DeepSeekが、DeepSeek-V4 Preview を正式公開しました。しかもopen-sourced(オープンソース化)です。
ひとことで言うと、「長い文脈を安く、速く、かなり賢く扱えるAIモデル」を前面に押し出してきた、かなりインパクトのある発表です。
個人的には、今回の発表でいちばん目を引くのは 1M context length でしょう。
1M、つまり100万トークン級の長さを一度に扱えるという話で、これは「AIに長い資料を丸ごと読ませる」世界を、より現実的なものにしていく動きだと思います。
今回の発表は、単なる「新モデルが出ました」ではありません。
ポイントは、性能・長文処理・コスト効率・エージェント用途の4つをまとめて押し上げようとしているところです。

まず最大の目玉は、1M context。
これはざっくり言うと、AIが会話や資料の“前提”として覚えておける情報量がとても大きいということです。
たとえば、こんな使い方が現実的になります。
もちろん「長ければ何でも良い」という単純な話ではありません。
でも、長文の中から必要な情報を拾う力は、AI活用の実用性をかなり左右します。ここは本当に重要だと思います。
DeepSeek-V4には、用途の違う2モデルがあります。

ここでいう params(パラメータ) は、AIの“知識や判断の重み”みたいなものです。
ただし、単純に数字が大きいほど万能というわけではありません。実際には、どの部分を使って推論するかも大事です。
こちらは、ざっくり言えば「速くて安い実務向け」という立ち位置でしょう。
個人的には、こういう“ProとFlashの住み分け”はかなり賢いと思います。最強モデル1本に全振りするより、現場ではずっと使いやすいからです。
DeepSeekは今回、V4-ProとV4-Flashの特徴をかなりはっきり書いています。
ここでの Agentic は、ただ質問に答えるだけでなく、
ツールを使いながら段階的に作業を進めるAI という意味合いです。
たとえば、コードを書いて、結果を確認して、修正して……という流れを自律的に回すイメージですね。
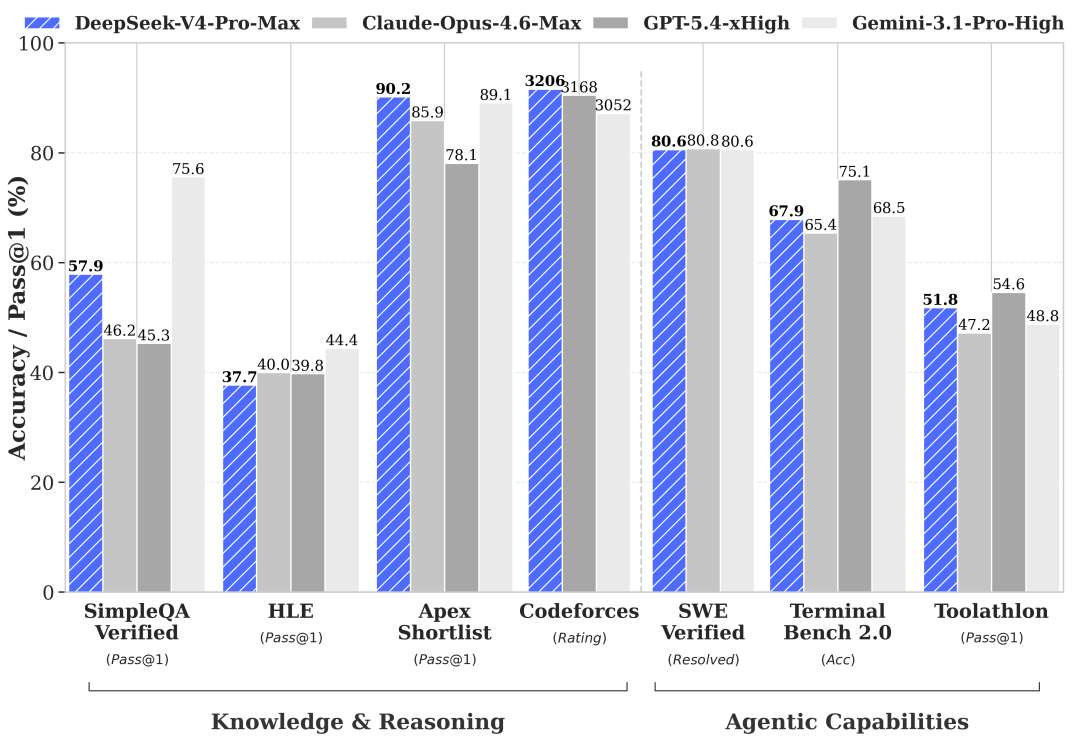
これが強いと、AIは「おしゃべり相手」から実務の共同作業者に近づきます。
この方向性、いまのAI業界ではかなり大きな潮流です。
これ、地味にものすごく大事です。
