インドのフードデリバリー企業 Swiggy が、検索候補表示の仕組みをかなり本格的に刷新した、という話です。
検索窓に1文字打つと候補が出てくるあの機能、見た目は地味ですが、実は裏側ではかなり忙しい処理が走っています。しかも Autocomplete は、1回の検索で終わりではなく、キーを打つたびに再検索が起きるので、とにかく速さが命です。
ここが遅いと、ユーザーは「なんか引っかかるな」と感じてすぐ離れてしまう。地味だけど、サービスの体験を左右する重要パーツです。
Swiggy はここで、従来の「人が調整したルールベースの順位づけ」から、learning to rank を使った機械学習ランキングへ移行しました。
個人的には、これはかなり筋のいい進化だと思います。検索候補って、単純な文字一致だけでは「本当に今この人が欲しいもの」を当てにくいんですよね。ユーザーの行動履歴や人気度のような“文脈”が効くので、機械学習と相性がいい分野です。
この仕組みの面白いところは、単に「MLを使いました」では終わっていない点です。
Swiggy は、Autocomplete を次の2段階に分けています。
これは検索システムでは王道に近い設計です。
最初から完璧な答えを探すのではなく、まず「それっぽい候補」を素早く拾い、その後で精密に順位をつける。
たとえるなら、最初に売り場をざっと回って商品を集め、最後にレジ前で「どれを優先的に出すか」を決める感じです。
Swiggy の候補生成では、OpenSearch を使った lexical retrieval と、embedding-based similarity search を組み合わせています。
つまり、「文字が合うもの」だけでなく「意味が近いもの」も拾うわけです。
これにより、ユーザーが少し曖昧な入力をしても候補を出しやすくなります。これは実際かなり便利で、検索体験の“抜け”を減らせます。
ただし、候補生成の段階はあくまで広く拾うことが目的なので、ここで細かく考えすぎないのがコツです。
速く、たくさん拾う。細かい判断は次のランキングに任せる。設計の切り分けがきれいです。
候補が集まったら、次は ML モデルが順位を付けます。ここで使うのが、ユーザーの行動に関するリアルタイム信号です。
記事で挙げられているのは、たとえば次のようなものです。
/filters:no_upscale()/news/2026/05/swiggy-autocomplete-rt-ranking/en/resources/1Screenshot 2026-05-16 at 4.53.26 PM-1778975637105.png)
要するに、「この人は最近何に反応したか」「今どんな検索をしているか」「みんなは何を選んでいるか」を見て、候補の順番を決めるわけです。
静的なルールより、かなり人間の感覚に近いです。「この人にはこれが上に来た方が自然だよね」という判断を、モデルに学ばせるイメージですね。
このシステムでは Feature Store も使われています。
Feature Store は、学習に使う特徴量と、実運用で使う特徴量をそろえて管理する仕組みです。
なぜ大事かというと、学習時と本番時でデータの持ち方がズレると、モデルがうまく動かないからです。
「学習では見えていた情報が、本番では使えない」みたいなことが起きると、せっかく作った ML が台無しになります。
