
テクノエッジの「生成AIウィークリー」第141回は、かなり“実戦寄り”の内容でした。
派手なデモで驚かせるだけではなく、コーディング、3D生成、画像生成、ローカル動作、商用利用といった、実際に人が使う場面を意識した技術が並んでいます。
![]()
個人的には、ここがいちばん重要だと思います。
生成AIの話題は最初こそ「すごい絵が出た」「賢い会話ができた」で盛り上がりましたが、今はもう一段階進んでいて、どのモデルが仕事に入れられるか、どのGPUで動くか、ライセンスはどうかまで見られる時代になっています。
つまり、AIは“見せ物”から“道具”に変わりつつある、ということです。
![]()

![]()
最初の注目株は、中国のAI企業 MiniMax が公開した MiniMax M2.7 のオープンウェイト版です。
オープンウェイトというのは、ざっくり言うとモデルの重み(学習済みの中身)を公開してくれること。研究や実験に使いやすく、ローカル環境や独自サービスに組み込みやすいのが魅力です。
M2.7は、総パラメータ2290億のMoEモデルです。
MoE(Mixture of Experts)は、たくさんの“専門家”を持っていて、質問に応じてその一部だけを使う方式。全部を常時フル稼働させるわけではないので、巨大モデルでも比較的効率よく動かせるのが特徴です。
![]()
しかも、推論時に実際に動くのは100億パラメータ程度。
「そんなに大きいのに、全部を毎回使ってるわけじゃないのか」と驚く人もいるはずですが、これがMoEのうまさです。
![]()
記事では、M2.7が以下のようなベンチマークで高スコアを出したと紹介されています。
![]()
![]()
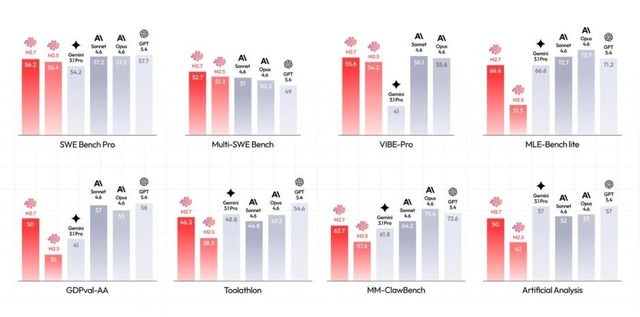
特に印象的なのは、SWE-ProでGPT-5.3-Codexと同等、Claude Opus 4.6に肉薄している点です。
これはつまり、単なる“コードを少し書けるAI”ではなく、開発タスクでかなり本気で戦えるレベルに来ている、ということ。

私の感想としては、ここまで来ると「AIにコードを書かせる」のではなく、AIをどうレビューし、どう責任分担するかの方が重要になってきたと感じます。
もはや「どのAIが賢いか」だけでなく、「どのAIを、どの場面で、どう使うか」が問われる段階です。
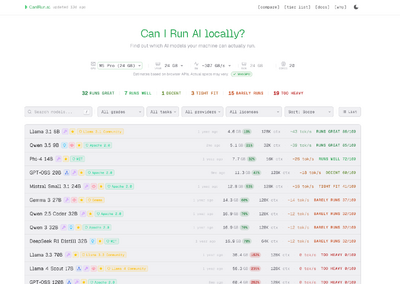
ここは大事です。
M2.7はオープンウェイトですが、ライセンスは非商用利用で、商用利用には事前許諾が必要です。
この点はかなり重要。
技術的に強くても、ビジネスで使えるかは別問題です。
「オープンだから自由に使える」と勘違いすると危ないので、ここはしっかり確認したいところです。

次は Tencent Hunyuan が公開した HY-World 2.0。
これはかなりSFっぽくて、個人的にはかなりワクワクしました。
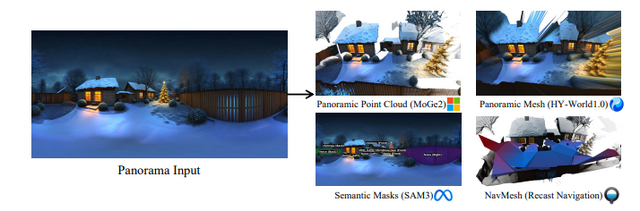
テキストや1枚の画像から、歩き回れる3D世界を生成できる“world model”です。
world model というのは、世界の見た目だけでなく、空間のつながりや奥行き、見え方の変化まで扱うモデルのこと。ゲーム制作やVR、シミュレーションに相性がいいです。

