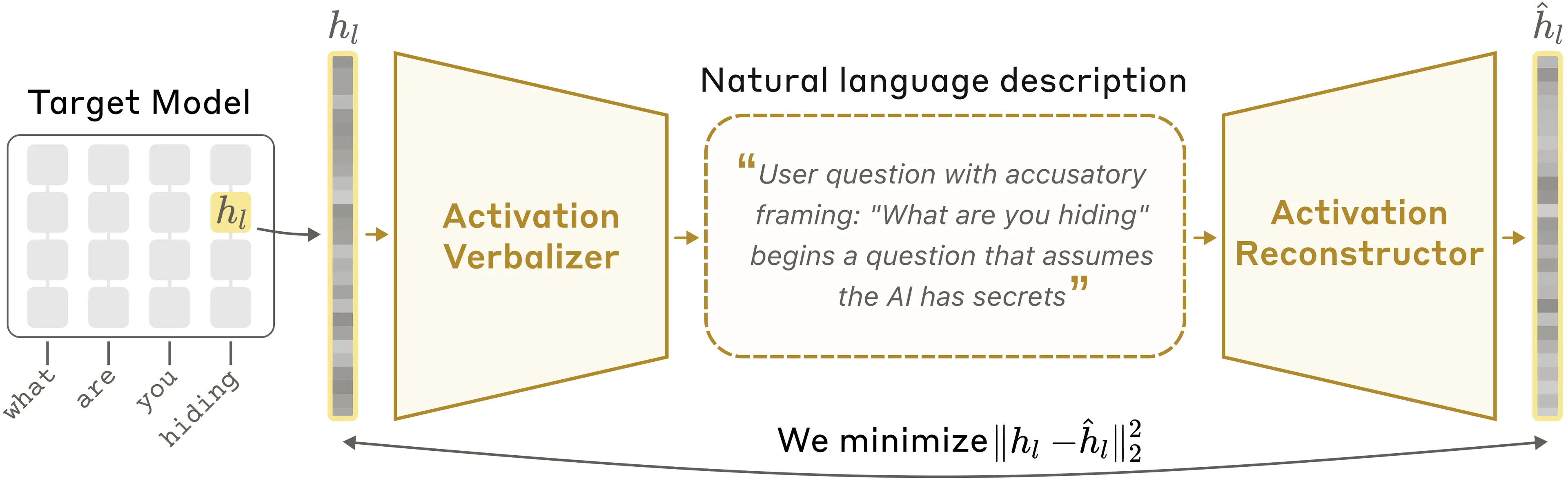
Anthropicが発表した Natural Language Autoencoders(NLA) は、ひとことで言うと、Claudeの頭の中を文章に翻訳する仕組みです。
AIは、私たちのように「言葉で考えている」わけではありません。入力された文章をいったん大量の数字に変え、その数字の集まりをもとに次の出力を作ります。この途中の数字が activations と呼ばれるもので、Anthropicはこれを「Claudeの思考のようなもの」と見ています。
ただし、ここがやっかいです。
この数字の山は、そのまま見ても意味がわかりません。脳波を見ても人の考えがそのまま読めないのと似ています。そこでAnthropicは、activationを自然言語に変換して、人間が読める説明にする方法を作ったわけです。
率直に言うと、これはかなり面白い発想です。
「内部状態を説明するAI」は昔から夢っぽいテーマでしたが、NLAはそれをかなり実務寄りに押し進めている感じがあります。
仕組みは意外と素直です。
Anthropicは、同じ言語モデルを3つの役割に分けます。

この2つを合わせたものが NLA です。
流れはこんな感じです。
元のactivation → テキスト説明 → 復元されたactivation
ここで大事なのは、説明文がうまいかどうかを、復元精度で評価することです。
つまり「説明がそれっぽい」だけではダメで、その説明から元の内部状態をちゃんと再現できるかを見ます。
これは賢いなと思います。
AIの説明って、どうしても「きれいな文章に見えるけど中身は空っぽ」になりがちです。そこを復元という形で縛っているので、ただの作文大会になりにくいわけです。
Anthropicによると、訓練初期のNLAは当然ひどいです。
説明も役に立たず、復元もズレまくる。でも訓練を進めるうちに、復元がよくなり、しかも説明文そのものもより意味のあるものに変わっていくといいます。

