sinfo で使える資源を確認し、sbatch で投入→squeue で状況確認→sacct / scontrol show job で追跡、必要に応じて scancel で停止するジョブスケジューラとは、限られた計算資源(CPU/GPU/メモリなど)の上で、タスクをどう順序づけて実行するかを管理するためのツールです。典型的には次のような課題をまとめて扱います。
HPC(High Performance Computing)環境、いわゆるスパコンでは長時間ジョブが前提になるため、昔からジョブスケジューラは中心的な役割を担ってきました。特に計算処理が長く、試したい実験パターンが増えていく状況では、ジョブを登録・管理して効率よく回す価値が大きくなります。
一方、近年は Coding Agent(例:Claude Code や Codex)の進化で開発の回転が速くなりました。結果として個人の開発環境でも、次のような「ジョブ管理」が便利に感じられる場面が増えています。
そこで本記事は、ローカル環境でも Slurm 的な運用感でジョブを扱うための入り口として、軽量スケジューラ slotd を紹介しつつ、基本コマンドの読み方を整理します。
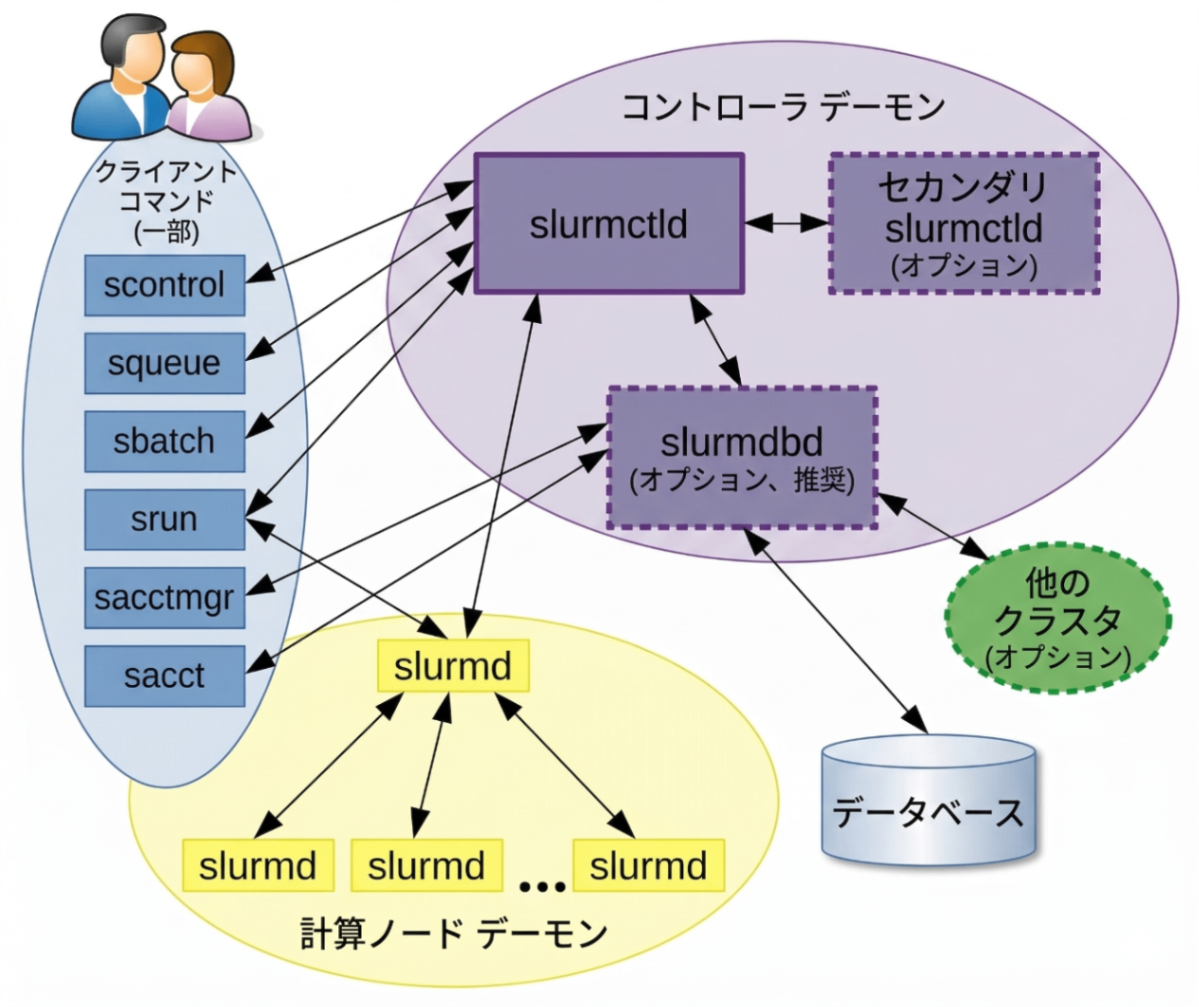
ジョブ管理の世界で最もよく知られた存在の1つが Slurm Workload Manager です。Slurm は Simple Linux Utility for Resource Management の略で、ローレンス・リバモア国立研究所を中心に開発されました。
SlurmはLinux向けに設計された強力なジョブスケジューラで、もともとは大規模な並列計算を効率よく管理するために作られ、多くのスーパーコンピュータや研究機関で採用されています。TOP500のランキングでも、半分以上が Slurm を採用しているとされます(原文参照)。
また Slurm は オープンソースソフトウェアとして公開されており、無料で利用できます。主要なLinuxディストリビューション向けにパッケージも提供されています。