HY-World 2.0は4段階で3D世界を作ります。

3D Gaussian Splatting は、点の集まりで3D空間を表現する方法のひとつです。
CGの専門知識がなくても、「3D空間をかなり効率よく再現する技術」くらいの理解で十分です。
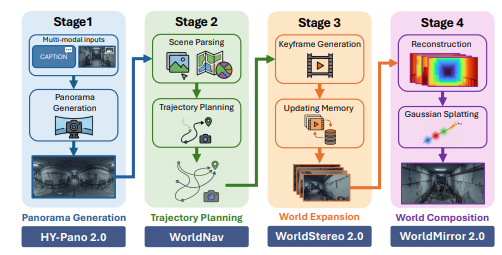
記事では、生成と再構築を1つのシステムに統合したこと、そしてキーフレーム単位の生成と記憶機構で視点が大きく動いても破綻しにくくなったことが強調されています。
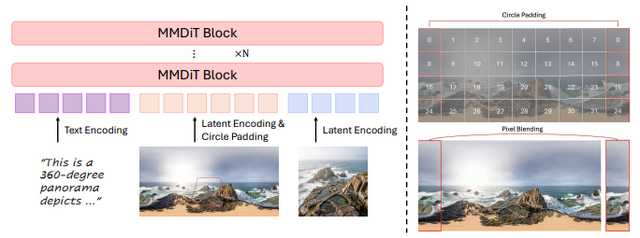
ここは地味にすごいです。
AIの画像生成って、単発ではきれいでも、視点を変えると急に破綻することが多いんですよね。
でも世界を扱うなら、そこがダメだと意味がない。
つまり HY-World 2.0 は、**“絵”ではなく“空間”を作る方向にかなり踏み込んでいる**わけです。
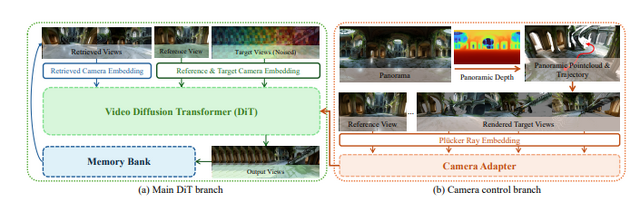
しかも、NVIDIA H20 GPU 1台でおよそ10分という速度で、既存のオープンソース手法を上回り、商用モデルの Marble と互角レベルとのこと。
このへんは、研究としてもかなり見どころがあります。


続いては Alibaba の Qwen チームによる Qwen3.6-35B-A3B。
これもオープンウェイトモデルです。
このモデルは、総パラメータ350億、アクティブパラメータ30億の MoE モデル。
数字だけ見ると巨大ですが、実際に働くのは一部なので、効率が良いのがポイントです。

注目点は、エージェント的なコーディング性能が高いこと。
エージェント的というのは、単に1回答えるだけでなく、ツールを使ったり、試行錯誤しながらタスクを進めるような性格を指します。
要するに、ただの“おしゃべりAI”ではなく、作業を進めるAIに近いです。

