Anthropicが新しいモデル Claude Opus 4.7 を一般公開しました。ひとことで言うと、これは「難しいソフトウェア開発を、より長く、より正確に、より自律的にこなせるモデル」です。
AIモデルの発表って毎回「すごいです」と言われがちですが、今回はかなり具体的です。特に advanced software engineering、つまり“人間でも骨が折れる複雑な開発作業”での改善が強調されています。

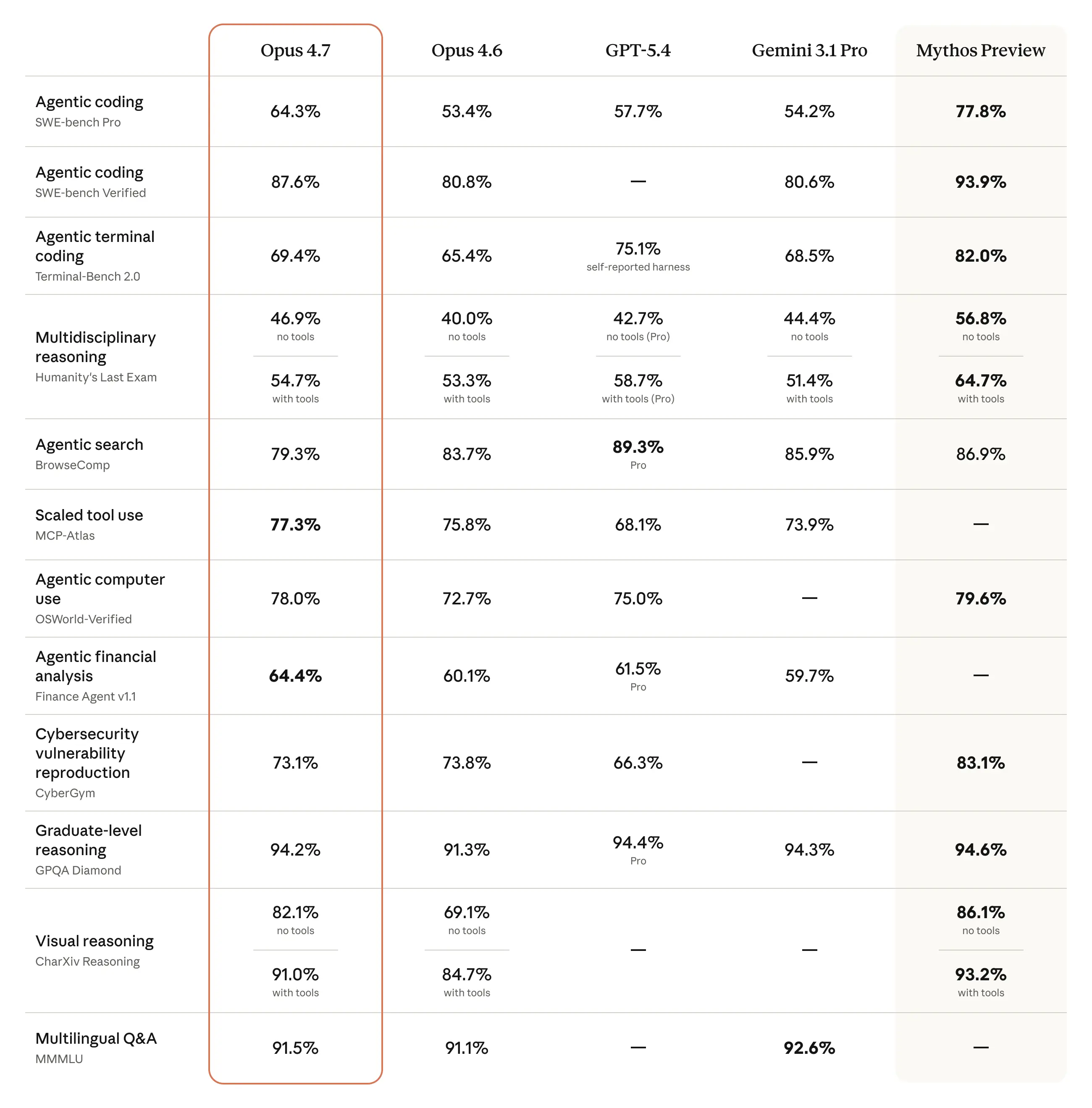

Anthropicによると、Claude Opus 4.7 は Opus 4.6 の明確なアップグレード です。
特に効いているのが、次のような場面です。


ここが面白いところで、Opus 4.7 は単に「答えを出す」のではなく、自分の出力を確認するような振る舞いが強いとされています。
これは地味に見えて、実運用ではかなり大きいです。AIは“それっぽいけど間違い”を出すことがあるので、自分でチェックする癖があるモデルは、現場ではかなりありがたいと思います。
Anthropicの説明では、ユーザーは「以前なら近くで監督しないと任せづらかった、いちばん難しいコーディング作業」を、Opus 4.7 に安心して任せられるようになってきたとのこと。
この表現、かなり重要です。AIが“補助輪”から“実務担当”に近づいている感触があります。


