kapa.ai の記事は、RAG(Retrieval-Augmented Generation、検索で集めた情報を使って回答する仕組み)における画像の扱いを、かなり実務寄りに解説しています。
率直に言うと、これはすごく地味だけど、かなり賢い設計だと思いました。
多くの人は「画像も入れたいなら、vision model にその都度見せればいいのでは?」と考えがちです。けれど、実際に大規模運用すると、毎回画像を読ませるのは高い・遅い・重い。しかも、画像が必要な回答はそこまで多くない。
そこでkapa.aiは、発想をひっくり返します。
これで、以後の検索・生成はほぼテキスト中心で回せます。
これはRAGの基本思想とも相性がいいです。RAGはもともと「重い処理は前もって済ませて、問い合わせ時はなるべく軽く」という思想に向いていますから、画像にもそれを当てはめたわけですね。
記事では、実際の顧客質問をたくさん見たうえで、画像には大きく2種類あると整理しています。
たとえば、
こういう画像です。
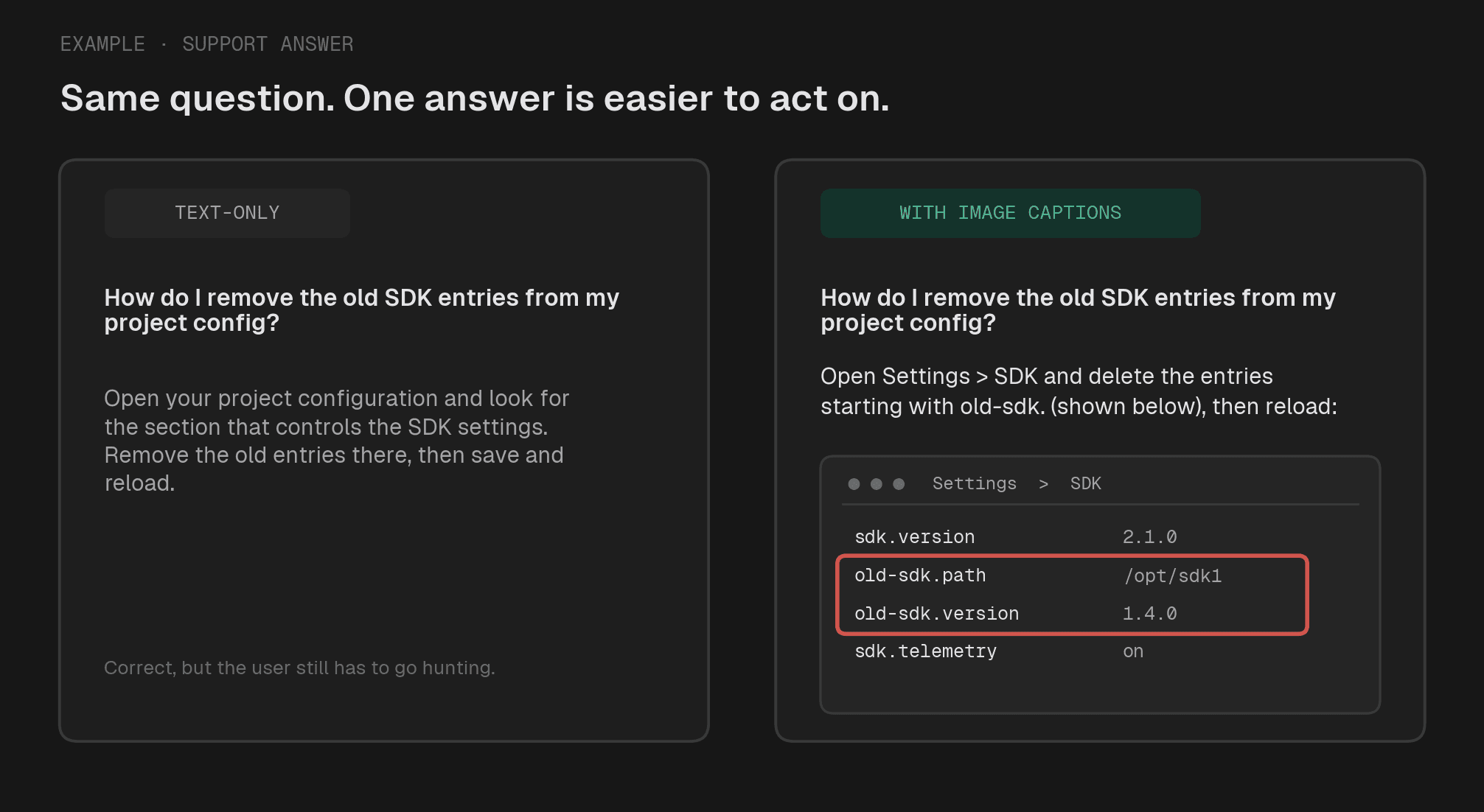
この場合、文字だけでも情報は伝わるのですが、画像があると「どこを押せばいいか」が一気にわかりやすくなります。
つまり、画像は答えの本体ではなく、行動しやすくするための補助です。
こちらはもっと重要です。たとえば、
のようなものです。
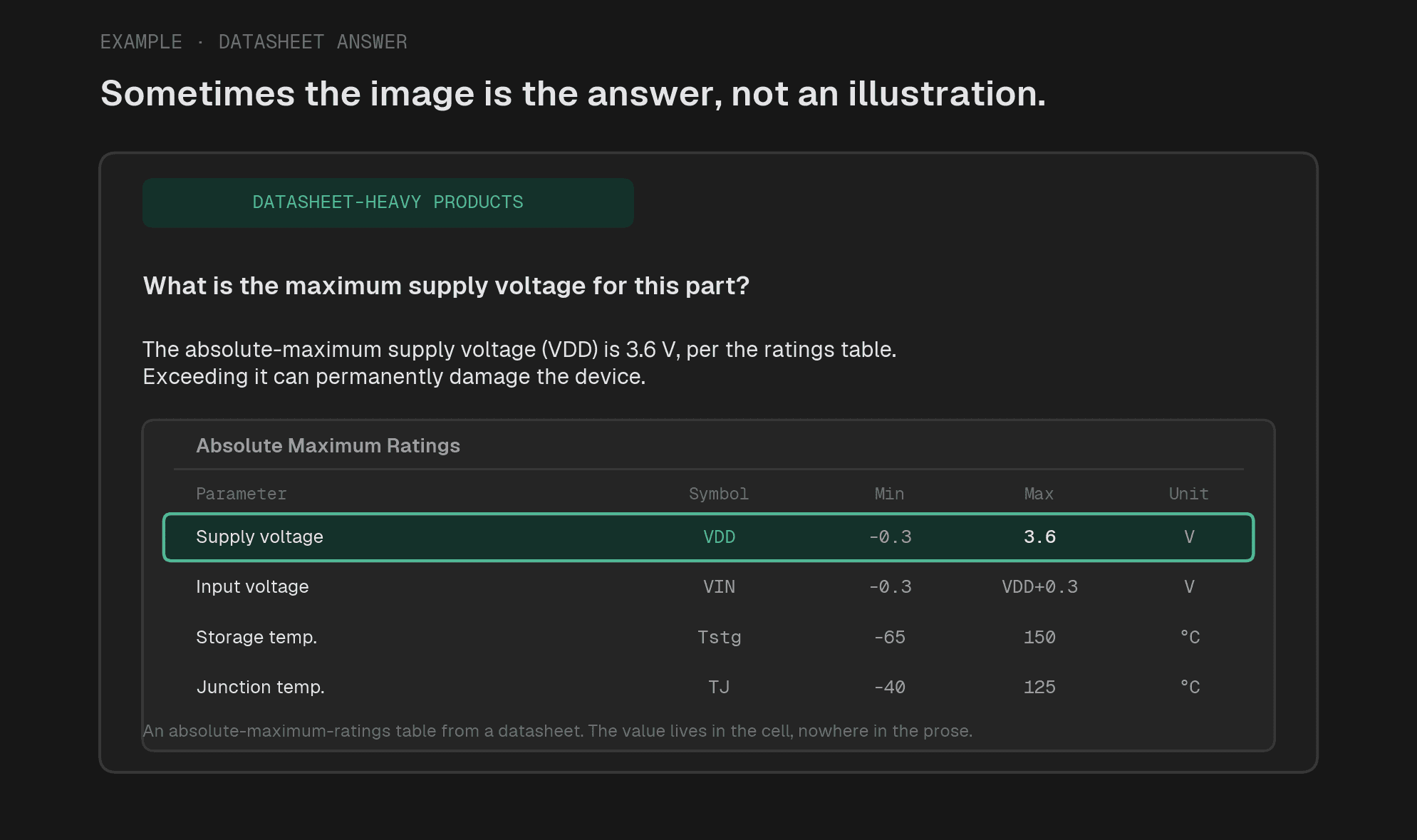
こういう画像は、画像の中にしか答えがないことがあります。
ここが面白いところで、画像は「見やすさ」だけの問題ではないんですよね。画像そのものがデータベースになっているケースがある。これは、ハードウェアや半導体、製品ドキュメントではかなり現実的です。

