言語モデルには大きく分けて、AR(Autoregressive) と DLM(Diffusion Language Model) の流れがあります。
ここで著者たちが言っている本質的な問題は、introspective consistency(内省的一貫性)が足りないことです。
ざっくり言うと、
この差が、品質ギャップの根っこだという主張です。
これはかなり納得感があります。生成モデルって、ただ“それっぽい文字列”を出すだけでは足りなくて、出したものをちゃんと自分で辻褄合わせできるかがめちゃくちゃ重要なんですよね。
I-DLMの中心アイデアは、Introspective Strided Decoding(ISD) です。
名前だけだと強そうですが、やっていることは意外と素直です。
つまりI-DLMは、
“作る” と “確認する” を別々にやらず、同じ流れの中で両方こなす
のが肝です。
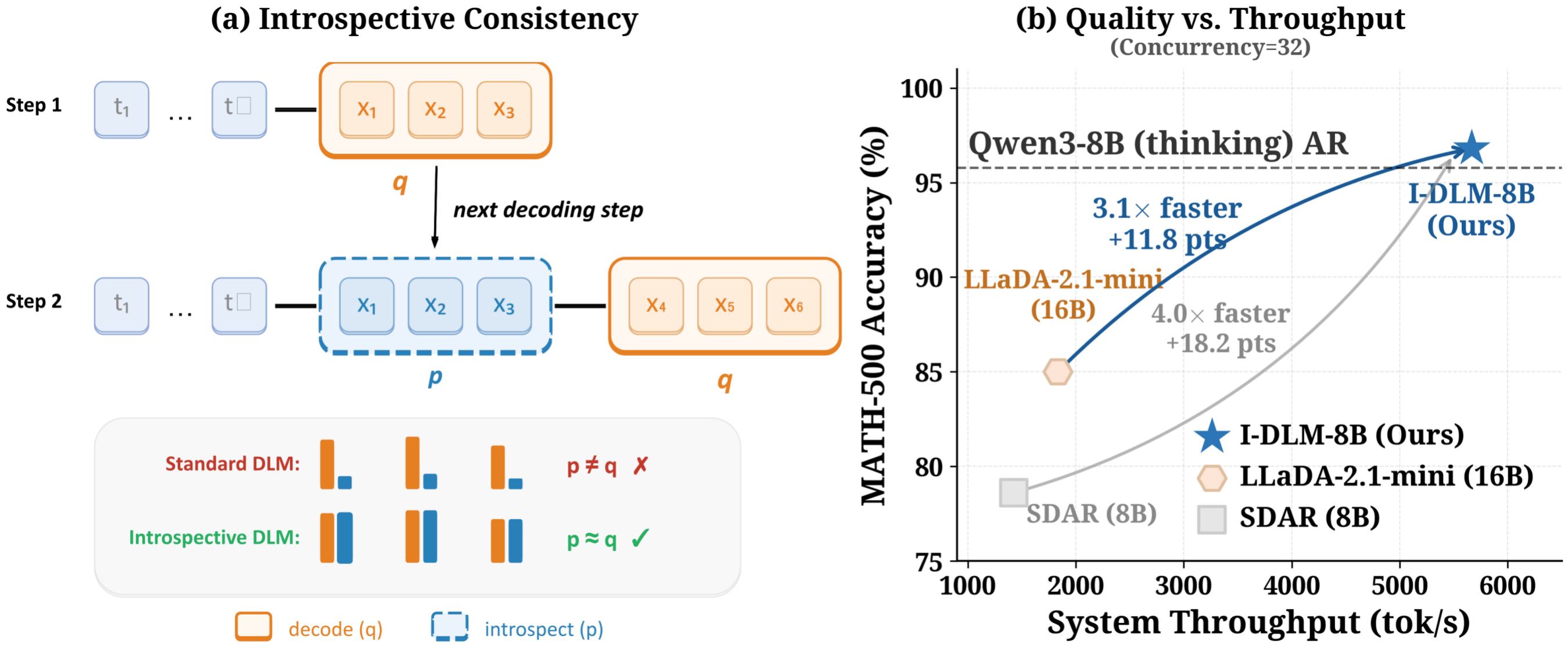
この発想、かなり好きです。
速くしたいから雑に並列化するのではなく、並列化しつつ品質を落とさないために、モデル自身の整合性を高める。単純な力技よりずっと賢いです。
元記事では、既存のpretrained ARモデルをベースにして、I-DLMへ変換するような学習を提案しています。
ざっくり言うと:
さらに、訓練データとして 4.5B tokens、8 H100 GPUs、2 epochs で学習したと書かれています。
このあたり、かなり本気です。研究のアイデアだけではなく、実運用できる形に落としているのが好印象ですね。
元記事の主張の目玉はここです。