記事では以下のようなスコアが紹介されています。
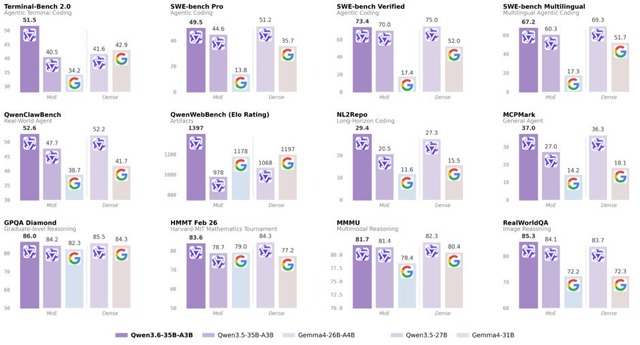

前世代の Qwen3.5-35B-A3B を上回り、さらに Qwen3.5-27B や Gemma4-31B にも匹敵するとのこと。
このあたりを見ると、AI開発の主戦場が「でかいモデルをただ積む」だけではなく、効率良く賢く動かす設計へ移っているのがわかります。
しかも視覚言語タスクでも、Claude Sonnet 4.5 と同等かそれ以上の場面があるとされています。
マルチモーダルは、テキストだけでなく画像や音なども扱う能力のこと。
つまりこのモデル、コードも強いし、見る力もあるわけです。
こういうモデルは、今後かなり実務向けに使われる可能性があると思います。
「万能」という言葉はあまり好きではないのですが、少なくとも実務で触る価値のあるレベルに来ているのは間違いなさそうです。

今回もっとも“使う人が喜びそう”なのが、Baidu の ERNIE-Image かもしれません。

画像生成AIはたくさんありますが、文字、特に日本語が弱いのが長年の悩みでした。
看板、ポスター、漫画のセリフ、商品説明……こういう用途では、絵が上手いだけでは足りません。
文字が崩れると一気に使い物にならないんですよね。

ERNIE-Image はここがかなり強い。
記事によれば、中国語・英語を含む長文テキスト描画に強く、日本語もほぼ文字化けせずに出力できるとのこと。
これはかなり大きいです。
正直、画像生成AIで日本語がちゃんと出るだけで、実用度は一段上がります。

ERNIE-Image は 8Bパラメータの DiT(Diffusion Transformer)モデル。
DiT は、拡散モデルを Transformer ベースで扱う方式です。
細かい仕組みは置いておいて、ざっくり言えば画像を作るのが得意な現代的な設計です。
そして嬉しいのが、24GB VRAMの民生GPUで動作する点。
つまり、ハイエンドすぎる業務用機材がなくても、条件が合えば自宅PCで触れます。
これはローカルAI好きにはかなり刺さるはずです。

さらに記事では、商用利用可能とされています。
ここは本当に重要。
どれだけ性能が良くても、仕事で使うならライセンスがネックになりますからね。
しかも通常版だけでなく、ERNIE-Image-Turbo の高速版や、短文を詳細プロンプトに広げる 3B Prompt Enhancer も用意されているとのこと。
この「短い指示を、AIがいい感じに膨らませてくれる」仕組みは、地味だけど便利です。
プロンプトを毎回長々と書くのは面倒ですから、こういう補助機能があるとかなり助かります。

記事では、ERNIE-Image は
![]()

と紹介されています。
オープンウェイトモデルに限れば、どの指標でも首位とのこと。

要するに、見た目がきれいなだけではなく、指示に忠実で、文字も強い。
画像生成AIは“絵のうまさ”だけで語られがちですが、実際の用途ではこの制御性がものすごく大事です。
個人的には、かなり実務向けの良モデルだと思います。


今回紹介された4つの技術を並べると、共通点が見えてきます。


つまり、AIはもう「何でもできそうな夢の塊」というより、用途別にかなり具体的な強みを持つ道具になってきています。
これが今の面白さだと思います。

昔は「AIが賢いってどういうこと?」という話が中心でしたが、今はもっと現実的で、
が勝負になっています。
私はこの変化をかなり前向きに見ています。
なぜなら、技術が“すごい”だけではなく、ちゃんと役に立つ方向に進んでいるからです。



今回の「生成AIウィークリー」は、派手さと実用性のバランスがとても良かったです。
特に印象に残ったのは、日本語文字に強いERNIE-Image と、コーディング性能が非常に高いMiniMax M2.7。
この2つは、趣味と仕事の両方でかなり使い道がありそうです。
![]()
そして HY-World 2.0 のような世界モデルは、今後ゲームやXR、シミュレーション制作に大きな影響を与えるかもしれません。
Qwen3.6-35B-A3B も含めて、生成AIはますます「デモがすごい」から「現場で使える」に寄ってきている。
その流れは、かなり面白いと思います。
![]()
