この記事のテーマは、Prompt Compression to Reduce Agentic Loop Costs です。
日本語にすると、「AIエージェントのループ処理でかかるコストを、プロンプト圧縮で減らそう」という話。
ここでいう agentic loop は、AIが
という流れを何度も繰り返す仕組みのことです。
LangGraph や AutoGPT みたいなフレームワークがまさにこのタイプですね。
便利なんですが、ここに落とし穴があります。
AIは次の判断をするために、過去に何をしたか を毎回ある程度持ち越します。すると、ループが長くなるほど、プロンプトに入れる情報がどんどん増えていく。
つまり、毎回「前回までの会話ログ」を引きずるわけです。
これ、人間でいえば「会議のたびに議事録全部を毎回読み直す」みたいなもの。そりゃ重いし、遅いし、金もかかるよね、という話です。
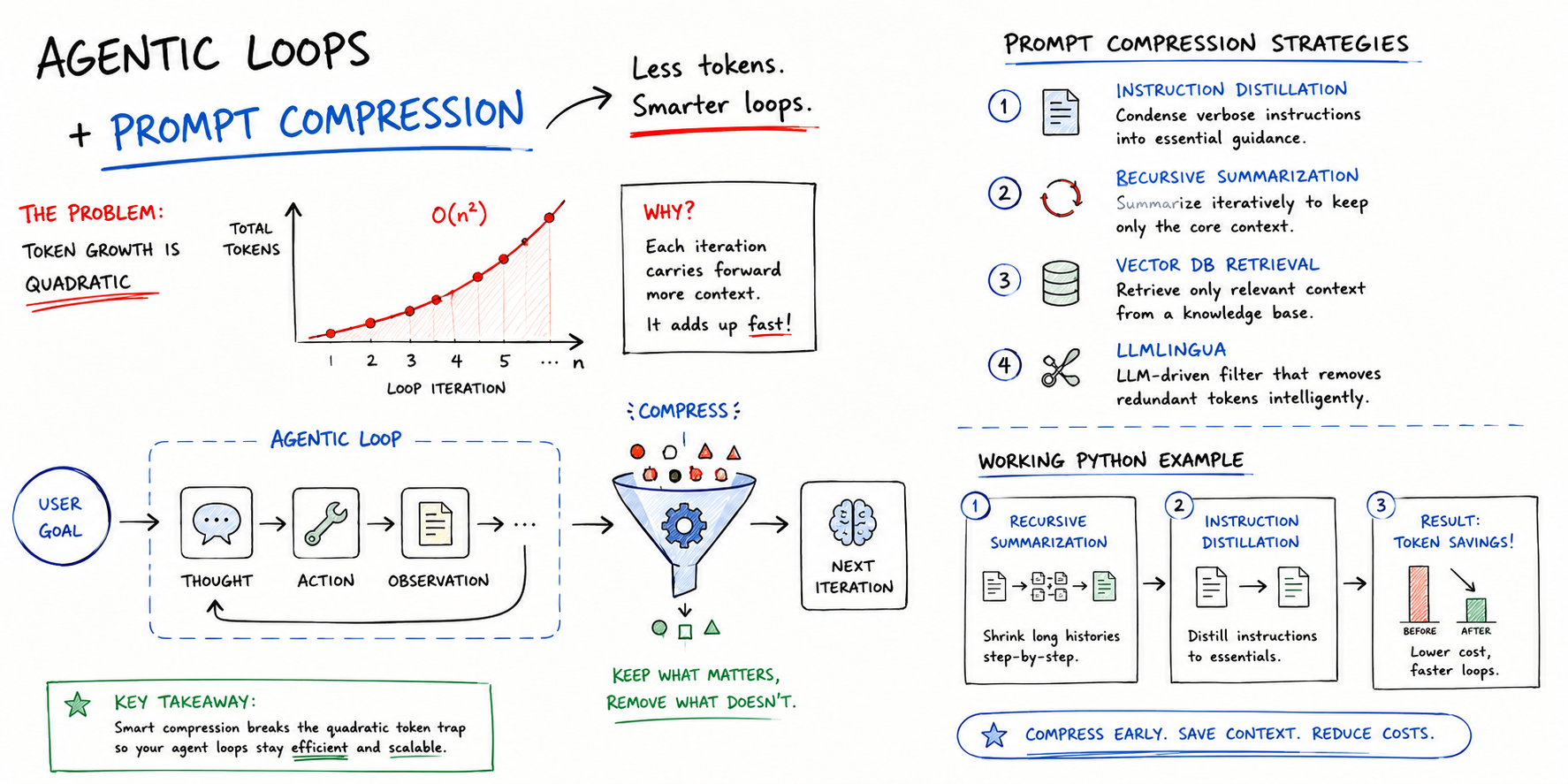
記事では、こんなイメージで説明されています。
見た目には「少しずつ増えているだけ」に見えます。
でも、各ステップで送る総量の累積 を考えると、話は別です。
毎回、似たような情報を繰り返し送るので、合計コストは quadratic(2乗的)に増えやすい。
ここがかなり大事なポイントで、地味だけど効きます。私はこの手の問題、最初は「まあ少し増えるだけでしょ」と見くびりがちなんですが、長いループになると本当に効いてくるんですよね。
しかもコストはお金だけじゃありません。
latency(応答の遅さ) も悪化します。長いプロンプトは処理に時間がかかるので、ユーザー体験まで落ちる。
「30秒待たされるAI」って、便利さをかなり削ります。これはかなり現実的な問題です。
![]()
prompt compression は、ざっくり言うと
「AIに送る情報を、必要な意味を保ったまま短くすること」
です。
記事では、たとえば 500K token の巨大な文脈を 32K token の圧縮ウィンドウに落とす、みたいなイメージが示されています。
もちろんこれは理想論も含んだ例ですが、要は
を削って、本当に必要な情報だけを残す わけです。
この発想、めちゃくちゃ実務的です。
AIを賢くするというより、AIに渡す荷物を軽くする。派手さはないけど、現場ではこういう地道な工夫が効くんですよね。
これは、長い system prompt(AIの基本ルール)を、短い記号的な表現に圧縮する方法です。