個人的には、この整理はとても本質的だと思いました。
「画像は飾り」ではなく、「画像は情報源」になりうる。ここを見誤ると、RAGの品質はあっさり崩れます。
最初に考えつくのは、検索で関連しそうなテキストを拾って、その周辺の画像もまとめて vision model に渡す方法です。
でもkapa.aiは、これを実運用で試した結果、かなり厳しいと判断しています。
理由は3つです。
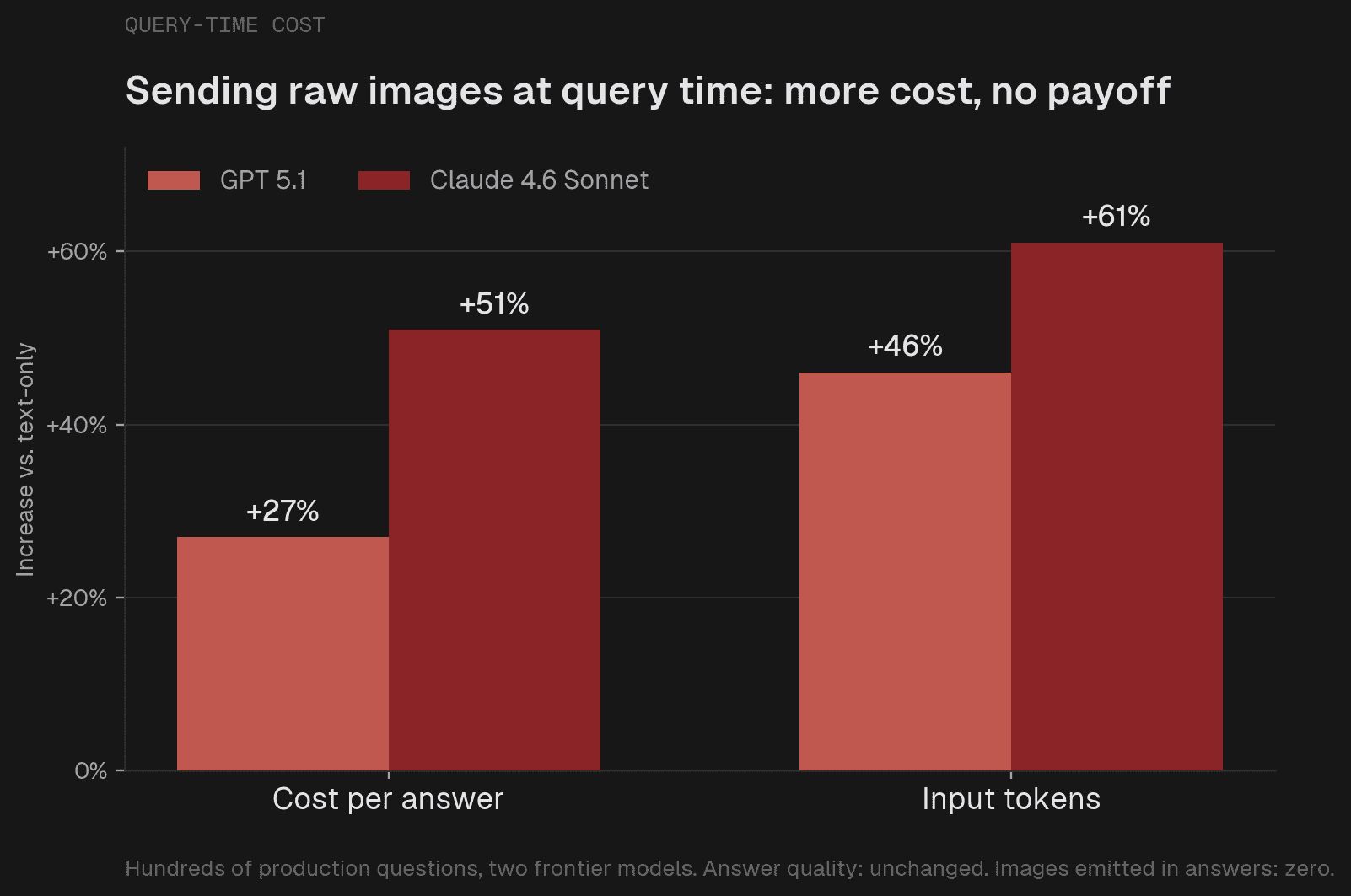
記事によると、raw image をそのまま扱うと、1リクエストあたりのコストがかなり増えます。
しかも、サービス全体で見ると「画像が必要な質問」は一部です。
それなのに、毎回画像処理の料金を払うのは無駄が大きい、というわけです。
これは現場感のある判断だと思います。
理論上は「画像も見れば精度が上がる」ですが、SaaSの運用では精度だけでは決められない。コストは正義です。
RAGでは、1つの質問に対して複数のchunk(文章のかたまり)が拾われます。
そのchunkが参照している画像を全部持ってくると、件数がすぐ膨らみます。
記事では、平均でも 20〜30枚、長い尾では 130枚超 になるとあります。
Claude は 30MB、OpenAI は 50MB の制限があるので、画像をたくさん詰め込むと簡単に限界に達します。
つまり、そもそも全部は見せられない。
見せる枚数を絞ると、今度は画像の意味が薄れる。なかなか嫌な状況です。
CLIP系の埋め込み(画像や文をベクトル化して近さで検索する仕組み)は便利ですが、技術ドキュメントの世界では弱点があります。
