそういう理解を持たせたいわけです。
この発想、かなりAppleらしいです。
派手に「AIで何でもできます」と言うより、実際の体験をよくするためにAIを地味に鍛える感じがする。こういう方向性は、個人的にはかなり好感があります。
最初の研究は、**“From Where Things Are to What They’re For: Benchmarking Spatial-Functional Intelligence for Multimodal LLMs”** というものです。
タイトル通り、AIが「物の位置関係」だけでなく、「その物が何に使われるか」まで理解できるかを評価します。
従来の評価方法は、主に
をチェックするものが中心でした。
でもAppleは、それだけでは足りないと言います。
たしかにその通りで、現実世界で役立つAIには、

までわかってほしいわけです。
Appleが作ったのは、SFI-Bench(Spatial-Functional Intelligence Benchmark)という新しいベンチマークです。
これは、134本の屋内動画スキャンから作られた1,555問の専門家注釈つき質問で構成されています。
![]()
ベンチマークの内容もかなり実践的で、
といった問題が含まれます。
要するに、AIに「見えているものを言い当ててみて」ではなく、**“この場面を本当に理解している?”** と突っ込んでいるわけです。ここが重要です。

Appleの評価では、Google Gemini 3.1 Proが総合トップ、OpenAI GPT-5.4-Highが2位、Gemini 3.1 Flash Liteが3位でした。
ただし、Apple自身も「まだまだ難しい」と認めています。
特に、global conditional counting という、条件付きで数を数えるような問題が大きなボトルネックになっているとのことです。

これは言い換えると、AIはまだ
が苦手、ということです。
個人的には、ここはかなり納得感があります。
人間なら一瞬でわかる「この棚の中で同じメーカーのボトルを数える」といった作業も、AIには意外と難しい。AIが“雰囲気”で答えてしまう限界が、こういうテストだと露骨に出るんですよね。

なお、Appleはインターネットにアクセスできるモデルのほうが成績がよかったとも述べています。
つまり、閉じた知識だけで考えるより、外部情報を引けるほうが現実的な理解につながる、ということです。これも実用面ではかなり大事な示唆だと思います。

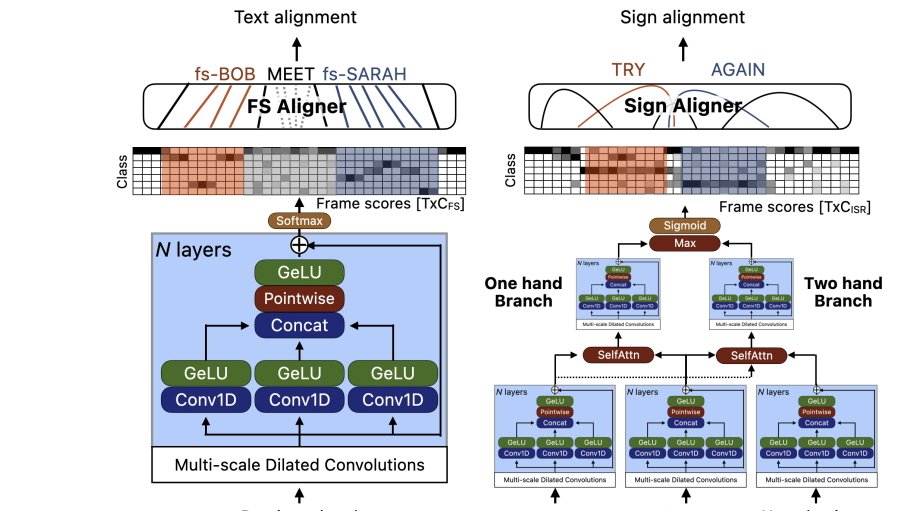
2本目の研究は、**“Bootstrapping Sign Language Annotations with Sign Language Models”** です。
こちらは、手話動画に注釈をつける作業をAIで効率化できないかを調べています。
ここでいう注釈は、手話動画に対して
を人手で記録していく作業です。

これ、地味ですがめちゃくちゃ大変です。
しかも手話は、単語をそのまま置き換えるだけではなく、動きや手の形、文脈が絡むので、ラベル付けが簡単ではありません。大量の動画を人間が見るのは、時間もコストもかかります。
Appleは、pseudo-annotation pipeline という仕組みを提案しています。
ざっくり言うと、手話動画と英語文を入力すると、ありそうな注釈候補をランキングで出してくれる仕組みです。

対象は
などです。
Appleはこれにより、数百時間分の手話データを手作業で注釈する負担を減らそうとしています。

研究では、比較的少ないGPUリソースでも学習できる方法を示し、
という結果を報告しています。

さらに、300時間超のASL STEM Wiki と 7.5時間のFLEURS-ASL に対して、手作業注釈や擬似注釈を検証したそうです。
また、Claude Sonnet 4.5を使ったテストでは、glossから英語への変換を行わせて、参照文と比べる実験もしています。
エラーは特に、指文字がない文で起きやすかったとのことです。
この記事では、これがカメラ搭載のAirPods や、Live Translationの手話対応につながる可能性があるのでは、と見ています。
これ、十分ありえそうです。Appleは翻訳機能をどんどん広げたいはずですし、手話対応は技術的にも社会的にもインパクトが大きい。