たとえば、普通ならこう書くところを:
You are a helpful research assistant. Your goal is to find information about X. Please provide your output in a valid JSON format and do not include any conversational filler.
これを短くして:
Act: ResearchBot. Task: Find X. Output: JSON. No fluff.
みたいにする。
ここで重要なのは、人間が読むための自然文を、モデルが理解できる短い shorthand に置き換えることです。
モデルが「この短い指示でも同じ意味だ」と分かるように設計するわけですね。
正直、これはかなり面白いです。
人間には少し雑に見えるのに、AIにはむしろ効率的。まるで“社内用の暗号メモ”みたいで、ちょっと好きな発想です。

これは、一定ステップごとに、それまでの履歴を要約する方法です。
たとえば、小さめで安価なモデル(記事では gpt-4o-mini や Llama 3 のようなモデル例が出ています)に、過去のやり取りをまとめさせる。
すると、長い履歴をそのまま持ち続けなくても、「今どこまで進んでいるか」だけを短く保持できます。
ポイントは、要約を一度きりではなく、ループの途中で何度も更新していくこと。
だから recursive(再帰的)要約です。
これ、実際かなり実用的だと思います。
会話履歴や調査ログが長くなるAIでは、「全部覚えておく」より「要点だけ覚える」ほうが、むしろ安定することが多いです。
これは、過去の履歴を全部送る代わりに、ベクトルデータベースに保存しておき、必要なものだけ検索して取り出す方法です。
ベクトルデータベースは、文章の意味を数値化して保存・検索できる仕組みです。
代表例として、記事では FAISS や Chroma のようなローカルで使えるものが挙げられています。

要するに、
という設計です。
これはRAG(Retrieval-Augmented Generation)と相性がいいです。
「過去を全部持ち運ぶ」のではなく、「必要な記憶だけ呼び出す」。人間っぽくていいですよね。
LLMLingua は、プロンプトの中から重要でないトークンを削ることに特化した open-source のフレームワークです。
トークンというのは、AIが文章を細かく分割して数える単位のこと。
人間の「単語」と完全一致するわけではないですが、ざっくり「AIの文字数みたいなもの」と思ってよいです。
LLMLingua の発想はかなりストレートで、
「この単語、なくても意味通じるよね?」
を機械的に削っていく感じです。

こういう発想は地味ですが、実装次第ではかなり効くはずです。
特に高価なモデルに投げる前の前処理として、筋がいいと思います。
記事では、Python の簡単な例が紹介されています。
内容は、履歴をためていき、最後に要約して圧縮した場合の token 数を比較するというものです。
ざっくりした流れはこうです。
tiktoken で token 数を数える出力例では、次のようになっています。
かなり削れています。
もちろんこれは簡略化されたサンプルですが、「積み上がったログをそのまま持つより、まとめて圧縮した方がかなり軽い」 ことが直感的に分かります。

こういう数字を見ると、理屈が一気に現実味を帯びますね。
「概念としては分かる」から「実際に減るんだ」に変わる瞬間です。
この記事を読んで強く思ったのは、prompt compression は単なる小技ではなく、AIエージェントを運用するための必須テクニックになりつつあるということです。
AIを使ったシステムは、つい「もっと長い文脈を持てば解決する」と考えがちです。
でも実際には、文脈を増やせば増やすほど、
という問題が出ます。
なので、重要なのは「全部覚えさせること」ではなく、
何を残し、何を捨てるかを設計すること だと思います。
これはAIに限らず、情報設計全般に通じる話ですよね。
必要なものだけ残す。言うのは簡単ですが、実装するのは難しい。でも、だからこそ価値がある。
個人的には、このテーマはかなり実務寄りで好きです。
派手な新モデル紹介ではなく、「実際に動かしたときの請求額と遅延をどうするか」 に踏み込んでいるからです。
特に agentic loop の文脈では、AIは賢ければ勝ちではありません。
安く、速く、壊れにくく動くこと が大事です。
その意味で prompt compression は、かなり地味だけど本質的な改善だと思います。
一方で、圧縮しすぎると必要な情報まで削ってしまうリスクもあります。
なので、ここは魔法ではなくて、「どこまで削っても大丈夫か」を見極める設計問題 なんですよね。
たぶん本番では、要約の品質評価や、検索の精度、タスク成功率とのバランス取りが重要になるはずです。
参考: Implementing Prompt Compression to Reduce Agentic Loop Costs - MachineLearningMastery.com