多くの現場では、毎回ガチの最高性能が必要なわけではありません。
むしろ「普段使いは軽量版、ここぞという時だけPro」のほうが、費用対効果は高いはずです。
DeepSeekは、V4の構造的な工夫として以下を挙げています。
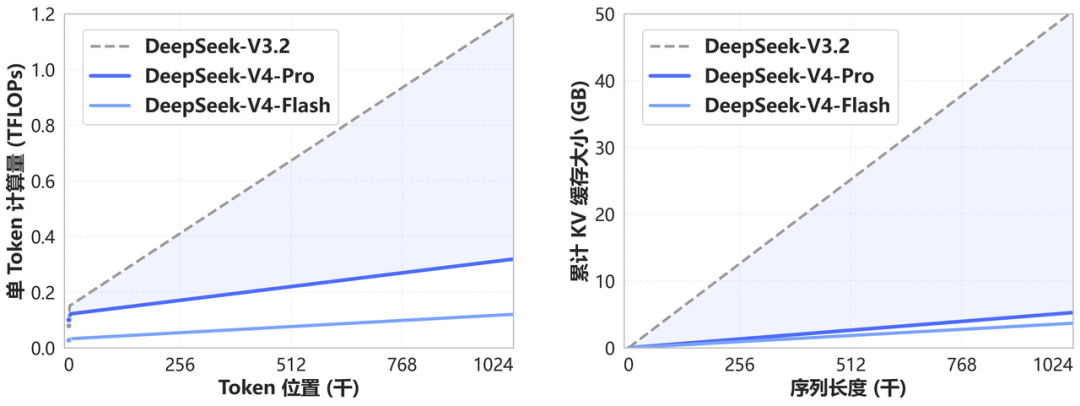
Attention は、AIが文章中のどこに注目するかを決める仕組みです。
そのうち Sparse Attention は、全部を均等に見るのではなく、重要な部分に絞って見るやり方です。
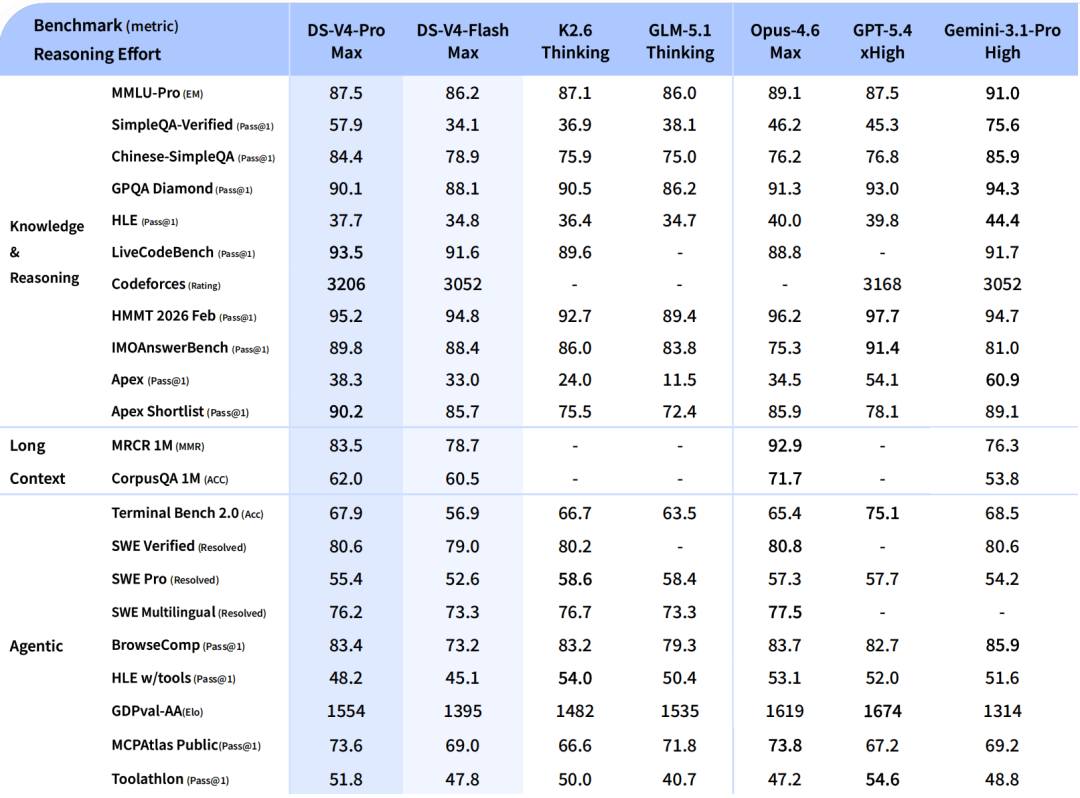
つまり、長い文章を全部ベタ読みするのではなく、
必要なところをうまく圧縮して効率よく処理する感じです。
これが長文対応の鍵になります。
なぜなら、コンテキストが長くなるほど、普通は計算量とメモリ消費が重くなるからです。
DeepSeekはそこをかなり意識していて、「長いのに重すぎない」を目指しているのが見えます。
正直、ここはかなり面白い。
1M context を「ただ売り文句として掲げる」のではなく、効率面の工夫込みで出してきたのが強いです。
DeepSeek-V4は、Claude Code、OpenClaw、OpenCode などのAIエージェントと統合しやすいこともアピールしています。
さらに、DeepSeek社内のagentic coding でもすでに使われているとのことです。
これはつまり、DeepSeekがこのモデルを
「チャットAI」よりも「作業を進めるAI」 として見ている、ということだと思います。
最近のAIは、ただ文章を作るだけでは差別化しづらくなっています。
その中で、実際の開発や業務にどう組み込めるか はとても重要です。
DeepSeekはそこにかなり本気で寄せてきている印象です。
今回の発表は、研究紹介だけでは終わっていません。
API is Available Today! とある通り、APIはすでに更新済みで利用可能です。
この「既存の接続先はそのままで、モデル名を変えれば使える」というのは、開発者にとってかなりありがたいです。
移行コストが低いので、試しやすいからです。

ここはかなり重要です。
DeepSeekは、deepseek-chat と deepseek-reasoner を
2026年7月24日 15:59 UTC に完全終了し、アクセス不可にすると告知しています。