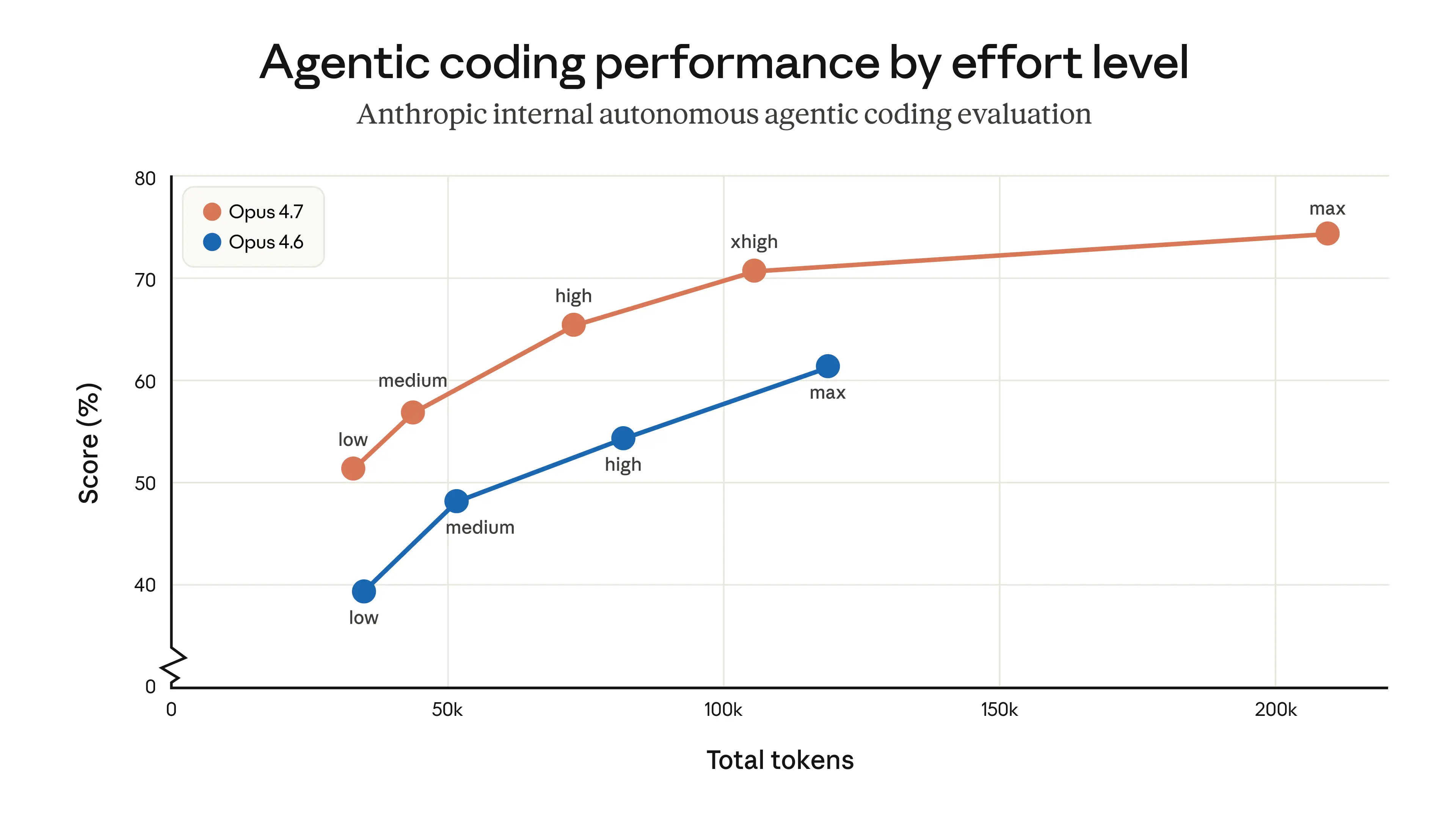
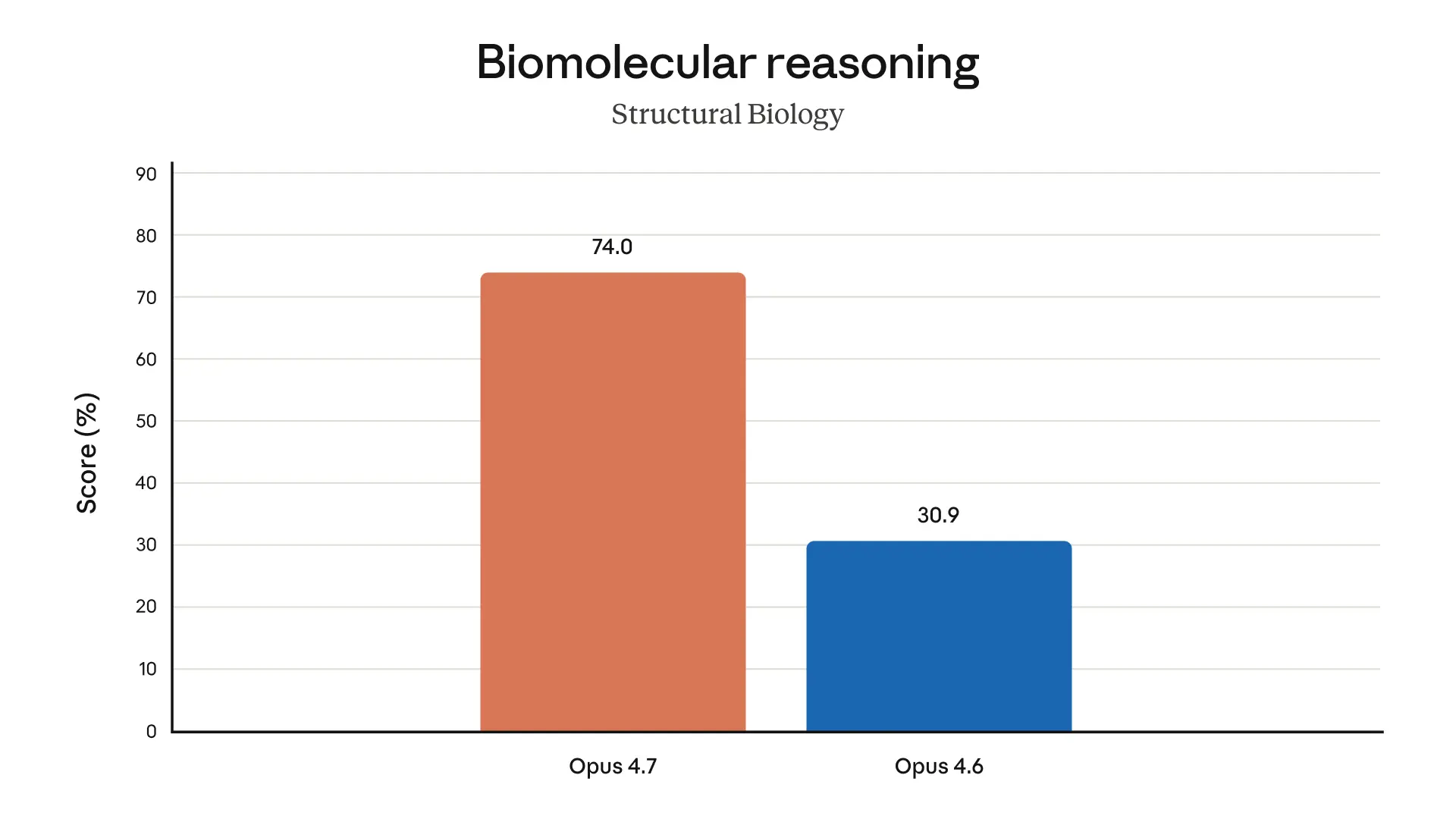
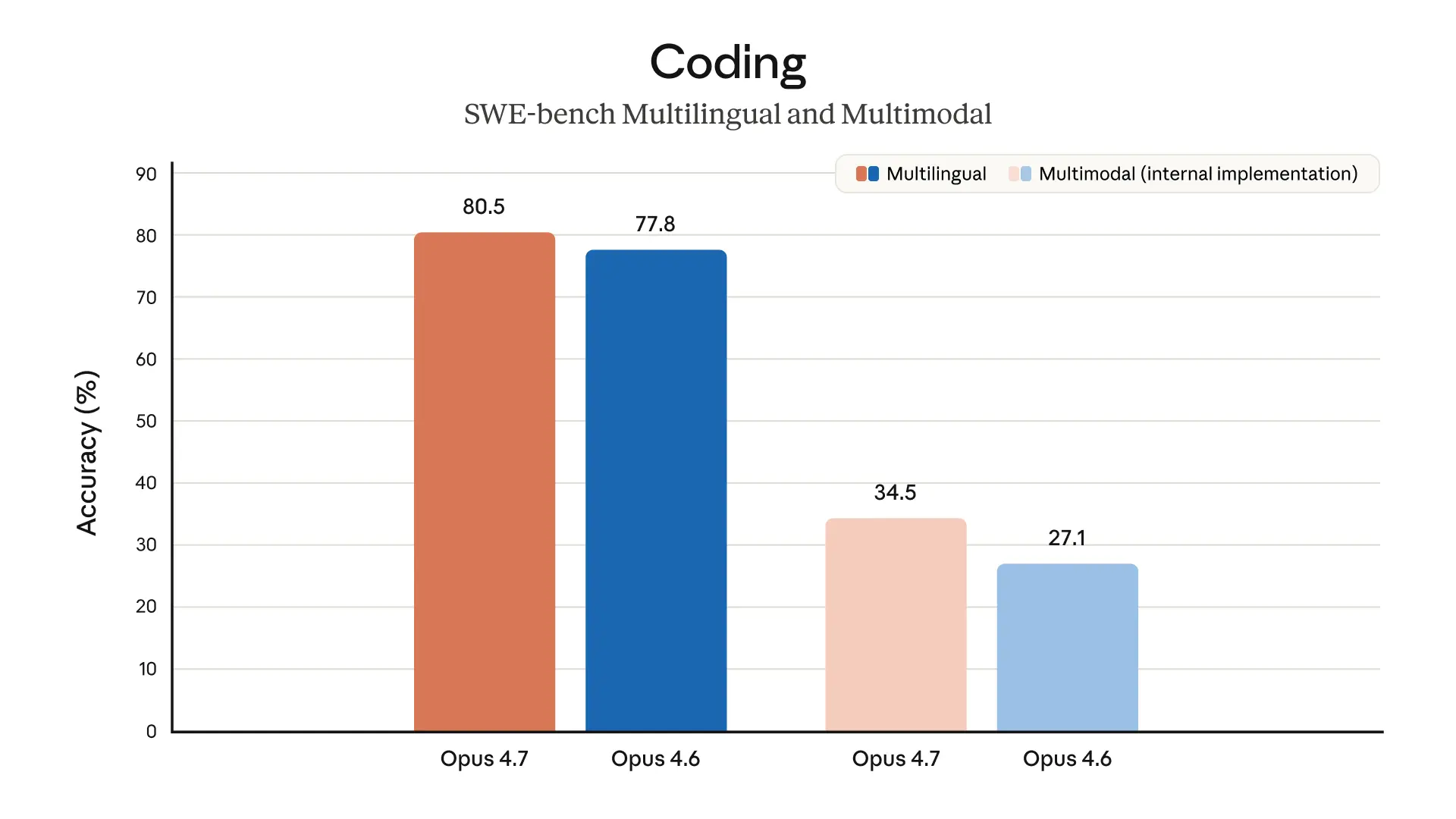
Opus 4.7 は、ソフトウェアエンジニアリングの難問で改善しています。
Anthropicは、93件の coding benchmark において Opus 4.6 比で解決率が13%向上 したと述べています。しかも、Opus 4.6 でも Sonnet 4.6 でも解けなかった4つのタスクを解いたとのことです。