Slurmの中核機能として、次の3つが設計の中心にあります。
利用者(クライアント視点)では、昔から変わらない操作体系でジョブ投入・管理ができます。たとえば次のようなコマンド群です。
sinfo:計算ノードやパーティションの状態確認sbatch:バッチジョブ投入srun:ジョブ起動squeue:待機中/実行中の確認この「操作感の共通性」が広く共有されている(=枯れている)ことも、事実上の標準として使われている理由の一つです。
Slurmが便利なのは、次のような情報をジョブに付けて投入し、あとはスケジューラに実行状態管理を任せられる点です。
これにより、資源指定・キューイング・状態管理・ジョブ制御が「同じ操作体系の中」で完結します。
共有クラスタではなくローカルマシン(例:デスクトップPC、あるいは vast.ai などで借りたマルチGPU環境)だけを対象にする場合、Slurm環境の構築は過剰になりがちです。ローカル用ジョブスケジューラとしては GPU Task Spooler なども知られていますが、HPC向けのジョブスケジューラとは使用感が異なります。
そこで原文では、「普段使い慣れているSlurmと似た操作感で、ローカルでも気軽に使えるジョブスケジューラが欲しい」という動機から、Slurm風の簡易ジョブスケジューラを開発し、slotd を紹介しています(GitHub: https://github.com/ymgaq/slotd)。

slotdは次の狙いで作られた Rust製の軽量ジョブスケジューラです。
そして、ユーザー向けコマンドは Slurmと共通させています。具体的には次のコマンド名です。
sbatchsrunsallocsqueuesacctscontrolscancelsinfoさらに、コマンド名だけでなく、使い方やオプションも可能な範囲でSlurmと揃える方針です。結果として、ローカル環境でも次のような基本流れが成立します。
sbatch でジョブ投入squeue で確認sacct で完了状態を見るslotdの内部は比較的シンプルに作られています。
ただし「ローカル用途の割り切り」をしている一方で、開発や運用に必要になりやすい主要機能は実装されています。原文で挙げられている例は以下です。
--begin--exclusive--requeueHPC環境を使わないがジョブスケジューラを勉強したい人にとって、入門として扱いやすいツールだと期待されています。詳細はドキュメントページが整備されているとのことです。
slotdの導入要件は比較的少なく、Linux(またはWSL)上で Rust開発環境が使えれば動かせます。
systemd コマンドの権限が必要nvidia-smi が実行できる必要公式の方法でRustをインストールできます(原文のコマンド):
curl https://sh.rustup.rs -sSf | sh
インストールはリポジトリをcloneしてスクリプトを実行する流れです。
git clone https://github.com/ymgaq/slotd.git
cd slotd
./scripts/install.sh
この install.sh は次のようなことを行うと説明されています。
cargo で releaseビルド~/.local/bin 以下に slotd 本体と、Slurm互換コマンドのaliasを配置~/.local/share/slotd に作成~/.config/slotd/slotd.env に書き出しsystemd --user が使える環境なら、ユーザーサービスのインストールと起動までまとめて行うインストール後は、まず daemon が動いていることを前提に基本コマンドを確認します。
sinfosqueuesacct例として原文では次のような出力形式が示されています。

sinfo(設定済みパーティションが表示される想定)squeue と sacct(初回起動直後なら空のはず)この段階で、使えるパーティションやリソースの見え方を理解しておくと後が楽になります。
ジョブスケジューラの基本は、ジョブを「目的に応じて種類分け」して運用することです。原文では大枠として次のような切り分けが紹介されています。
再現性の高い実行を後で流したいなら sbatch、短く試したいなら srun や salloc、似た実験を多数回ならアレイジョブ、という対応付けです。
また日常的によく使う役割はある程度決まっています。
sinfo:使える資源を見るsbatch:ジョブを投入するsqueue:今動いているジョブを見るsacct:終わったジョブの履歴を見るscancel:不要になったジョブを止めるsinfo:実行可能な資源(パーティション)を確認する最初に確認したいのは「どのパーティションが有効か」です。ここで使うのが sinfo です。
原文の例では sinfo の出力に、次のような情報が含まれています。

