AI界隈には、真面目なベンチマークが山ほどあります。
でも Simon Willison の有名な「pelican riding a bicycle」ベンチマークは、その中でもかなり異色です。
ざっくり言うと、「ペリカンが自転車に乗る絵を生成させて、どれだけそれっぽく描けるかを見る」という、かなりふざけたテストです。
普通に考えれば「そんなものでモデルの性能がわかるの?」となるのですが、Simon はこれを半ば冗談として続けてきました。
今回の記事では、その最新回として、2026年4月16日に発表された2つの注目モデルを比べています。
Simon が今回出した絵の比較では、
Qwen3.6-35B-A3B のほうが良いペリカンを描いた、という判定でした。

特に Claude Opus 4.7 は、自転車のフレームをうまく描けなかったそうです。
このあたり、AIの絵って一見「それっぽい」けど、よく見ると構造が壊れていることがあるんですよね。
個人的には、こういう「ちゃんと自転車に見えるか」は、AI画像生成の地味だけど本質的な弱点が出やすいポイントだと思います。
しかも面白いのは、Qwen側がただのクラウドAPIではなく、
20.9GBの量子化済みモデルを MacBook Pro M5 上で動かしていたことです。
ここで出てくる「量子化」は、モデルを軽くしてローカルで動かしやすくする技術です。
精度と引き換えにサイズを小さくする感じですね。
つまり、Simon は「自分のノートPCで動く比較的小さなモデル」で、巨大な商用モデルに勝った、と書いているわけです。これはかなり痛快です。
Simon は Opus 4.7 に対して、もう一度試しています。
そのときは thinking_level: max を指定したそうです。
これはざっくり言うと、「もっとじっくり考えてから答えてね」という設定のようなものです。
ただ、それでも結果はあまり改善しなかったとのこと。
こういうの、ちょっと人間っぽくて面白いです。
「よし、もう一回本気出して」って言っても、期待したほど変わらない。
AIにも得手不得手があるし、設定をいじれば何でも解決するわけではない、という現実が見えます。

Simon はここで、少し冗談まじりに
「もしかして各社、僕のこのくだらないベンチマーク用に学習してるんじゃないか?」
という疑念にも触れています。
もちろん彼自身は、本気ではそう思っていないと言っています。
ただ、今回の結果は「ちょっと怪しいぞ」と思わせるくらいにはQwenが良かった、という話です。
その疑いを確かめるために、彼は秘密の予備テストとして
「フラミンゴが一輪車に乗るSVGを生成して」
というお題も試しています。
ここでのポイントは、SVG です。
SVGは、画像を点や線の情報で表す形式で、拡大しても荒れにくいのが特徴です。
つまり単なる絵ではなく、構造をちゃんと組み立てられるかが試されるわけです。
この追加テストでも、Simon は Qwen3.6-35B-A3B のほうを採用しています。
理由のひとつとして、Qwen のSVGに入っていた
<!-- Sunglasses on flamingo! -->
というコメントも評価していました。
このノリ、好きです。
技術的にはSVGの中身の質を見ているのですが、同時に「こういう遊び心をちゃんと入れられるモデルっていいよね」という人間的な好みもにじんでいます。
ここが一番大事です。

Simon 自身もはっきり書いていますが、この ペリカン・ベンチマークは最初からジョーク です。
「AIモデルを比較するための堅牢なテスト」として使うものではありません。
要するに、
という立ち位置です。
ただ、面白いのはここからです。
このジョークベンチマーク、昔は「くだらないけど、性能の差がなんとなく見える」程度だったのに、最近ではかなり実用寄りの絵が出るようになってきた、とSimon は言っています。
たとえば、Gemini 3.1 Pro は、場合によっては「普通にどこかで使えそうな」レベルの絵を出してきたこともあるそうです。
ペリカンが自転車に乗ってる絵に実用性があるのかはかなり怪しいですが、そこは話の趣旨ではありません。
つまり、AIが絵の構造を保ちながらSVGを出す能力自体が、かなり上がっているということです。
Simon は最後に、かなり冷静にこうまとめています。