こういう数字は、AI好きとしてはかなりワクワクします。
「13%」だけ聞くと小さく見えるかもしれませんが、難問の世界ではこの差が大きいことがあります。しかも、単純な一問一答ではなく、長時間・多段階・バグ修正・検証みたいな、現場で本当に面倒な作業に効いているのがポイントです。

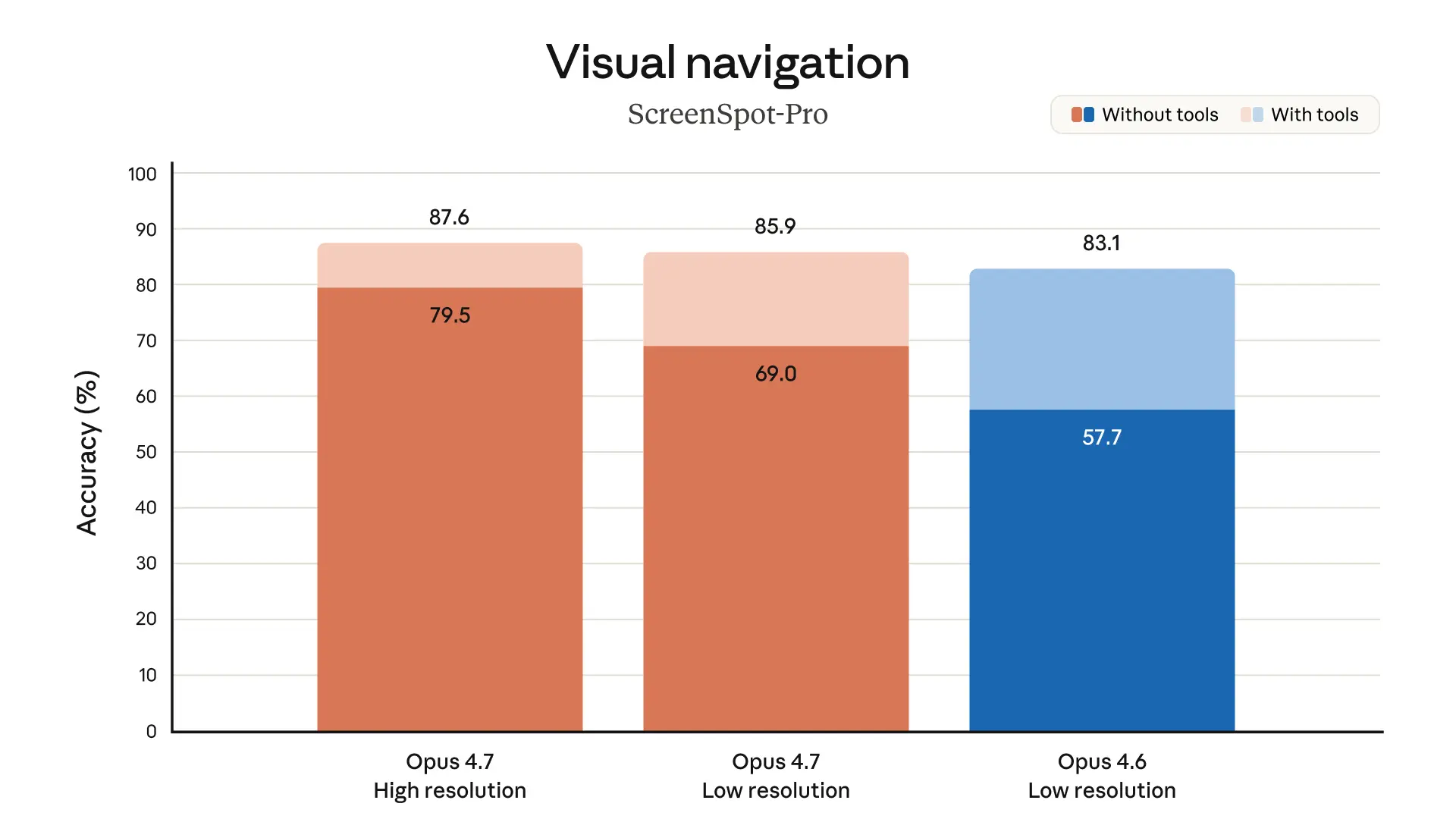
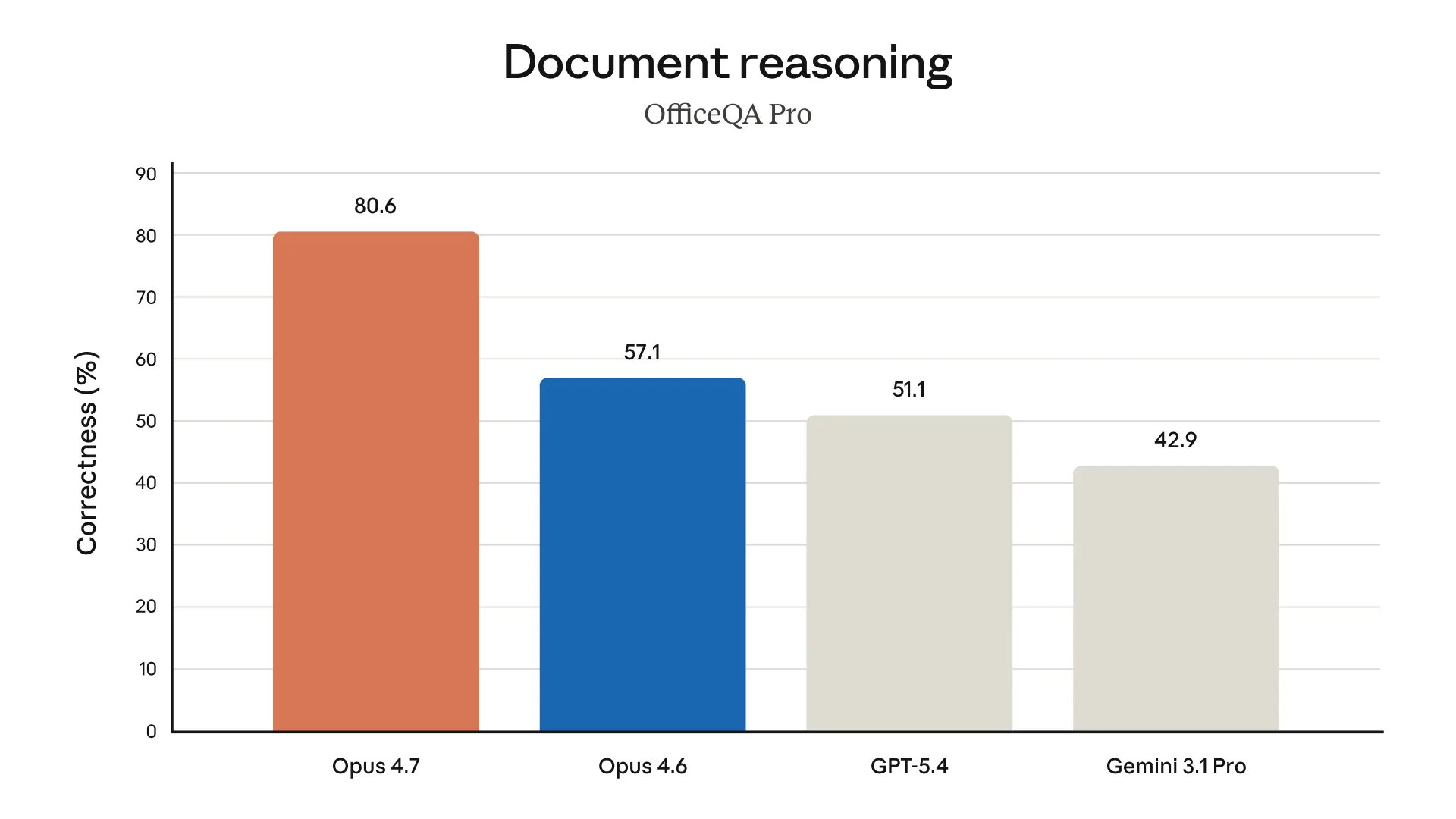
Opus 4.7 は vision、つまり画像理解も改善しています。
しかも「より高解像度の画像を見られる」とあります。これは、図表、技術資料、スクリーンショット、化学構造式、複雑なダイアグラムなどで効いてきそうです。