例:
cpu(GPUなし)gpu*(GPUあり。featureとして cpu,rtx5090 のような表示)slotd では CPU向け/GPU向けなどのパーティションが設定されていれば、それぞれが表示されます。ここで得たいのは次の情報です。
cpu、学習/推論なら gpu のように、投入前に実行先のイメージを持てるさらに詳細に見るには sinfo -l を使います。原文の例では sinfo -l に CPU/GPU割当可能数や、メモリ状況まで含む表示があることが示されています。たとえば、
ジョブが開始しない場合も、まず sinfo -l を見て次を確認するとよい、と原文では述べています。
CPU数/メモリ/GPU数 が大きすぎないかsbatch:バッチジョブを投入する実際の計算を「順番待ちや資源管理を含めて」登録する基本コマンドが sbatch です。対話的にその場で走らせるのではなく、スケジューラに任せます。
--wrapsbatch は --wrap を使うと、1行のコマンドをそのまま渡して投入できます。
sbatch --wrap 'echo hello from slotd'
![]()
投入に成功すると、
Submitted batch job 1のように job id が返ります。以後の確認や詳細表示はこの id を使います。
原文では「実運用では --wrap だけでなくジョブスクリプトを使うことが多い」と述べています。理由は次の通りです。
これらを sbatch で読みやすい形にまとめられるためです。
例として train.sh を用意し、スクリプトを sbatch で投入します。
sbatch --job-name train-base --partition gpu --cpus-per-task 8 \
--mem 16G --gpus 1 --time 04:00:00 train.sh
原文で挙げられている代表的オプションは以下です。
-J, --job-name:ジョブ名(学習名/実験名の識別)-p, --partition:実行先パーティション(cpu/gpuなど)-c, --cpus-per-task:1タスクあたりのCPU数(DataLoaderや前処理調整)--mem:必要メモリ(OOM回避のため予約)-G, --gpus:必要GPU数(学習/推論で確保)-t, --time:制限時間(runaway防止)-o, --output:標準出力の保存先(ジョブ単位ログ保存)--wrap:1行コマンド実行(軽い確認/短い評価)GPU学習の文脈では特に --partition / --cpus-per-task / --mem / --gpus / --time / --output が頻出、と原文では述べています。

#SBATCH を書く(再実行しやすくする)原文では、ジョブ投入時のオプションをスクリプト先頭にまとめて書く方法も紹介されています。たとえば train_vit.sh のようにします。
#!/usr/bin/env bash
#SBATCH --job-name train-vit
#SBATCH --partition gpu
#SBATCH -cpus-per-task 8
#SBATCH --mem 16G
#SBATCH --gpu 1
#SBATCH --time 08:00:00
#SBATCH --output logs/%j.out
echo "hostname: $( hostname )"
nvidia-smi
python train.py --config configs/vit_base.yaml
このスクリプトを投入するのはシンプルに:
sbatch train_vit.sh
投入成功時は Submitted batch job 17 のように job id が返ります。
%j 展開とログ分割-o logs/%j.out のようにしておくと、%j が job id に展開され、たとえば logs/17.out のようにジョブごとのログが分かれます。
nvidia-smi を先に打つ意味原文ではスクリプト内で nvidia-smi を打つ例が示されています。意図は「学習前のGPU状態をログに残す」ことです。失敗解析や条件追跡のときに役立ちます。
こうした運用により、単に学習を回すのではなく、
のような条件が ジョブとして明示され、あとから見返せる形になります。スクリプトを train_vit.sh / train_llm.sh / eval_vit.sh のように分けていくと、ローカルでも整理された運用ができます。

squeue:待機中/実行中のジョブを見るジョブが待機中(queued)または実行中なら squeue で確認できます。
出力の例(原文のフォーマット)は次の通りです。
JOBID | PARTITION | NAME | USER | ST | TIME | NODELIST(REASON)ここで重要なのが以下です。
R:実行中PD:待機中Resources や Dependency が挙がっています)つまり squeue は「今なにが走っていて、なにが詰まっているか」を見るコマンドです。
原文の例では、
train-vit や preprocess:実行中(R)eval-vit:GPUが空くのを待っている(PD)export-onnx:dependency付きで前段完了待ち(PD)という読み取りができる、と説明されています。
ジョブが開始しないなら、まず ST が PD になっていないか確認し、NODELIST(REASON) に出ている理由を見ます。