しかも、現在はそれらが deepseek-v4-flash の non-thinking / thinking にルーティングされているとのこと。
つまり、今見えている挙動が、将来の新モデル側に寄せられている可能性があります。
開発者や運用担当の人は、ここを見落とすと後で困りそうです。
モデル切り替えの予定は、早めに確認しておいたほうがよさそうです。
DeepSeekは、最近注目が集まっていることにも触れつつ、
「情報は公式アカウントだけを信頼してほしい」 としています。
これは、AI業界ではかなり大事な話です。
モデル発表まわりは、SNSや第三者の投稿で話が盛られたり、誤解されたりしやすいので、
公式発表を一次情報として見るのが安全です。
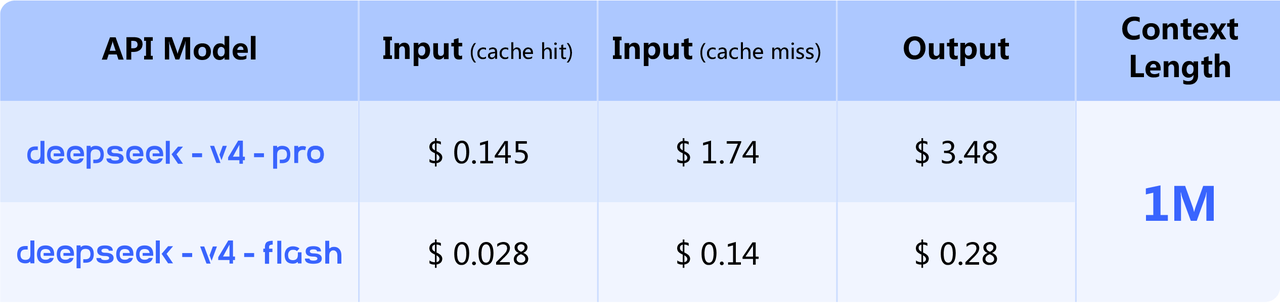
個人的には、今回のDeepSeek V4 Previewは、
「とにかく性能が高いです」だけではなく、**“現場でどう使うか”までかなり具体的**なのが好印象です。
特に良いと思ったのはこの3点です。
1M context を前面に出したこと
→ 長文・資料・コード全体を扱う用途にかなり刺さる
ProとFlashの住み分け
→ 実運用をちゃんと考えている感じがある
APIとエージェント用途の整備
→ 「デモで終わらない」方向に進んでいる
もちろん、実際の性能は使ってみないとわからない部分もあります。
ベンチマーク上の強さと、現場での使いやすさは一致しないこともあるからです。
それでも、今回の発表は**“長文処理時代の次の一歩”**としてはかなり注目度が高いと思います。

DeepSeek-V4 Previewは、
高性能・長文対応・低コスト・エージェント用途 をまとめて押し上げる、かなり野心的なモデルです。
特に、1M context length が標準という点は大きく、
PDFやコードベース、長い業務履歴を扱う場面での存在感は一気に増しそうです。
一方で、既存の deepseek-chat / deepseek-reasoner の終了予定も出ているので、
既にDeepSeekを使っている人は、移行計画を早めに考えておくのがよさそうです。
長文AIの競争は、もう「読めるかどうか」ではなく、
「どれだけ安く、速く、実用的に読めるか」 のフェーズに入ってきた——
DeepSeekの今回の発表は、そんな空気を強く感じさせます。
