深層学習は、実用上はめちゃくちゃ強いのに、理論はまだ追いついていない——この話、AI界隈ではおなじみです。
今回の元記事は、その「追いついていない」をかなり真正面から殴りにいく論文風の文章です。
しかも単に「説明します」ではなく、**“We finally know why deep learning works.”** とかなり強気。こういう断言、普通なら身構えるところですが、内容を見るとちゃんと理論の筋道を通そうとしていて、読み物としても研究ノートとしてもかなり刺激的です。
ただし、最初に正直に言っておくと、これは深層学習の最終回答というより、ひとつの統一的な見方を与える理論です。
つまり、「これで全部解決!」と断言するよりは、「複数のバラバラな現象を、同じレンズで眺められるようにした」という捉え方のほうが自然だと思います。
従来の statistical learning theory では、よく bias-variance tradeoff が語られます。
ざっくり言うと、
という考え方です。
でも深層学習は、この直感をかなり平気で裏切ります。
深いニューラルネットは、パラメータ数がデータ数を大きく超えることが珍しくありません。
それでも学習すると、訓練データをほぼ完全に当てながら、test error も低いことがある。
これはかなり不思議です。
普通なら「全部覚えたら終わりでは?」と思いますよね。私も最初にこの話を聞いたときは、かなり気持ち悪いなと思いました。
記事では benign overfitting も取り上げています。
これは「訓練データは完全に当てているのに、なぜかテスト性能が壊れない」という現象です。
“overfitting” という言葉からは悪い印象を受けますが、ここでは harmful ではない overfitting が起きている、というのがポイントです。
さらに、モデルを大きくすると test error が最初は上がり、その後また下がる double descent も有名です。
昔ながらの U字カーブではなく、山が2回あるような挙動ですね。

gradient descent は、訓練データを当てる解が無数にあるとき、なぜか「より良い解」を選ぶように見える。
これが implicit bias です。
明示的に正則化(regularization)していなくても、最適化の手順そのものに偏りがある、という話です。
最後に grokking。
これは最初は訓練データを丸暗記しているだけなのに、かなり後になって突然 generalization し始める現象です。
「え、今さら?」という感じで急に賢くなるので、見ていてかなり不思議です。
この記事の核はここです。
普通、ニューラルネットを理解しようとすると、各層の重みやパラメータをいじりながら「この巨大な空間でどう動くか」を考えます。
でも著者は、それをやめて出力の空間(output space)だけを追いかけよう、と提案しています。
これはかなり大事な転換だと思います。
なぜなら、実際に私たちが欲しいのは「内部の重みそのもの」ではなく、入力に対してどんな予測を返すかだからです。
ここで出てくるのが empirical Neural Tangent Kernel(eNTK) です。
難しく聞こえますが、ざっくりいうと:
を表す行列です。
記事では、訓練データの出力をまとめたベクトル (U_S) と、その微分(Jacobian) (J_S) から
[
K_{SS}(w) = J_S(w) J_S(w)^\top
]