Resources → 資源待ちDependency → 依存ジョブ待ちこの2点だけでも、最初の切り分けとして有効だと原文で述べられています。
scancel:ジョブを止める途中で止めたい場合は scancel を使います。
scancel 17
これは job id 17 を停止する、という意味です。原文では次のような場面が例示されています。
ジョブスケジューラを使うと、単にプロセスを kill するのではなく、安全に停止できる点も利点とされています。
sacct:終了済みジョブの履歴を見る完了後の情報は sacct で見ます。
sacct
例として原文には次のような項目が示されています。

ここで、squeue との違いは次のように説明されています。
squeue:今動いているものを見るsacct:終わったジョブも含めて履歴を見るローカル運用では失敗したジョブをあとから追うことが多いので、sacct は重要だとされています。
原文で示されている見方は State と ExitCode です。
COMPLETEDFAILEDCANCELLED例では、train-vit が失敗してから再投入された後、別のrunで手動停止されたことが分かる、という説明がされています。
scontrol show job:1ジョブの詳細を調べるより深く確認したい場合、scontrol show job <id> が使えます。
scontrol show job 1
原文の出力例では、ジョブの状態、理由、要求リソース、作業ディレクトリ、出力先、タイムスタンプなどがまとまって確認できます。

注目すべきポイントとして原文は以下を挙げています。
State と Reason で最終状態を確認Command で実際に何を実行したかを見るStdOut と StdErr でログ保存先を確認ReqTRES と AllocTRES で「要求した資源」と「実際に割り当てられた資源」を把握失敗したジョブのデバッグでは、最終的にこの詳細出力とログファイルを見ることになる、と原文では説明されています。
srun と salloc:対話的に使う(sbatchとの役割差)sbatch が「登録してあとで流す」なら、srun と salloc は「対話的にその場で作業したい」場面で使うコマンドです。
srun は、1つのコマンドを今すぐ実行したいときに使います。原文の例には、次のようなユースケースが挙げられています。
操作感としては通常のシェルでコマンドを打つ感覚に近いが、実行はスケジューラ管理下に置かれる、という位置づけです。
簡易例:
srun --label --unbuffered -- echo hello
さらに実用的には、資源指定つきでコマンドを走らせます。
srun -p gpu -c 4 --mem 8G -G 1 -- python scripts/check_gpu.py
--label:task labelを出力に付ける--unbuffered:標準出力を即時に見たいときに役立つ
salloc は「コマンド」ではなく、作業用の枠そのものを確保したいときに使います。
たとえば次のような場面です。
python や ipython を起動して試行錯誤例:
salloc -p gpu -c 4 --mem 8G -G 1 -t 00:30:00
Granted job allocation 21 のように allocation が確保され、そのあとで作業を行います。原文では最もわかりやすい流れとして、
-確保した allocation の中で srun --pty bash してシェルへ入る
という方法が示されています。
srun --pty bash
そのallocationの中で例えば torch.cuda.is_available() を試す、といった操作につながります。
原文の説明を要約すると、
srun:コマンド単位で実行する(検証・確認・短い試行向け)salloc:作業時間/枠として資源を確保する(対話的デバッグ向け)
という整理です。sbatch が再現性の高いバッチ実行向けであるのに対し、srun/salloc は実験前の確認やデバッグに向く、と結論づけています。
--array で並列ジョブを流す(原文の言及範囲)さらに、実験をまとめて流すときに便利なのが job array や dependency です。job arrayを使うと、似た条件の実験をまとめて投入できます。
たとえば、ハイパーパラメータ違いの評価を10本まとめて流したい場合、1本ずつ sbatch するのではなく、配列ジョブとしてまとめて投入します。
原文では %2 を同時実行数の意味として例示しており(「0から9までの10個のtaskを持つ配列ジョブ」「%2は同時に2個まで」など)、配列ジョブとその制御の概念が説明されています。
※今回の貼り付けでは
--arrayの詳細部分が途中で省略されているため、ここでは原文に含まれている範囲(概念と例の方向性)に留めます。
原文の内容を踏まえると、ローカル運用でGPUを効率よく回すための基本導線は次のようになります。
sinfo -lで資源状況を把握(要求が通る見込みを確認)sbatch**(条件をジョブに固定し、ログも残す)squeue**(STと理由で詰まりを把握)sacct / scontrol show job**で追跡(失敗原因の調査)scancelで停止(優先順位に合わせて整理)srun / salloc**(対話的な試行を資源管理下で行う)--array や dependency(投入の手間と管理コストを減らす)このように、Slurmがクラスタ運用で提供してきた“考え方と操作体系”を、slotdを通じてローカルにも持ち込むことで、個人開発でもキュー管理・状態追跡・GPU競合回避の恩恵を受けられる、というのが原文の主張です。
この記事はAIにより自動生成されました