地味だけどかなり重要です。
AIがコードを書くだけでなく、画像から情報を読み取り、作業に反映する場面はどんどん増えています。たとえば、障害画面のスクリーンショット、設計図、スライド案、あるいは研究・法務系の文書などです。画像認識の精度が上がると、AIの守備範囲が一気に広がります。

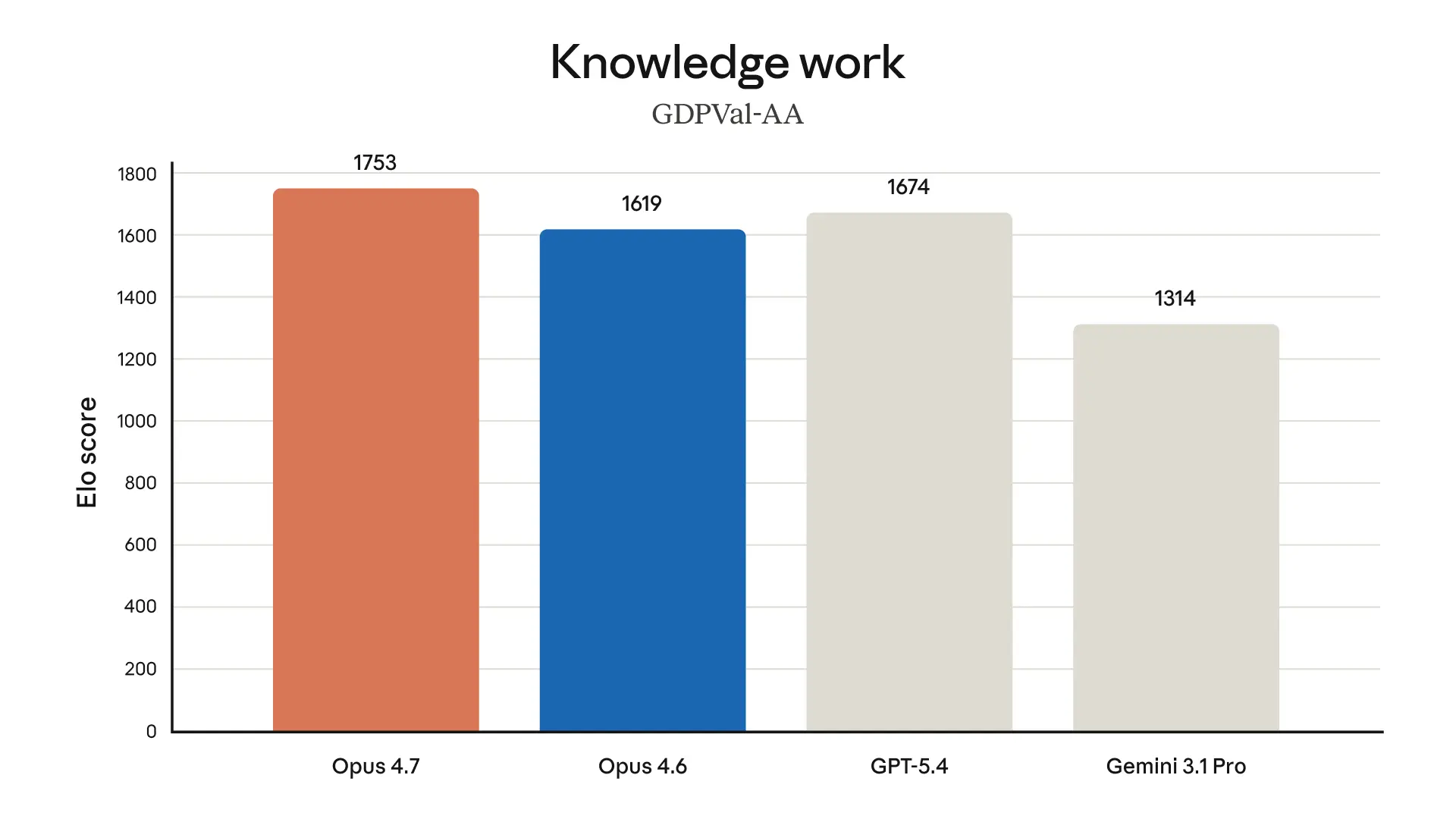
Anthropicは、Opus 4.7 が professional tasks を仕上げるときに、より tasteful で creative になったとしています。
UI、slides、docs の品質が上がった、という話ですね。
これ、個人的にはかなりおもしろいです。
AIは“正しい”だけでなく、“見栄えがいい”“そのまま出せる”が重要になってきています。開発者や企画職の人は、正確な文章よりも「そのまま社内に見せられるか」「顧客に出せるか」が大事だったりします。そこに効くのは、かなり実務的な進化です。