I-DLM-8B is the first DLM to match the quality of its same-scale AR counterpart
つまり、同規模のARモデルと同じレベルの品質に到達した最初のDLMだということです。
ベンチマークを見ると、I-DLM 8B / 32B は、知識、数学、コード、instruction following の各領域でかなり強い数字を出しています。
たとえば:
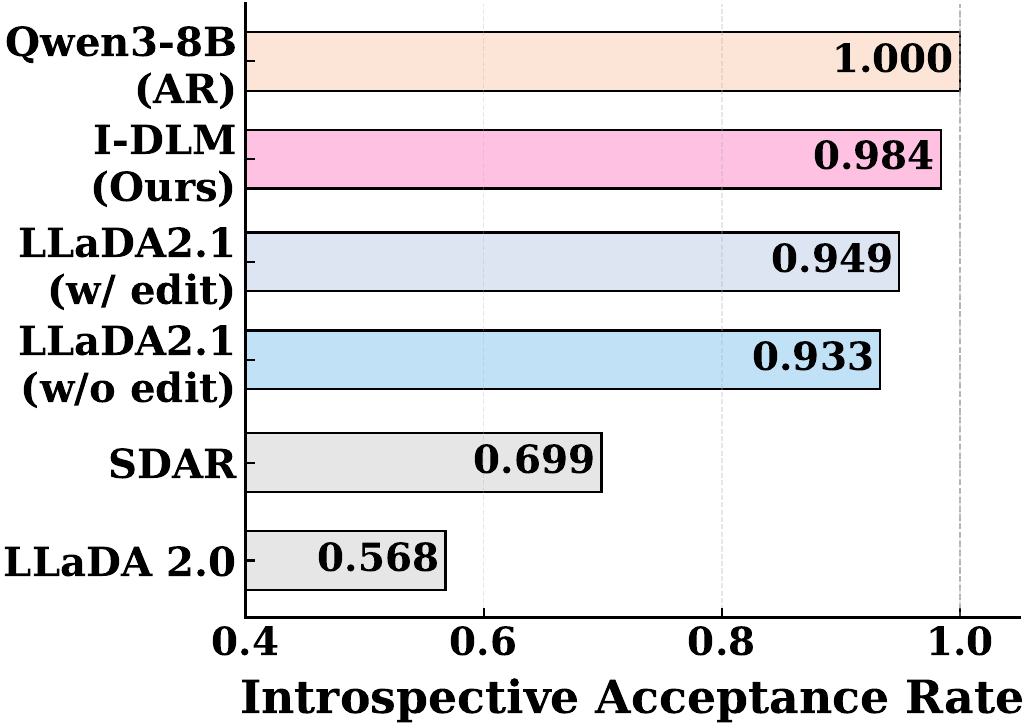
などで、従来DLMを大きく上回っています。
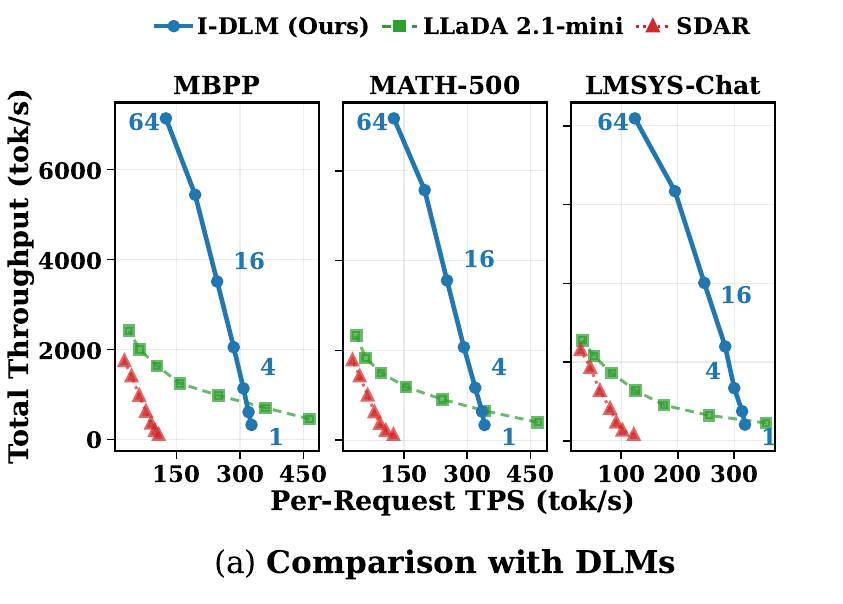
特に目を引くのは、元記事の冒頭で強調されている比較です。
これ、かなり派手です。
単純に「速いDLM」を作っただけではなく、小さめのモデルで強い結果を出しているのが地味に重要だと思います。実運用では、パラメータ効率はかなり大事ですから。
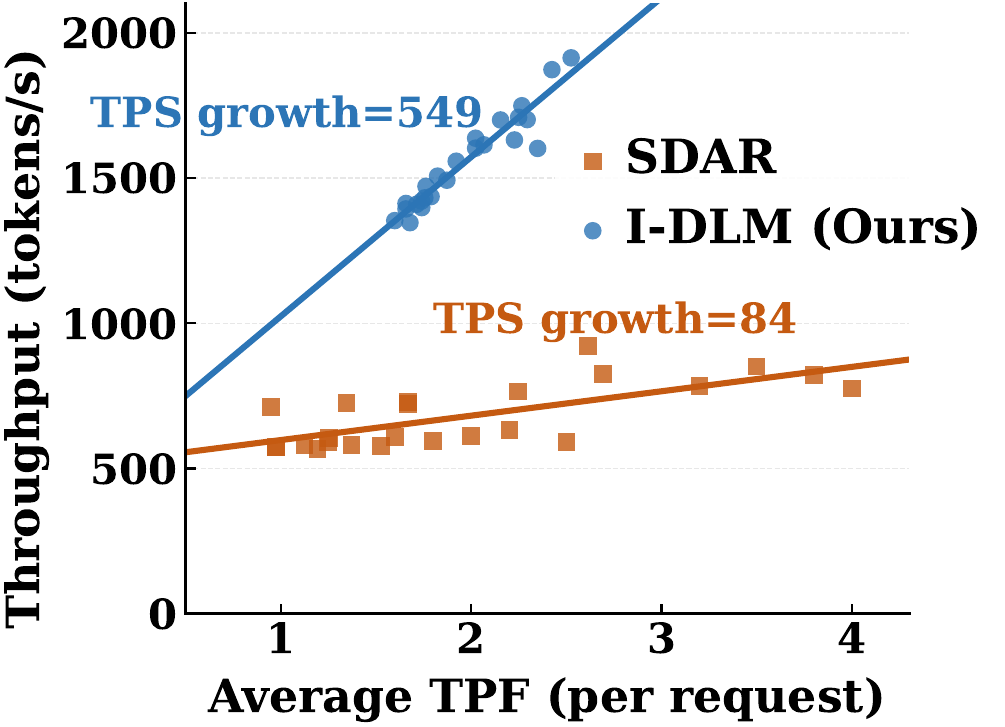
DLMの最大の売りは、ARの弱点である逐次生成のボトルネックを避けられることです。
I-DLMはそこをちゃんと活かしていて、元記事では 2.9〜4.1x throughput を主張しています。
ここでいうthroughputは、ざっくり言うと
「一定時間あたりにどれだけトークンを処理できるか」
です。
I-DLMは1回のforward passで複数トークンを進められるので、ARよりも1回あたりの仕事量が多いです。
しかも、元記事の説明では高並列時でも効率が落ちにくい。
