Interfazeの主張は、かなりシンプルです。
「LLMは何でもこなせるけれど、決まった作業を正確に大量処理する用途では、もっと向いた設計がある」
たとえば、50ページのPDFを読んで、そこにある文字を全部抜き出し、さらに各単語の座標まで取って、最後に中国語へ翻訳する——こういう作業は、人間でも面倒ですし、LLMでもミスが出やすい。
Interfazeは、こういう**“コンピュータ的な正確さが必要な仕事”**にフォーカスしたモデルです。
ここが面白いところで、記事は「Transformerは万能」みたいな幻想にかなりハッキリ異を唱えています。
Transformer/LLMは、会話、推論、ニュアンス理解に強い。でも、OCRや物体検出のような仕事では、専用設計のモデルのほうが筋がいい、という立場です。これはかなり納得感があります。
記事では、TransformerモデルとCNN/DNNモデルを対比しています。
要するに、
「何でも答えられるAI」より「この仕事だけはめちゃくちゃ正確なAI」のほうが、現場では役に立つ場面がある、という話です。
これは本当に重要です。
AIの評価はつい「賢さ」ばかり見られがちですが、業務システムでは安定性・再現性・低コストのほうが勝つことが多いんですよね。
個人的には、ここをちゃんと狙っているのがInterfazeの強さだと思います。
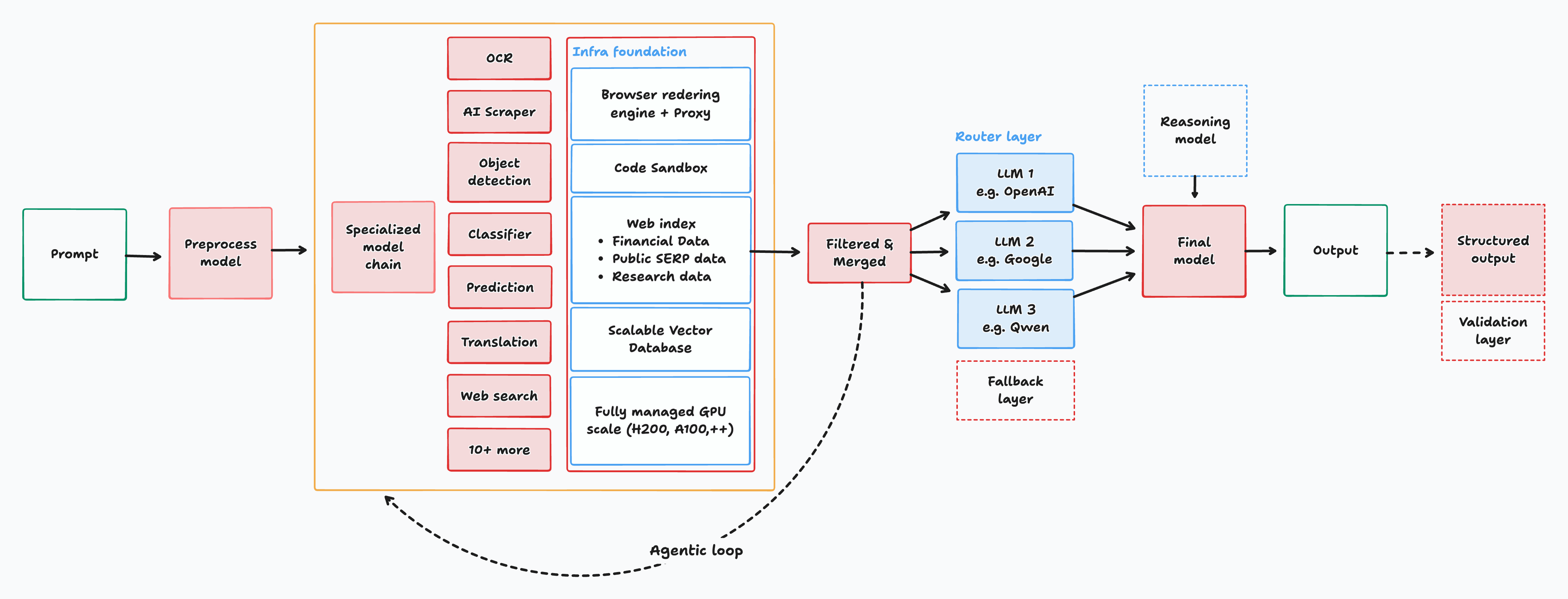
Interfazeは、記事によると
を組み合わせた新しいアーキテクチャです。
記事では、次のような用途を挙げています。
![]()
つまり、「会話AI」というよりは、マルチモーダルな業務処理エンジンに近い印象です。
記事にある仕様は次の通りです。
1M tokens級のcontext windowはかなり大きいです。
長文PDFや複数資料をまとめて扱う用途では、かなり魅力的だと思います。
Interfazeは、以下の9ベンチマークで競合と比較されています。
比較対象は、主に次のモデルです。
一部では専門系のサービスも意識していて、記事内では
記事の数値を見ると、Interfazeは多くの項目で優位です。たとえば:
この手のベンチマーク比較は、数字だけ見るとつい「全部勝ってる!」で終わりがちですが、実際に重要なのはどのタスクで強いかです。
Interfazeは、まさにOCR、構造化出力、音声認識、マルチモーダル理解に強いことを示したいわけですね。
記事で特に強調されているのがOCRです。
OCRとは、画像やPDFの中の文字を読み取る技術のこと。
昔からある技術ですが、実務では今でもめちゃくちゃ重要です。
たとえば:
Interfazeは、こうした用途で
などより良い結果を出したとしています。
さらに面白いのは、単に文字を読むだけでなく、画像の中の図やイラストも同時に検出できる点です。
これは、OCRが「文字だけの世界」ではなく、「レイアウトを理解する仕事」に進化していることを感じさせます。
記事では、structured output を大きなテーマとして扱っています。
structured output とは、AIに自由作文させるのではなく、
JSONのような決まった形式で、決まった項目を埋めてもらう出力のことです。
たとえば、
のような項目を、正確に埋める仕事です。
記事の面白い点は、
「LLMはJSONの形を守るのは得意でも、中身の値を正確に入れるのは苦手」
とかなり率直に言っているところです。
そこで彼らは SOB(Structured Output Benchmark) というベンチマークを作ったそうです。