こういう細かい情報が重要なのに、ベクトル検索ではそこがぼやけやすい。
短い質問文「Xの設定はどうする?」と画像ベクトルをうまく合わせるのも難しい。
要するに、技術文書の画像検索は、見た目以上に相性が悪いということです。
kapa.ai の答えは、かなり割り切っています。
問い合わせ時に画像を読ませるのではなく、取り込み時に一度だけ画像を説明文へ変換する
流れはこうです。
これなら、重い画像解析は一回だけです。
以降はテキスト検索なので、RAGのパイプラインがかなり素直になります。
ここで大事なのは、caption(画像説明)が単なる「alt text」の代用品ではないことです。
記事では、説明画像なら「何が写っているか」を、答えを持つ図表なら「表の値や図のラベル」を、必要なら文字起こしに近い形で記述するとしています。
つまり、画像を“雰囲気”で要約するのではなく、情報として再表現するわけです。
この発想はかなり強いです。
一番大きい利点は、検索の土俵を揃えられることです。
RAGの検索は基本的にテキストが得意です。
なら、画像もテキストにしてしまえばいい。
すると、普通の文章と同じように関連性を判定できるようになります。
たとえば、色の対応表を考えてみてください。
画像をそのまま雑に抽出すると、表の構造が崩れて「何色が何に対応するか」が曖昧になりがちです。
でも、取り込み時にちゃんと説明文として保存しておけば、検索で拾えるし、回答もズレにくい。
記事が強調しているのは、画像が“答え”の場合こそ、テキスト化が効くという点です。
これ、地味ですが超重要です。
RAGの失敗って、だいたい「情報を持っているのに検索できない」ことで起きるので、先に構造を整えておくのは理にかなっています。
