AMÁLIAは、ポルトガル語の中でもEuropean Portuguese(ポルトガル本国で使われるポルトガル語)に特化した大規模言語モデルです。
ポルトガル政府が2024年12月に550万ユーロを投じて進めたプロジェクトで、複数の大学や研究機関が協力しています。
ここで大事なのは、単に「ポルトガル語対応のAI」ではなく、European Portugueseを“ちゃんと主役”として扱うことを目指している点です。
英語の世界ではLLM開発が圧倒的に進んでいますが、小さい言語圏では「そもそも学習データが少ない」「評価する基準も少ない」という壁がある。ここを国として押し上げよう、という意図が見えます。これはかなり野心的ですし、正直、かなり面白い取り組みだと思います。
著者が驚いていたのが、AMÁLIAがfrom scratchで学習されたわけではないことです。
ベースはEuroLLMで、そこから継続的に pre-training を行っている、という理解のようです。
ここでいう pre-training は、LLMが大量の文章を読んで「言葉のつながり方」を覚える段階のこと。
ざっくり言えば、**“基礎体力づくり”**です。
さらに、context length や RoPE scaling などの調整も入っています。
これは難しく聞こえますが、要するに一度にどれくらい長い文章を扱えるかや、長文をうまく理解するための内部設定を調整した、という話です。
AMÁLIAの特徴は、どの学習段階でもEuropean Portugueseの比率を増やそうとしたことです。
SFTは、モデルに「こう答えてほしい」というお手本を与えて調整する工程です。
preference training は、さらに人間の好みや望ましい出力に寄せていく段階、と考えるとわかりやすいです。

ここで著者が強調しているのは、**“ポルトガル語を増やす”という発想は一貫している**一方で、実際にどれくらい増えたのかは見えにくい、という点です。
このあたり、研究としては頑張っているのに、外から見ると「で、どこまでポルトガル語なの?」となりがちで、もどかしいところです。
評価のために、AMÁLIAチームはEuropean Portuguese向けの新しいベンチマークを4つ作成しています。
その中でも特に目立つのが ALBA です。
ベンチマークは、モデルのテスト問題集みたいなものです。
英語モデルなら既存の評価が山ほどありますが、European Portugueseにぴったりのものは少ない。だから新しく作る必要があるわけです。
これは非常に重要です。
なぜなら、評価できないものは改善しにくいからです。
AI開発は「学習データを増やすこと」ばかり注目されがちですが、個人的には評価設計こそ開発の半分以上だと思っています。ここが弱いと、モデルの実力が本当に伸びたのか、ただ別の試験に強くなっただけなのかが曖昧になります。
著者がかなり率直に指摘しているのがここです。
AMÁLIAは「fully open source LLM」とうたっているものの、著者が確認した時点では、model weights、data、training logs、新しいbenchmarksが十分に公開されていなかったとのことです。
公開されていたのは、Arquivo.ptの処理スクリプトなど一部のGitHubリポジトリ。
でも、肝心の学習済み重み(weights)や学習データ本体が見えないのは、やはりかなり残念です。
ここは著者の言い方がとても現代的で、共感できます。
今は「open weights」と言いながら、実際には何がどこまで開いているのかよくわからないLLMが増えています。