このへんが面白いのは、単に「1回でたくさん出す」だけだと、ふつうは間違いが増えて結局遅いになりがちなのに、I-DLMは検証付きなのでそこを抑えている点です。
元記事では、DLMを評価するときに TPF² / query_size みたいな指標も出しています。
要するに、
をまとめて見ているわけです。
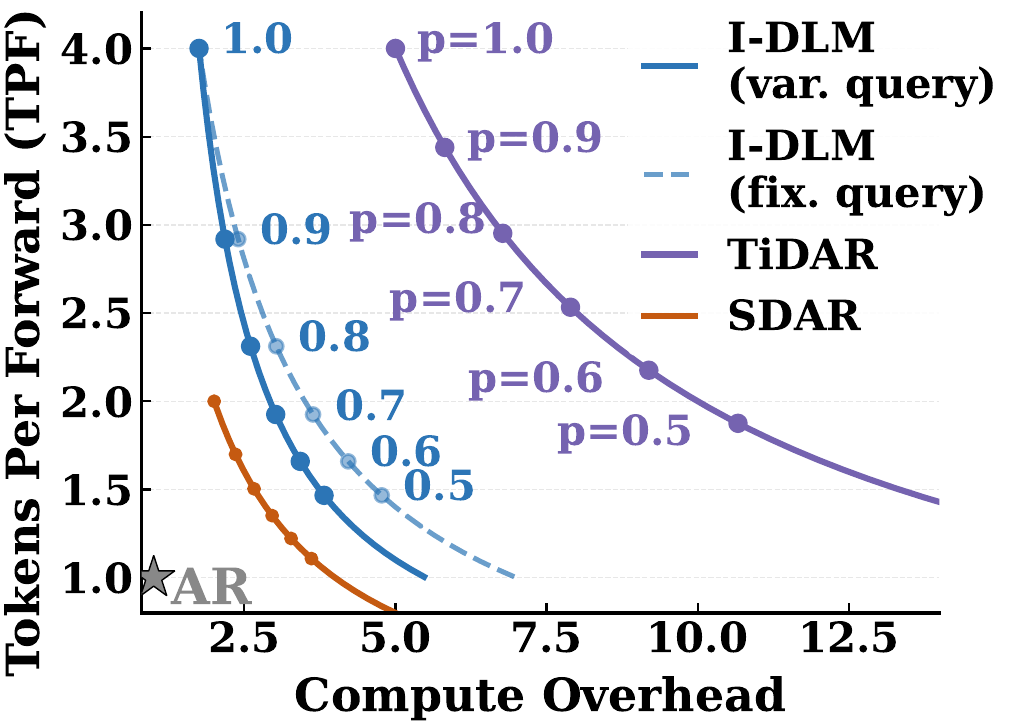
元記事の例では、
と示されています。
この数字の意味は、ざっくり言うと
I-DLMは「並列化したのに、無駄な計算ばかり増えていない」
ということです。
ここは私としてもかなり重要だと思います。
高速化の議論って、見た目の速度だけだとだまされやすいんですが、計算効率まで見てちゃんと勝っているかは別問題です。I-DLMはそこを意識しているのが良いですね。
元記事では、I-DLMは AR-compatible serving をうたっています。
つまり、既存のAR向けサービング基盤に比較的そのまま載せやすいということです。
これは実務だとかなり大きいです。
どれだけ速くても、専用インフラが必要で導入が面倒だと、現場では「で、誰が面倒見るの?」となりがちです。
I-DLMはこの点で、SGLangに直接統合可能としています。
さらに、以下のような最適化も列挙されています。
正直、ここはややエンジニア向けですが、要するに
「モデルだけじゃなく、実際の推論システム全体で速くなるように詰めている」
という話です。
この地道さはすごく大事です。研究はアルゴリズムだけで終わらせず、現場で動く形にするところまで踏み込むと一気に価値が上がります。