とはいえ、画像を片っ端からcaption化すればいいわけではありません。
世の中の画像は、だいぶ雑多です。
こういうものまで全部処理すると、コストのわりに得るものが少ない。
そこでkapa.aiは、まずヒューリスティクス(ざっくりしたルール)で明らかに不要なものを落としています。
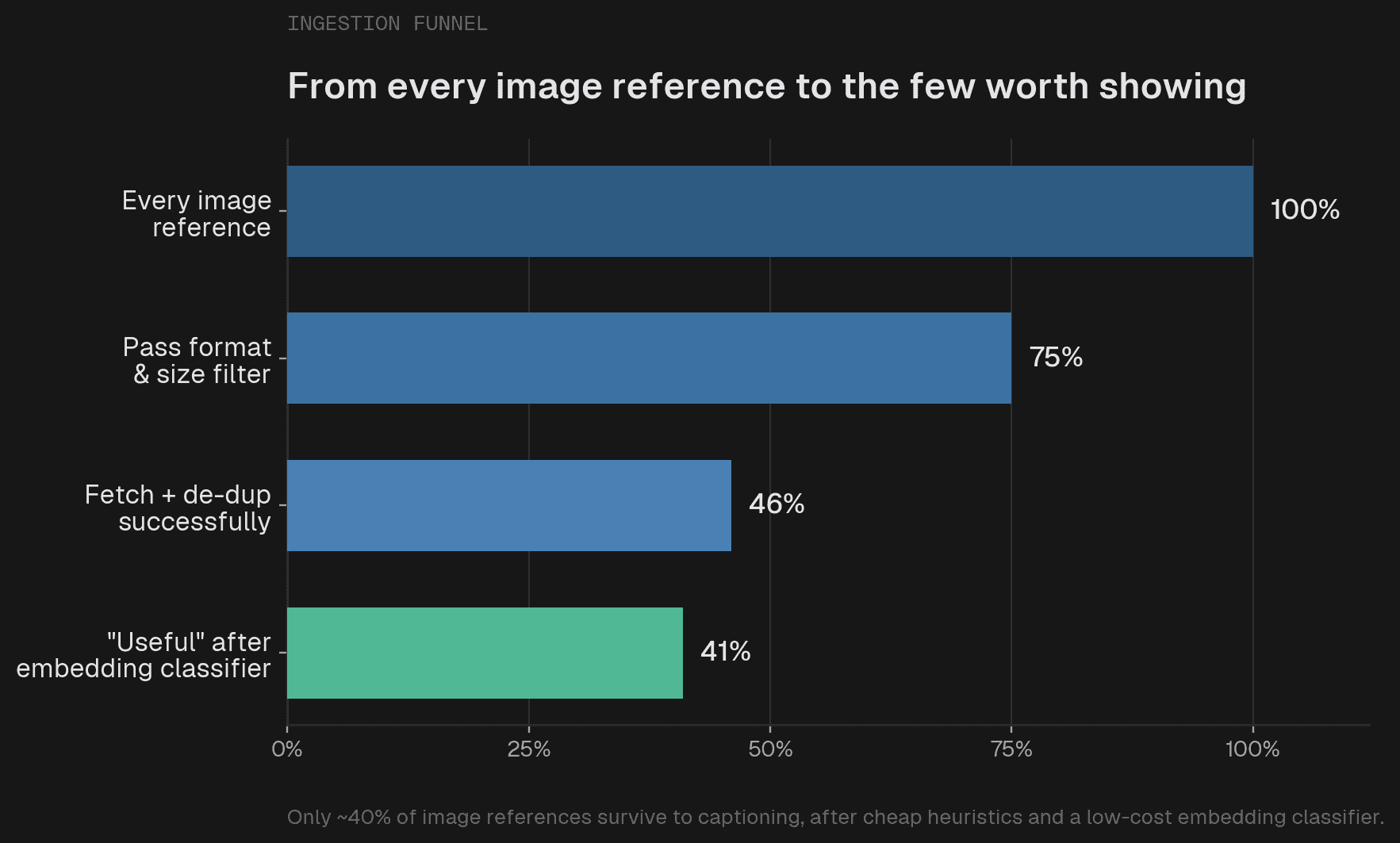
さらに残った画像に対して、multimodal embedding を使ったゼロショット分類を行います。
結果として、
としています。
ここが正直でいいところです。
「あいまいな画像はモデルでも判定しにくい」とはっきり認めている。
これは欠点というより、問題の本質は文脈不足だという話です。
たとえば、カウントダウンタイマーのスクリーンショットは、
つまり、ピクセルだけでは区別できない。
この手の画像は、前後の文章と一緒に見ないと意味が決まりません。
個人的には、ここはAIの限界というより、人間が見ても文脈がないと判断しにくい領域だと思います。
だからこそ、context-aware classification(周辺文脈を使う分類)が次の一手になる、という話には納得感があります。
captionを作るとき、何が効くのか。記事によると、重要なのは2つです。
画像単体を見せるより、前後の段落を一緒にモデルへ渡すと品質がかなり上がるそうです。
たしかに、ファイルアップロードのダイアログを見ただけでは、
「ただのWebページのフォーム」にしか見えません。
でも、前後の説明があれば、
がわかる。
captionは、この文脈込みで初めて“検索に使える情報”になるわけです。