このバランス感覚が、いかにも Simon Willison らしいです。
「一つの面白いタスクで勝った」ことと「総合性能で上回った」ことは、まったく別です。
ここを混同すると、AIニュースはすぐ話が盛られます。そこは注意したいところです。
個人的には、この話はローカルLLMの存在感がじわじわ増していることを示す小さな証拠だと思います。
クラウドの巨大モデルだけが正義、という時代ではなくなってきていて、
「自分のMacでここまでできるの?」という驚きが、かなり現実的になっています。
この投稿の魅力は、単なるモデル比較ではありません。
むしろ、
という、この微妙な温度差が面白いんです。
AIの話題って、つい「何点上がった」「何位になった」と硬い話になりがちです。
でも Simon のこのシリーズは、もっと人間的です。
「このペリカン、どっちが好き?」という軽い問いの中に、モデルの構造理解、出力の安定性、SVG生成のうまさみたいな要素が、意外と見えてくる。
この軽さと深さの同居が、かなり上手いなと思います。
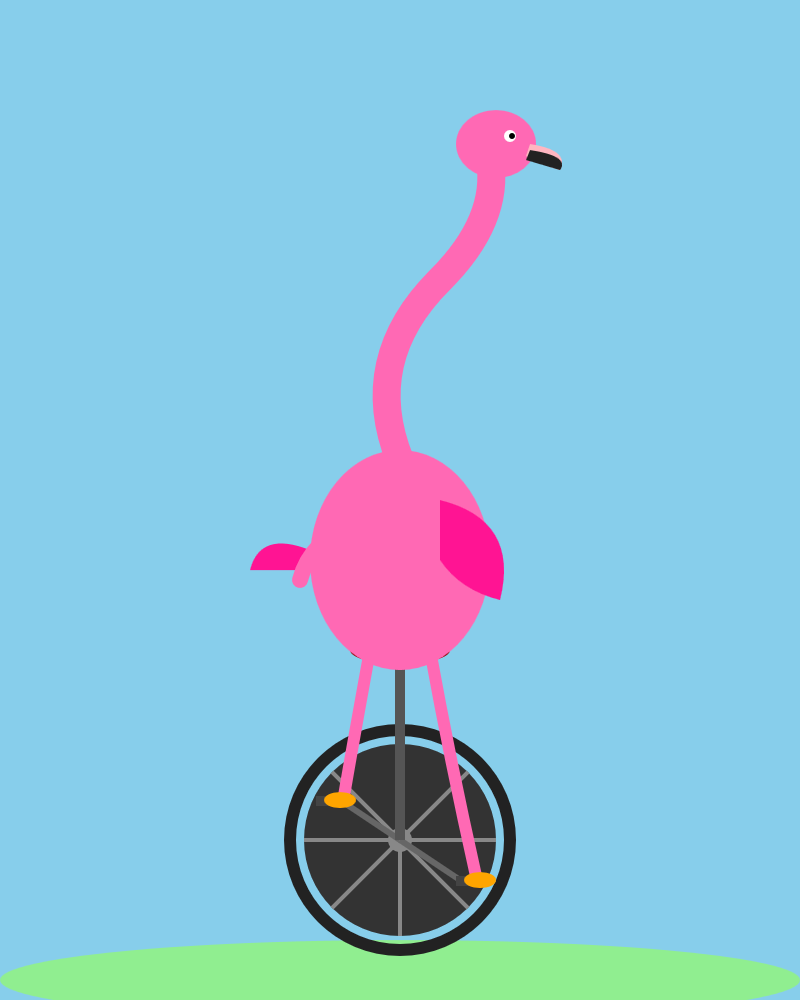
今回の話を一言でいうと、
“ペリカンが自転車に乗るだけのテストで、ローカルQwenがClaude Opus 4.7に勝った”
という、かなり変なニュースです。
でも変だからこそ面白い。
そして、ただのネタに見えて、実は
が、けっこうきれいに浮かび上がっています。
私はこの手の「くだらないけど本質が見える」ベンチマーク、かなり好きです。
真面目な指標だけでは見えない、モデルの“地力”や“癖”がにじむからです。
そして今回は、少なくともペリカン界では、Qwenのほうが一枚上だった――そういう話でした。
参考: Qwen3.6-35B-A3B on my laptop drew me a better pelican than Claude Opus 4.7