だからこそ、本当にオープンを名乗るなら、weights、data、code、logs、evalsまで含めて公開してほしい、という主張には説得力があります。私もこれはその通りだと思います。
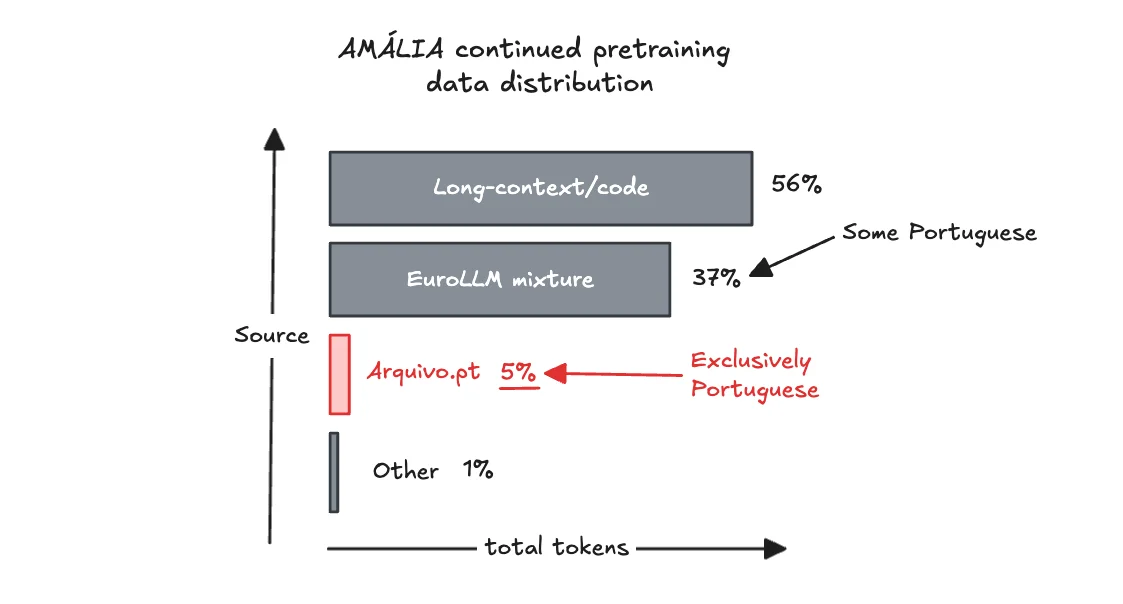
著者が最も気にしているポイントの一つが、学習データにおけるEuropean Portugueseの割合です。
報告書によれば、extended pre-training は合計 107B tokens。
そのうち、European Portugueseとして明確に確認できるのは Arquivo.pt由来の5.8B tokens。
つまり、**約5.5%**しかありません。

もちろん、ベースの EuroLLM 側にもポルトガル語は含まれているはずです。
でも、それがどれくらいなのか、そして本当にEuropean Portugueseなのかは、外からは見えにくい。ここが大きなモヤモヤです。
SFT側では比率が17〜18%程度まで上がるそうですが、それでも十分かどうかは別問題。
著者は、「もっとポルトガル語データを増やせば、さらに良くなる余地があるのでは?」と疑っています。
これはかなり自然な疑問だと思います。言語モデルって、結局はその言語をどれだけ“浴びた”かが効いてくるので。
AMÁLIAは、Qwen 3-8Bのような強力なモデルに対して、ポルトガル語ベンチマークでかなり良い結果を出しているとのことです。
これは普通に大きな成果です。ローカル言語向けモデルが、グローバル強豪に勝つのは痛快です。
ただ、著者はそこで満足していません。
なぜなら、ベンチマークが測っているのはあくまで一部でしかないからです。
たとえば著者は、
みたいな、Portugalそのものの知識を問うべきではないか、と提案しています。
これはすごく面白い視点です。
単に文法が正しい、一般知識がある、ブラジルポルトガル語に引きずられない、というだけではなく、**“Portugalを知っているモデル”**になっているか。
たしかに、European Portuguese LLMの価値はそこにあるはずです。
個人的にも、これはかなり重要な論点だと思います。
小さな言語圏のLLMは、英語モデルの小型版を作るのではなく、その国や地域に固有の知識・文化・表現を持つことに意味があるはずだからです。
最後に著者は、かなり誠実なトーンで締めています。
このバランス感覚がいいんですよね。
ただ褒めるだけでも、ただけなすだけでもない。
「すごい。でも、もっとできる」というスタンスです。
私も同じ印象です。
AMÁLIAは、European PortugueseのLLM開発が「できるかどうか」から「どう作るべきか」に進んだことを示す、象徴的なプロジェクトだと思います。
一方で、本当に価値ある国家プロジェクトにするには、公開性の徹底と評価軸の再設計が次の勝負どころではないでしょうか。
AMÁLIAは、European Portugueseを本気で扱うために作られた、大きな意義のあるLLMです。
ただし現時点では、open sourceとしての公開度や、ポルトガルらしさを測る評価にはまだ課題がある、というのがこの記事の核心です。
言い換えると、
「良いモデルを作った」だけでは終わらない。
“何をもって成功とするか”まで含めて、これからが本番
という話です。
正直、こういう「小さな言語のための大きな挑戦」は、見ているだけでワクワクします。
うまくいけば、英語一強のLLM世界に対して、かなり面白い対抗軸になるはずです。