記事では、Claude 4.6 Sonnet から GPT 5.4 nano まで比較していて、
GPT 5.4 mini くらいの小さめモデルで十分よい結果だったとしています。
しかも、かなり安い。
大きいモデルを使えば何でもよくなる、というわけではないのが面白いところです。
これは現場ではかなり大事です。
画像の説明文なんて、毎回“超天才モデル”で生成する必要はない。
そこそこ賢くて、安くて、速いモデルのほうが、全体最適では勝ちやすい。私はここ、かなり実務的で好きです。
captionをどう検索に載せるかも、実験しています。
文書の中の画像を、本文の一部として混ぜ込む方法です。
イメージとしては、画像の説明を既存のchunkに埋め込む形。
captionを独立したchunkとして保存する方法です。
本文はそのまま、画像説明だけ別の検索単位にする。
最初は inline のほうがよさそうに見えます。
だって、画像のすぐ近くにある文章と一緒に扱えるからです。
でも、結果はseparate の勝ちでした。
理由はシンプルで、inline は caption を含む chunk が毎回長くなり、画像に関係ない質問でも余計な情報を運んでしまうからです。
一方、separate なら、必要なときだけ検索で引っかかる。
結果として、
という差が出ています。
これはかなり納得感があります。
RAGって、欲張って情報を混ぜすぎると逆に弱くなるんですよね。
「情報は近くにあるほどいい」は半分正しいけれど、検索システムでは独立した単位にしたほうがヒットしやすいことが多い。ここは実装者なら頷く人が多いはずです。
記事の最終結果はかなり明快です。