元記事で特に興味深いのが、Residual ISD(R-ISD) と gated LoRA を使った bit-for-bit identical な高速化です。
ここで言いたいことは、
ということです。
これはかなり面白いです。
“速いけど少し違う” ではなく、**“速いのに同じ”** を目指すのは、実務上すごく価値があります。
監査や再現性が必要な場面では特に強いはずです。
ここは冷静に見たほうがいいです。
元記事の結果はかなり強いですが、もちろん万能とまでは言えません。
考えるべき点としては:
ただ、I-DLMはそのあたりをかなり正面から扱っていて、
「研究だけの面白さ」で終わっていないのが好感触です。
個人的には、これはDLMの“次の一手”としてかなり有力ではないかと思います。
「並列化したい。でも品質は落としたくない」という、当たり前だけど難しい要求に対して、ちゃんと設計が入っているからです。
I-DLMは、Diffusion Language Modelが抱えていた
「速くできそうなのに品質で負ける」
という弱点に対して、内省的一貫性という観点から切り込んだ研究です。
ポイントを一言でまとめるなら、
“生成しながら自己検証するDLM” によって、ARに迫る品質と高いthroughputを両立した
ということになります。
特に印象的なのは、
という、研究としても実装としても筋の良さです。
DLMはずっと「理屈は魅力的だけど、ARに勝ち切れない」立場にいましたが、I-DLMはその壁をかなり押し返した感じがあります。
まだ今後の検証は必要ですが、少なくとも**“DLMは遅い・弱い” で終わる時代ではない**、という空気を強く感じる発表でした。