という形で定義しています。
この (K_{SS}) が、「訓練点どうしがどれだけ影響し合うか」を決める中心人物です。
かなり乱暴に言えば、**ネットワークがどの方向に学習しやすいかを決める“相関の地図”**みたいなものです。
著者の理論では、gradient descent の学習は output space で次のように動くと見ます。
つまり、学習とは「重みを直接いじること」よりも、出力同士の関係が再配線されていく過程として見えるわけです。
ここで重要なのは、すべての方向が同じ速さで学習されるわけではないことです。
eigenvalue が大きい方向は速く学習され、小さい方向は遅い。
その結果、ある方向の情報はすぐ取り込まれ、別の方向はずっと残ることになります。
この「どの方向がどれだけ学ばれるか」が、後で出てくる signal / reservoir の考え方につながります。
著者は、学習された情報を大きく2つに分けます。
テスト時にも効く、一般化に寄与する情報。
loss をしっかり減らす方向で、訓練とテストの両方に使える部分です。
訓練データでは覚えたけれど、テストには見えにくい情報。
ノイズや細かすぎる例外がここに押し込まれる、というイメージです。
この比喩、かなりうまいと思います。
「訓練では覚えたのにテストでは役に立たない」というモヤモヤを、貯水池に溜まった水のように扱っているからです。
一度 reservoir に入ったものは、テストの出力には現れにくい、というのが著者の主張です。
この記事の強いところは、いろいろな現象をまとめて説明しようとしている点です。
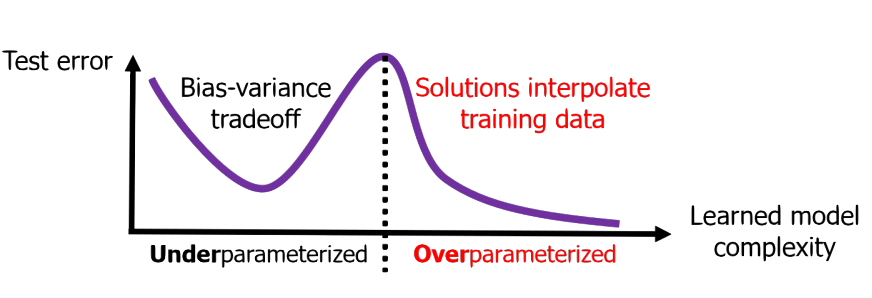
訓練ノイズはある。なのにテストでは問題ない。
著者の理屈では、そのノイズは reservoir に押し込まれていて、テストには現れない。
だから「訓練データを丸暗記しても、test error は壊れない」ことが説明できる、というわけです。
モデルが小さいと signal も reservoir も十分に扱えない。
容量が増えて interpolation に近づくと、ノイズが一時的に signal channel に入り込み、test error が跳ねる。
でもさらに大きくなると、また reservoir に吸収されて下がる。
この山と谷の繰り返しが double descent だ、という見立てです。
gradient descent は、全部の解を等しく扱うのではなく、kernel の大きい方向から先に学ぶ。
つまり、学習の順番そのものに偏りがあり、それが結果として「低ノルムの解」「より素直な解」を選びやすくしている。
この説明はかなり納得感があります。
「最適化アルゴリズムが暗黙の正則化を持つ」という見方は、深層学習を理解するうえで本当に重要だと思います。
最初は reservoir に閉じ込められていた signal が、学習が進むにつれて signal channel に移ってくる。
すると突然 generalization が始まる。
「急にわかった」ように見える現象を、kernel の変化として説明しているわけです。
これは面白いです。
grokking は感覚的には「遅いひらめき」ですが、この理論では情報の通り道が後から開通するように見える。かなり絵として強いですよね。
記事の後半では、さらに踏み込んで、population risk を直接扱えるような訓練法まで主張しています。
具体的には、ミニバッチ内の各点を「1点ホールドアウトのテスト」とみなして、ある条件を満たす parameter だけ更新する、というルールが紹介されています。
[
\mu_k^2 > \frac{\sigma_k^2}{b-1}
]
これは要するに、
という発想です。
著者はこれが Adam の一行変更で実現できるような話として述べており、grokking を加速し、memorization を抑え、validation set なしでうまくいくと主張しています。
ここはかなり攻めています。正直、本当にそこまで一般化できるなら相当大きいですが、同時に主張としてはかなり強いので、実験や条件の細部を丁寧に見る必要があると思います。

個人的には、この文章の一番おもしろいところは、単なる数式の列ではなく、「なぜ学習がうまくいくのか」という物語を作ろうとしている点です。
この流れは、かなり美しいです。
しかも Borges の Funes の話から始めるのも粋です。
「全部覚えるのは賢さではなく、むしろ思考の妨げになる」という導入は、深層学習の“覚えすぎ”と不思議なくらい相性がいい。
ただし、こういう統一理論は魅力的なぶん、少しでも条件が崩れると話が怪しくなることもあります。
なので私は、この記事を最終結論というより、強力な視点を与える研究プログラムとして読むのがよさそうだと思います。
この文章の本質は、「深層学習がなぜ一般化するのか」を、単に“偶然うまくいっている”ではなく、学習ダイナミクスの構造として説明しようとしていることです。
特に重要なのは次の2点です。
この2つがわかると、深層学習の「覚えすぎているのに、なぜか強い」という奇妙な現象が、少しだけ整理されます。
完全に腑に落ちるというより、**“なるほど、そういう見方なら筋が通る”**という感覚に近いです。
この元記事は、深層学習の理論を kernel と output dynamics を中心に再構成し、
benign overfitting、double descent、implicit bias、grokking をひとつの枠組みで説明しようとする、かなり意欲的な内容でした。
全部を鵜呑みにする必要はありませんが、
「deep learning はなぜうまくいくのか?」という問いに対して、かなり手触りのある答えを与えてくれるのは確かです。
個人的には、こういう理論は“正しいかどうか”だけでなく、研究者の見方をどう変えるかが重要だと思います。その意味で、かなり面白い記事でした。