3つの顧客プロジェクトで、GPT 5.1 と Claude 4.6 Sonnet を使って検証したところ、画像キャプションを入れた回答は、
さらに、画像は 94%〜99% の確率で正しく配置されたとしています。
この数字の何がすごいかというと、「画像を入れたら劇的に遅くなる」わけではなく、かなり小さい追加コストで効果が出ていることです。
しかも、回答品質はちゃんと上がっている。
派手ではないけれど、こういう改善が本当に強い。
実運用では、1問あたりの精度が少し上がるだけでも、サポートの手間や再質問率がじわじわ下がります。
私はこのタイプの改善が、いちばんプロダクト価値に効くと思っています。
この記事は、見た目には「vision model をどう使うか」の話に見えます。
でも本質は、むしろ検索設計の話です。
ポイントは、画像を無理に“その場で理解させる”ことではなく、
という流れに落とし込んだことです。
この設計は、かなりRAGらしいです。
RAGは、モデルの賢さだけで勝つものではなく、どんな情報を、どの形で、どのタイミングで渡すかで勝負が決まります。
kapa.ai はそこを、画像でもきっちりやった。そこが面白いし、重要だと思います。
個人的には、「画像をAIに見せれば何とかなる」という雑な発想より、
「画像を一度テキスト化して、検索のルールに乗せる」という発想のほうが、よほど実装として強いと感じました。
地味ですが、プロダクトはたいていこういう地味な勝ち方をします。
参考: How we index images for RAG - kapa.ai - Instant AI answers to technical questions