Swiggy は、事前に計算した特徴量と、ストリーミングで来る最新の特徴量の両方を扱えるようにしていて、しかも重いリアルタイム計算を避けています。
これは実務っぽくて良いです。理想論より、ちゃんと遅延を守る工夫が入っているのが好印象です。
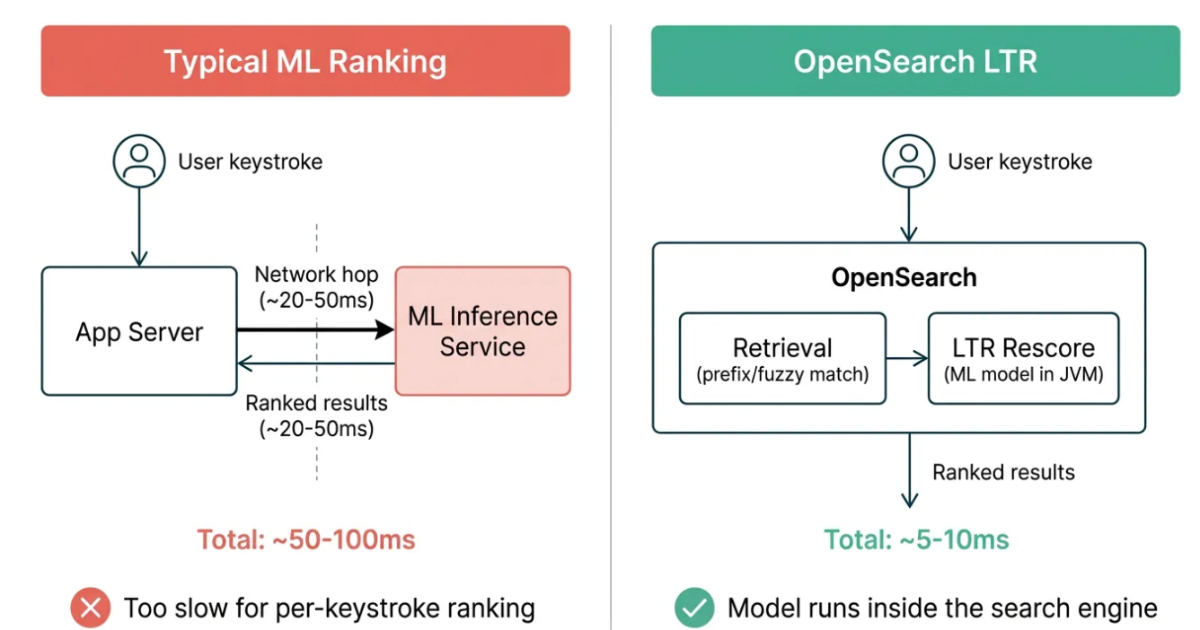
記事で特に重要なのは、ランキングモデルを OpenSearch の中で直接動かしていることです。
これによって、追加のサービスを挟まなくて済みます。
サービスを1つ増やすと、その分だけネットワークの往復が増えますし、障害点も増えます。Autocomplete はミリ秒単位の世界なので、余計なホップはかなり痛い。
つまり Swiggy は、
「MLを使う」ことより「MLを低遅延で使い切る」こと
に本気で取り組んでいるわけです。
これは地味ですが、かなり重要です。
モデルが賢くても、遅ければ使い物になりません。検索や推薦の現場では、賢さと速さの両立がいつも難所です。
以前は、手で調整した heuristic ranking、つまり「この条件なら上に出す」といったルールで順位を決めていたようです。
でもルールベースは、増やせば増やすほど複雑になります。しかも、ユーザー行動が変わるたびに人手で直すのはしんどい。
そこを ML に置き換えると、ユーザーのクリック率や購入、注文といった実データから、ランキングを自動で改善できます。
この発想はとても現代的です。個人的には、検索やレコメンドのような「答えが1つじゃない領域」は、ルールだけで追いかけるより ML の方がずっと自然だと思います。
もちろん、ML にすれば自動で全部うまくいくわけではありません。
学習データの品質や、遅延、再学習の頻度、説明しやすさなど、課題は山ほどあります。
でも、Swiggy はそこをちゃんと設計で受け止めているのがえらいところです。
このシステムのもう一つの肝は、継続的なフィードバックループです。
ユーザーの
といった信号を集めて、オフラインの学習パイプラインに流し、モデルを再生成して、model registry に保存し、オンラインへデプロイする。
つまり、使われ方を見ながらモデルを育てる流れです。
これはかなり実用的です。
検索候補の世界は流行り廃りが早いので、古いモデルのままだとすぐズレます。
新しい検索語やトレンドに、自動で追従できるのは大きな強みでしょう。
この事例の本質は、「ML を入れた」ではなく、「低遅延のまま ML を回す設計にした」ことだと思います。
Autocomplete は、ユーザーに見えないところで毎回ものすごく厳しい条件を要求されます。
その中で、
という構成は、かなりバランスがいいです。
派手さはないけれど、実運用で強い。
こういう設計は、技術記事としても実務のヒントとしてもかなりおいしいですね。
Swiggy の事例は、検索候補のような“目立たないけど超重要な機能”を、機械学習でしっかり改善した好例です。
しかも、ただ精度を上げただけでなく、低遅延・継続更新・学習と本番の整合性までちゃんと考えているのがポイントです。
個人的には、こういう「AIで派手に見せる」話より、既存機能を現実的な制約の中で少しずつ賢くする話のほうがずっと面白いです。
現場で本当に価値が出るのは、たぶんこういうところなんだと思います。
参考: Swiggy Improves Search Autocomplete Using Real Time Machine Learning Ranking