今回の発表で注目すべきなのが、Cybersecurity に関する扱いです。

Anthropicは先週、Project Glasswing を発表し、AIモデルのサイバーセキュリティにおけるリスクと利点を取り上げました。その流れの中で、今回は より能力の低いモデルで先に新しいサイバー安全対策を試す方針を示しています。
Opus 4.7 はその最初のモデルで、Claude Mythos Preview ほどサイバー能力は高くないとされています。

さらに、禁止されている、または高リスクのサイバー用途につながるリクエストを自動検知してブロックする safeguards を搭載してリリースしています。

ここはかなり現実的だと思います。
AIが強くなるほど、便利さと危険性はセットで増えます。Anthropicは、いきなり最強クラスを全面展開するのではなく、安全策を先に運用し、現実の利用から学ぶという進め方を取っています。少なくとも姿勢としては筋が通っています。

一方で、正当なセキュリティ用途、たとえば vulnerability research、penetration testing、red-teaming などを行う専門家向けには、Cyber Verification Program への参加案内もあります。
つまり、「危ない用途は抑える。でも、正当なセキュリティ研究は支援する」という整理です。

うれしいのは、価格が Opus 4.6 と同じだという点です。


この価格据え置きは、地味にすごいです。
AIモデルは性能が上がると値上げされることも多いので、性能向上+価格維持 はかなり印象がいいです。開発者目線では、導入判断がしやすくなります。


Anthropicは、早期テスターや提携企業から多くのコメントを載せています。
こういう“企業のコメント集”は宣伝っぽく見えることもありますが、今回は内容がかなり具体的です。
たとえば、以下のような評価がありました。


このあたりは、AIを実務で使っている人ほどピンとくるはずです。
正直、ベンチマークの点数だけ高くても、現場で「途中で止まる」「同じことを繰り返す」「変な fallback を出す」だと使い物になりません。
その意味で Opus 4.7 は、**“賢い”だけでなく“現場で使える”方向に進んでいる**のが良いです。