正解をコンテキストに入れた上で、モデルがどれだけ正しくJSONを返せるかを見る、という考え方です。
これはかなり実務っぽい発想です。
理論上の賢さではなく、**“本当に業務で使えるか”** を測ろうとしている。こういう姿勢は好感が持てます。

VoxPopuli-Cleaned-AAでは、Interfazeはword error rate 2.4%で、かなり上位です。
しかも記事によると、1秒の計算で209秒分の音声を文字起こしできるとのこと。
比較としては:
音声認識は、精度だけでなく速度も超重要です。
会議録音や動画字幕の生成では、遅いモデルはそれだけで使いづらい。
なので、この速度の主張はかなり実用的です。
Interfazeは、Chat Completions API に対応していて、OpenAI互換のSDKからそのまま使えるそうです。
APIのベースURLを https://api.interfaze.ai/v1 に向ければよい、という設計です。
これは地味ですが大事です。
新しいAIサービスは、性能が良くても「使い始めるのが面倒」で脱落しがちです。
その点、既存のOpenAI系SDKで扱えるのはかなり強いです。
記事では、1回のリクエストで
をまとめてやる例が紹介されています。
つまり、「この画像から文字だけ抜いて終わり」ではなく、
どこに何があるかまで返すわけです。
業務システムだと、これがかなりありがたい。人間が後で確認しやすいですからね。
さらに記事では、<task>ocr</task> のようなタグで、モデルの一部だけを動かす発想も紹介されています。
これにより、
という利点がある一方で、
というトレードオフもあると説明されています。

この「万能ではなく、割り切って速く正確にする」という設計思想、かなり好きです。
AIってつい“何でもできる”方向に行きがちですが、現実には仕事を切り分けたほうが強いことが多いんですよね。
Interfazeの本質は、たぶん「新しいチャットAI」ではありません。
むしろ、AIを“会話相手”から“精密な業務部品”へ寄せる試みだと思います。
これはとても重要な方向性です。
今のAI市場は、賢いモデル競争に目が行きがちですが、実運用では次の要素が強いです。
Interfazeは、この現実的なニーズにかなり正面から答えようとしているように見えます。
個人的には、こういう「地味だけど本当に役立つ」AIの進化はかなり好きです。
派手な雑談より、請求書を正確に読んで、PDFをミスなく処理して、音声を高速で文字起こししてくれるほうが、実はずっと価値が大きい場面が多いからです。
もちろん、ベンチマークはベンチマークです。
実際の現場では、データの汚れ具合や例外処理、運用コストまで含めて評価する必要があります。
なので、「数字が良い=すぐ勝利」とは言えません。
でも、**“LLM一択ではない”** というメッセージはかなり説得力があると思います。
Interfazeは、LLMの万能性ではなく、特定タスクにおける高精度・低コスト・高速処理を追求した新しいモデルアーキテクチャです。
特に、
といった用途で強みを見せており、既存のフラッシュ/ミニ系モデルや専門サービスと正面から勝負しています。
「AIに何を任せるべきか」を考えるとき、
このInterfazeの発想はかなり示唆的です。
賢いAI だけでなく、正確に仕事を片づけるAI がこれからもっと重要になる——そんな流れを感じさせる記事でした。
参考: Interfaze: A new model architecture built for high accuracy at scale - Interfaze