もし本当に実現したら、かなり意義のある機能になると思います。
単なるガジェットの新機能というより、コミュニケーションの壁を少し下げる方向のAIだからです。

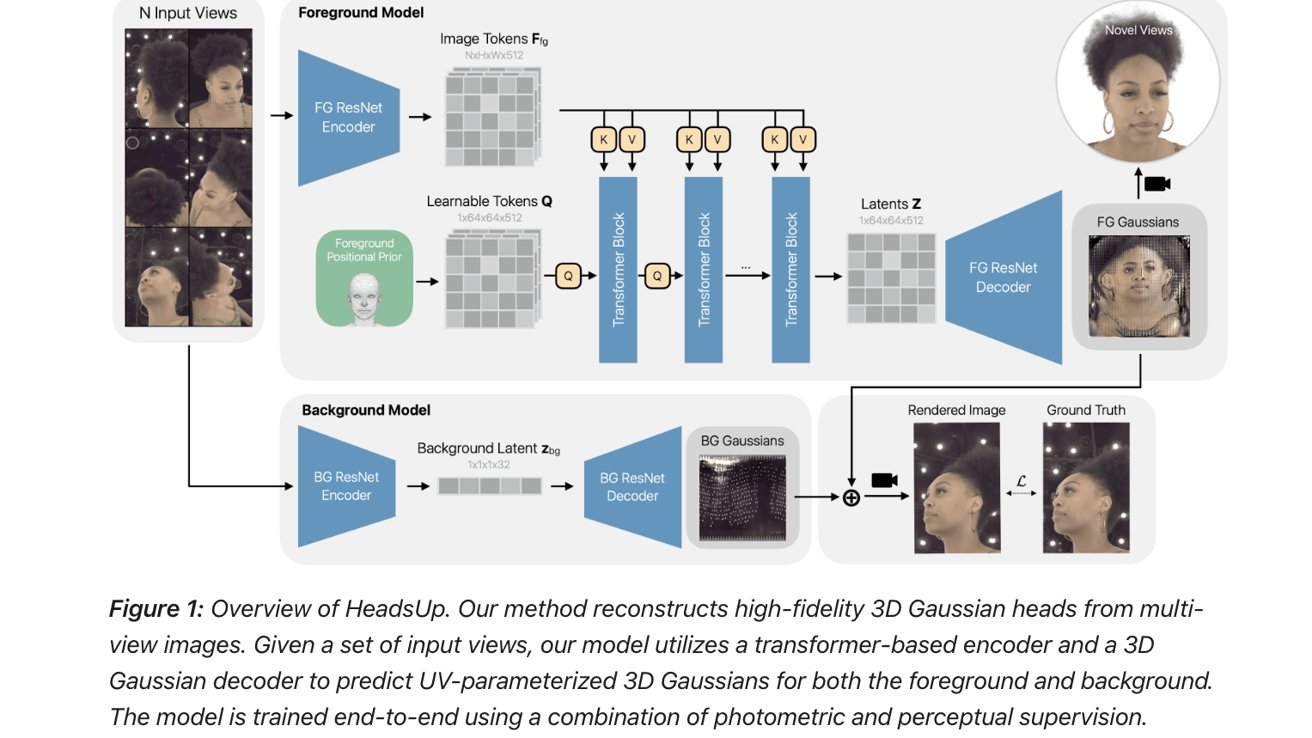
3本目は、**“Large-Scale High-Quality 3D Gaussian Head Reconstruction from Multi-View Captures”** です。
名前は長いですが、やっていることはわりと直感的です。
複数のカメラで撮った顔画像から、高品質な3D headモデルを作る研究です。
Appleは HeadsUp という方法を開発し、
多視点の撮影データから 3D Gaussian heads を再構成します。

「Gaussian blobs」と言われると難しく聞こえますが、要は3D形状を点やぼかしの集まりとして表現し、それをもとに立体モデルを作るようなイメージです。
細かい数学はさておき、重要なのは顔の立体感や表情の再現性を高める狙いです。
Appleは、10,000人超の被験者を含む内部データセットを使ったとしています。
これは既存の多視点人間頭部データセットより桁違いに大きいとのこと。

この規模感はかなりAppleらしいです。
アルゴリズムだけでなく、大規模データを持っている企業が強いというのを改めて感じます。
この記事では、これはVision ProのPersona機能と関連している可能性があると指摘しています。
Personaは、ユーザーの顔を3D的に表現する機能ですが、もっと自然な表情再現や顔のキャプチャ精度向上に、この研究が役立つかもしれません。
さらに、装着感やハードウェア設計の面でも、3D headタイプの研究は意味があるかもしれないとのことです。
これも納得です。
ヘッドセットって、性能だけでなく「顔にどう当たるか」「どんな顔形状に合うか」が地味に重要ですからね。3D head研究は、見た目よりずっと実用品質に直結する領域だと思います。

今回の記事の面白さは、AppleがAIを単体のチャット機能としてではなく、空間コンピューティング、翻訳、アクセシビリティ、顔の再現まで含めた基盤技術として扱っている点です。
つまりAppleは、
という方向に進んでいるように見えます。

もちろん、これがすぐ製品になるとは限りません。
研究は研究なので、実際のiOSやvisionOSに載るまでには時間がかかるはずです。
でも、方向性としてはかなりわかりやすい。Appleはたぶん、「AIで何をするか」より「AIでユーザー体験をどう自然にするか」を重視しているんだと思います。
そして、その延長線上にあるのが、空間を理解するSiriや、手話対応の翻訳、Vision Proの高精度なPersonaなのではないでしょうか。

Appleの今回の研究群は、派手な発表ではないものの、かなり重要です。
なぜなら、AppleがAIを現実空間と結びつける方向に本気で取り組んでいることが見えるからです。
特に印象的だったのは、

の3点です。
個人的には、AppleのAI戦略は「ChatGPTの対抗馬を作る」よりも、Apple製品全体をじわじわ賢くする方向にあるように見えます。
そのほうがAppleらしいし、たぶん長期的には強い。派手さはなくても、生活に溶け込むAIは最終的にかなり強いはずです。

参考: Apple research examines LLMs spatial understanding, annotation