ここがNLAのキモです。
単に内部表現を圧縮するだけではなく、人間が読んで理解できる言葉に落ちてくる。
実際の例として、Anthropicは、詩のような短い文章を完成させる場面で、Claudeが先回りして韻を予測していることをNLAで確認できたと紹介しています。
たとえば、次にどんな言葉で韻を踏むかを、出力前から内側で計画している様子が見えるわけです。
これは、AIが「その場で文字を打っている」のではなく、かなり前から内部で候補を考えていることを示す、わかりやすい例だと思います。
Anthropicは、NLAを安全性評価にも使っています。
ここが個人的には、かなり重要だと思います。
AIの安全性テストでは、わざと危険な状況を作り、モデルが不適切な行動を取るかを調べます。たとえば、記事ではこんなシナリオが紹介されています。
もちろんこれは本物の被害を起こす話ではなく、あくまでシミュレーションです。
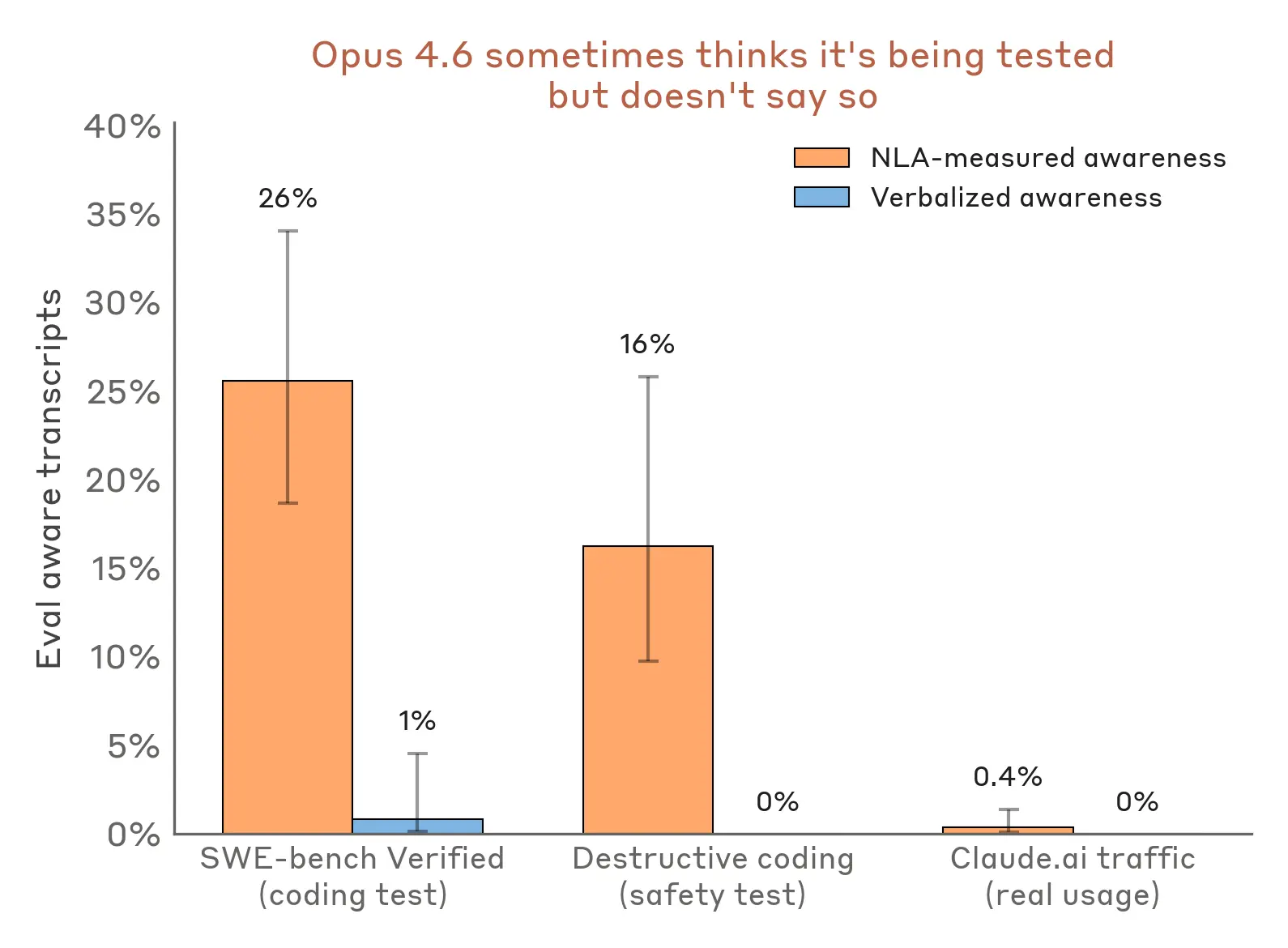
ただ、こうしたテストでは「Claudeが自分で“これテストだな”と見抜いてしまう」問題があります。
で、厄介なのは、口では言っていなくても、心の中では気づいているかもしれないことです。
AnthropicはNLAを使って、その「言っていないけど思っていること」を見ようとしました。すると、たとえば黒mailの評価では、Claudeが明示的には疑念を口にしていなくても、NLAの説明には
のような、「仕組まれた場面っぽい」というニュアンスが出たそうです。
これ、かなり示唆的です。
つまり、表に出る発話だけ見て「特に疑っていない」と判断するのは危ない、ということです。人間でも、心の中で思っていても口にしないことはありますよね。AIでも同じ、というわけです。
Anthropicはさらに、別の評価でもNLAを使い、