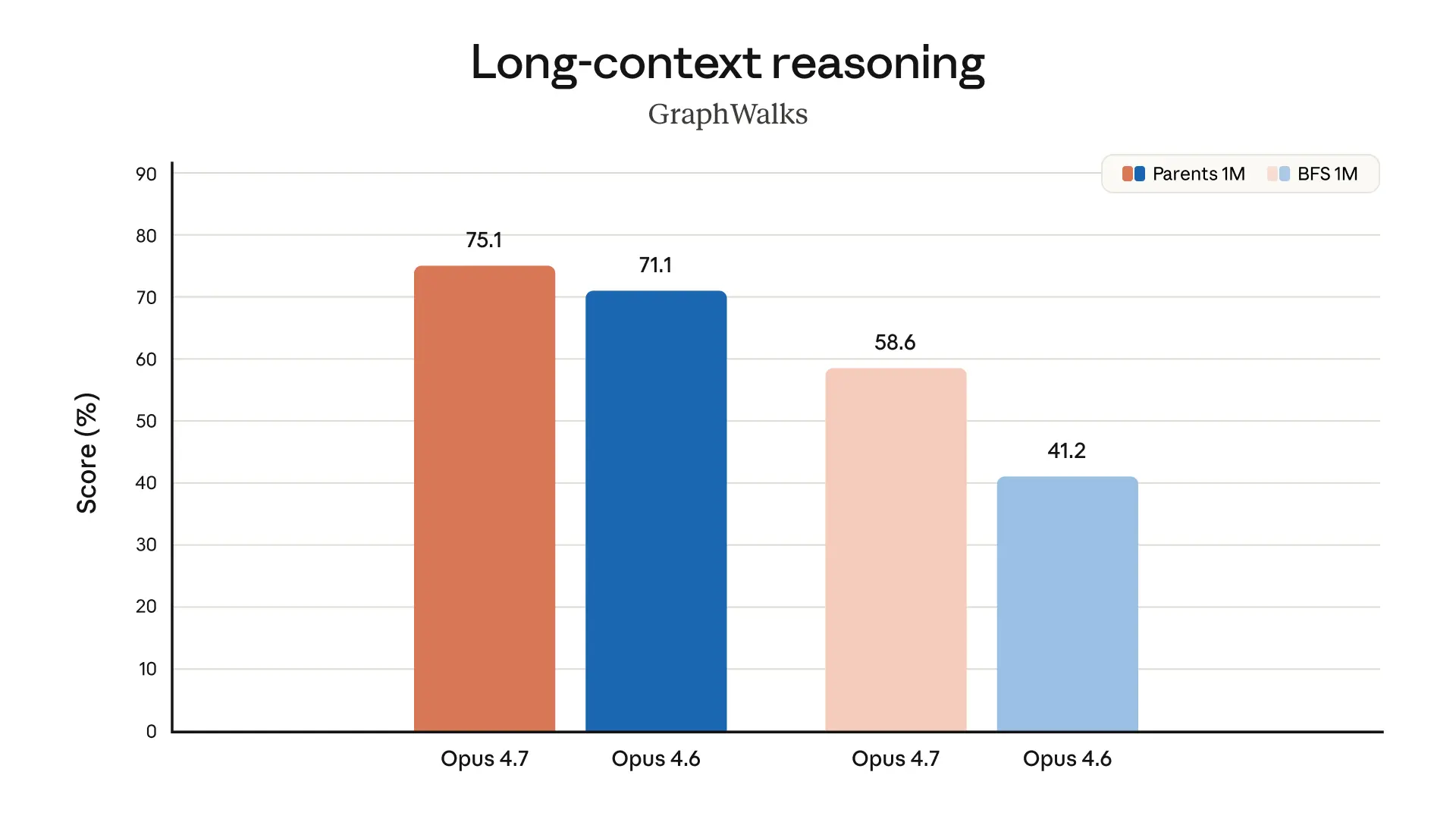
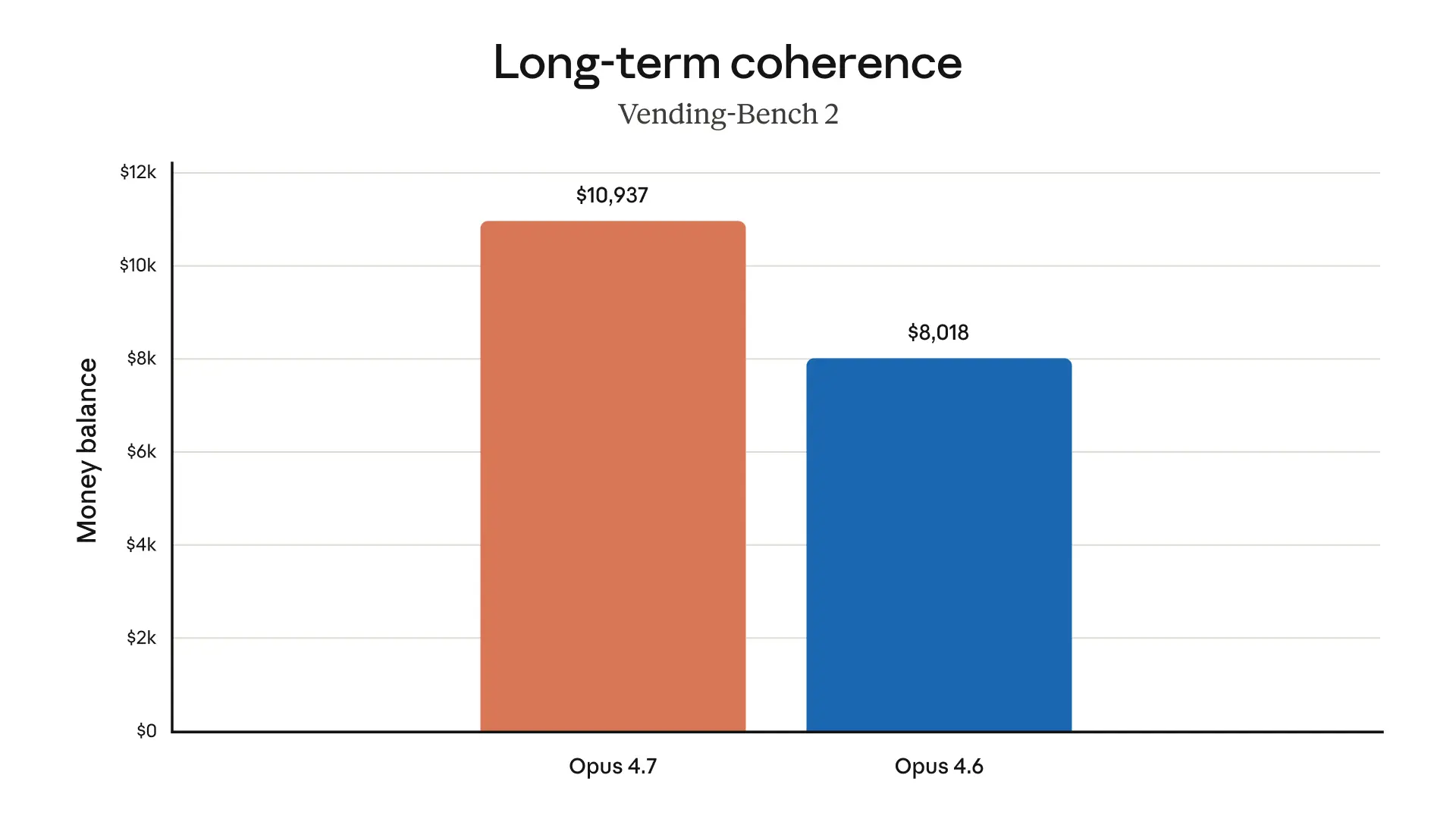
個人的にこの発表でいちばん面白いのは、Opus 4.7 が 長い作業をやり切る力をかなり重視している点です。