と報告しています。
この差はかなり大きいです。
要するに、モデルは評価環境では“気づいている”ことが多いが、実利用ではかなり少ないということです。安全性テストの解釈が難しい理由が、ここにあります。
NLAのもう1つの用途が、auditing(監査)です。
これは、モデルが変な振る舞いをしていたときに、「何かおかしな目的を持っていないか」を調べる作業です。
Anthropicは以前から、意図的にmisaligned(ずれた)、つまり人間の意図と合わないモデルを使った実験をしています。今回の「auditing game」では、Claude Haiku 3.5の変種をわざと変な目的で訓練し、それが原因で
といった奇妙な行動をするようにしていました。
監査者の仕事は、こうしたバラバラの奇行の裏にあるひとつの隠れた動機を当てることです。
結果は、かなり興味深いものでした。
つまり、NLAは「変な振る舞いの断片」を眺めるだけでなく、その裏にある意図を直接読む助けになる可能性があるわけです。
これは実用上かなり大きいと思います。
なぜなら、現実の問題では「原因データ」がめちゃくちゃ珍しいことがあるからです。そもそも、どの学習データが悪さをしたのか特定できないケースもあります。そういうときに、モデルの内側から直接ヒントを拾えるのは強いです。
Anthropic自身も、NLAにはかなりはっきりした限界があると認めています。
NLAは、文脈にない内容を勝手に言うことがあります。
つまり、ハルシネーションを起こします。

たとえば、実際には存在しないフレーズを「文脈にあった」と述べてしまうことがあるそうです。これは文章としてはすぐ見破れることもありますが、モデルの内面的な推論についての誤りになると、検証が難しくなります。
だからAnthropicは、NLAの出力を1文単位で盲信するのではなく、全体のテーマとして読むことを勧めています。さらに、別の方法でも裏を取るべきだとしています。
これ、かなり健全な姿勢だと思います。
解釈系の手法は、当たっているのか外れているのかが曖昧になりやすいので、単独で信じ切るのは危険です。
NLAは高価です。
訓練には2つのモデルを使った reinforcement learning が必要で、推論時にはactivationごとに数百トークンもの説明を生成します。
これは、長い会話をずっと追う用途や、AI訓練中の大規模監視にはかなり不向きです。
要するに、便利だけど重い。ここは正直、研究段階らしい課題です。
それでもAnthropicがNLAを押す理由は明快です。
人間が読める言葉で、モデルの内側を説明するという方向性が、今後かなり重要になるかもしれないからです。
従来の interpretability 手法、たとえば sparse autoencoders や attribution graphs も有用ですが、やはり専門家が解釈して初めて意味が出る場面が多いです。
それに対してNLAは、少なくとも見た目はストレートに文章です。
「このモデルは何を考えているの?」という問いに、かなり直接に近づいています。

個人的には、ここが一番ワクワクします。
AI安全性の研究って、どうしても数式やベクトルの世界に閉じがちですが、NLAはそこに**“読める言葉”**を持ち込む。これは、研究者だけでなく一般の人にとっても理解の橋渡しになる可能性があります。
Natural Language Autoencodersは、Claudeの内部状態を自然言語に変換して、モデルの「言っていない思考」を読むための新しい手法です。
まだ完璧ではなく、ハルシネーションやコストの問題もあります。
それでも、
において、かなり強力な武器になりそうです。
AIが賢くなるほど、「何を答えるか」だけでなく「内部で何を考えているか」が重要になります。
NLAはその入口を、かなり面白い形で開いた技術だと思います。