AIの性能って、つい「正答率」ばかり見がちです。
でも実際の開発では、

この“粘り”がすごく大事です。

Opus 4.7 はそこを強化しているように見えます。
だから、単発の質問応答よりも、エージェント的な作業、つまりAIに手順を持たせて何段階も実行させる使い方で価値が出やすいのではないかと思います。

Opus 4.7 は、特に次のような人に向いていそうです。
逆に、簡単な要約や軽い相談だけなら、ここまでのモデル性能はオーバースペックかもしれません。
ただ、「難しい仕事ほど効く」タイプの進化なので、ヘビーユースする人ほど恩恵は大きそうです。
Claude Opus 4.7 は、単に「前よりちょっと賢くなった」モデルではありません。
Anthropicの説明を読む限り、これは 本当に面倒な開発作業を、より自律的に、より正確に、より安定してこなすためのアップグレード です。
しかも、
まで揃っているのが良いです。
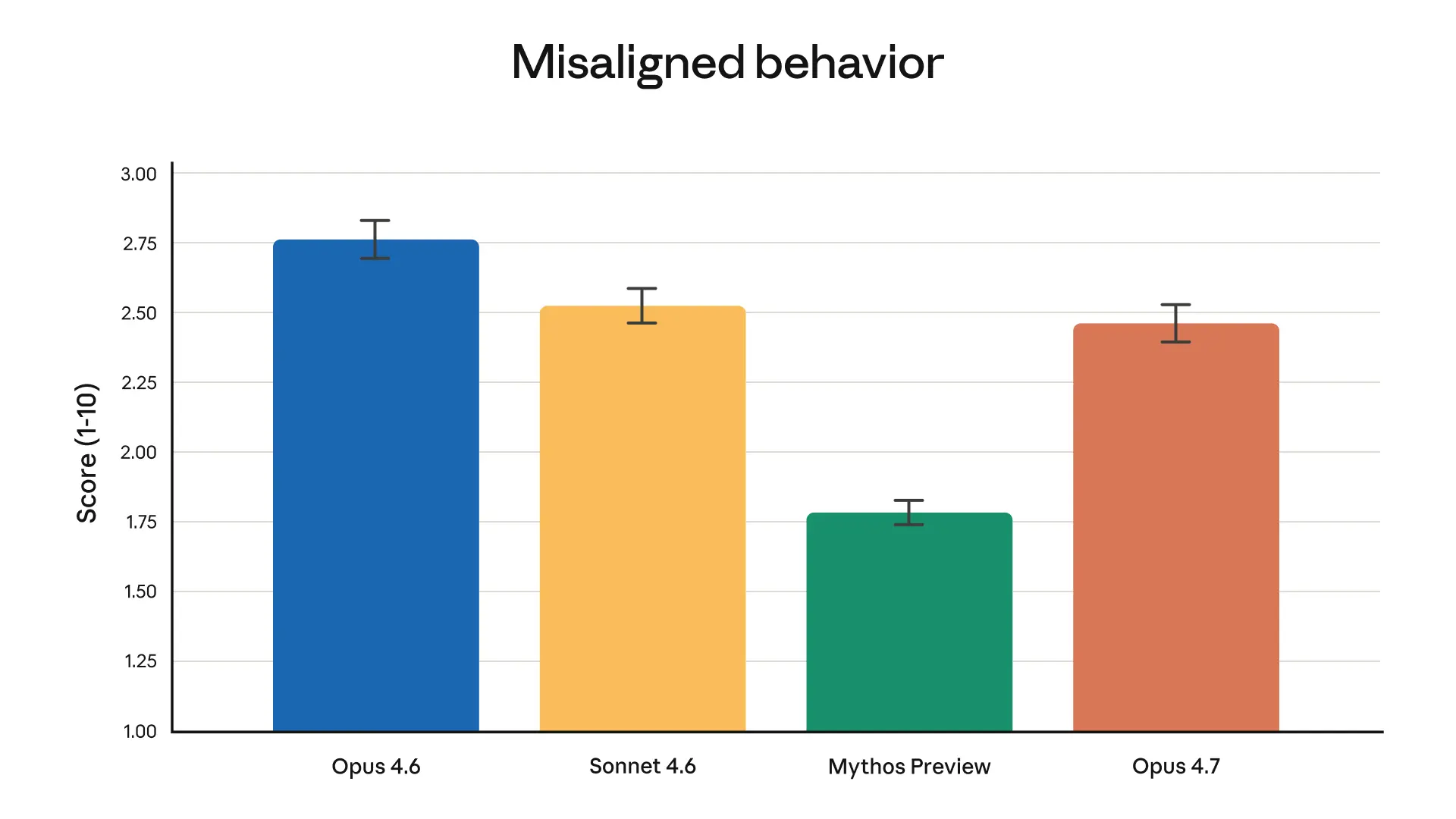
派手なデモより、「現場で最後まで仕事を片づける」力が増しているのが、いちばん価値ある進化だと思います。
AIが本当に役立つかどうかは、結局“途中で止まらず、ちゃんと終わるか”にかかっています。その意味で Opus 4.7 は、かなり本命感のあるアップデートです。