カミナシのエンジニアブログの記事が面白いのは、「AIのための特別なアーキテクチャ」を探した結果、結局は昔から正しいと言われてきた設計原則に戻ってきたところです。
これはかなり重要な話だと思います。
AIがコードを書く時代になると、「AIが書きやすい構成」「AIが迷わない構成」が必要に見えます。けれど、実際には人間にとっても保守しやすい設計が、そのままAIにも効く。ここがこの記事の核心です。
筆者は新規プロダクトの0→1開発をしていて、短期のスピードと長期の保守性の両立を考えたそうです。0→1って、とにかく早く形にしたい。でも雑に作ると後で地獄を見る。ここでAIを活用するなら、なおさら「AIが暴れない設計」が必要になります。
その答えとして出てきたのが、関心の分離・価値の高いテスト・依存方向の決定の3本柱でした。
最初のポイントは、関心の分離です。
簡単に言うと、関連するコードを近くに置くということです。
たとえば「ユーザー登録」「請求処理」「進捗率計算」のように、機能ごとにフォルダを分ける。すると、その機能に関係するロジック、DBアクセス、API、UIなどがひとまとめになります。
記事では、AIが修正するときに関連ファイルがまとまっていると、コンテキストに載せやすいと説明しています。
要するに、AIに「この機能を直して」と渡したとき、あちこち探し回らなくて済む。これはかなり納得感があります。
AIは“見えている情報”の中で仕事をします。ファイルが散らばっていると、そのたびに「どこが本体なのか」を探すコストが増える。人間でも面倒なのに、AIならなおさらです。
だから、機能単位でまとまっている構成は、AIの迷子防止に効くわけです。
記事ではこれを Feature-First と呼んでいます。
機能ごとにディレクトリを切り、その中に
domain/:ビジネスロジックinfrastructure/:DBなど外部I/Oserver/:APIの組み立てcomponents/:UI部品hooks/:カスタムフックindex.ts:外部向けの公開口を置く構成です。
この構成のいいところは、1つの関心事が1つの箱に入ることです。
個人的には、これはかなり実用的だと思います。よくある「レイヤー別(components, services, utils…)」の分け方は、最初はきれいでも、機能単位で追うとコードが横断しまくってつらくなりがちです。Feature-Firstは、その逆で「機能のまとまり」を優先していて、現場向きです。
各featureの index.ts には、外から使っていいものだけを export します。
内部のヘルパー関数やDB操作の詳細は隠す。

これの何がいいかというと、外部コードが内部実装に依存しにくくなることです。
つまり、featureの中をいくら整理し直しても、index.ts の外向けの形が変わらなければ、外のコードはほぼ影響を受けません。
これは地味ですが、保守ではめちゃくちゃ大事です。
内部を自由に触れる余地があると、AIはつい内部の細部に手を突っ込みがちです。公開口を絞っておくと、「触っていい面」が減るので、結果的に安全になります。
Feature-Firstで気になるのは、「じゃあ複数機能にまたがる処理はどうするの?」という点です。
この記事はそこもちゃんと整理しています。
複数featureで使う純粋な計算は、shared/lib/ に置く。
ここでのポイントは、shared は features に依存しないことです。
つまり依存方向は
features/ → shared/の一方通行。
これはかなり気持ちいい設計です。
共通部品って、便利だからこそ汚染しやすいんですよね。「とりあえず shared に置こう」が進むと、いつの間にか shared が何でも屋になって破綻しがちです。
だからこそ、shared は“純粋な共通関数だけ”に絞るのが大事だと思います。
複数featureのデータを組み合わせて1つのページを作る場合は、routes/ 層が受け持ちます。
ここはTanStack Startの構成を前提にしていますが、Next.jsの app/ でも似た考え方ができる、と記事では触れています。
ページ側で各featureのデータ取得関数を並列で呼び出し、集めた結果をUIにする。
つまり、feature同士は互いを知らない。
どのfeatureを組み合わせるかは、ページの責任です。
これは役割分担としてとてもきれいです。
featureは「自分の仕事だけ」に集中し、routesは「ページとしてどう組み立てるか」に集中する。
この分離があると、AIに対しても「featureはfeatureだけ触って」「ページで組み合わせて」と指示しやすい。地味ですが、かなり効きます。
次の大きな柱はテストです。
記事は、単体テストの「数」より「質」が大事だと強く言っています。これは本当にその通りだと思います。
記事では、Vladimir Khorikovの考え方を引きつつ、価値の高い単体テストには次の要素があると紹介しています。
この中で特に大事なのが、リファクタリング耐性です。
要するに、コードの内部を整理し直しても、テストが壊れないこと。
ここ、かなり重要です。
テストが内部構造にべったり張り付いていると、少し整理しただけで大量に落ちる。すると人はテストを信用しなくなります。信用されないテストは、最終的に“うるさいだけの存在”になる。これは悲惨です。
そこで記事が採っているのが、出力値ベーステストです。
これは、関数の内部がどう動いたかではなく、入力に対して何が返ってきたかだけを見るテストです。
たとえば、進捗率を計算する純粋関数があれば、
75 / 100 = 75.0120 / 100 = 120.0目標が0なら0のように、結果だけを確認する。
これならDB初期化もモックもいりません。
テストがシンプルで速い。しかも、内部実装を変えても振る舞いが同じならテストは通る。これはかなり気持ちいいです。
個人的には、テストは「実装を縛るもの」ではなく「振る舞いを守るもの」であるべきだと思っています。
実装を縛りすぎると、保守のたびにテストが敵になる。逆に、振る舞いだけを守るなら、テストは味方のままです。
出力値ベーステストを自然に書くには、テスト対象が純粋関数であるのが理想です。
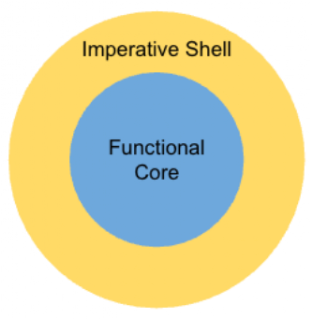
そこで登場するのが Functional Core, Imperative Shell(FCIS) です。
これは簡単にいうと、
という分け方です。
記事では、以下のように役割を切っています。
domain/:Functional Core。純粋関数だけinfrastructure/:Imperative Shell。DBアクセスなどI/Oserver/:API層。domainとinfrastructureを組み立てる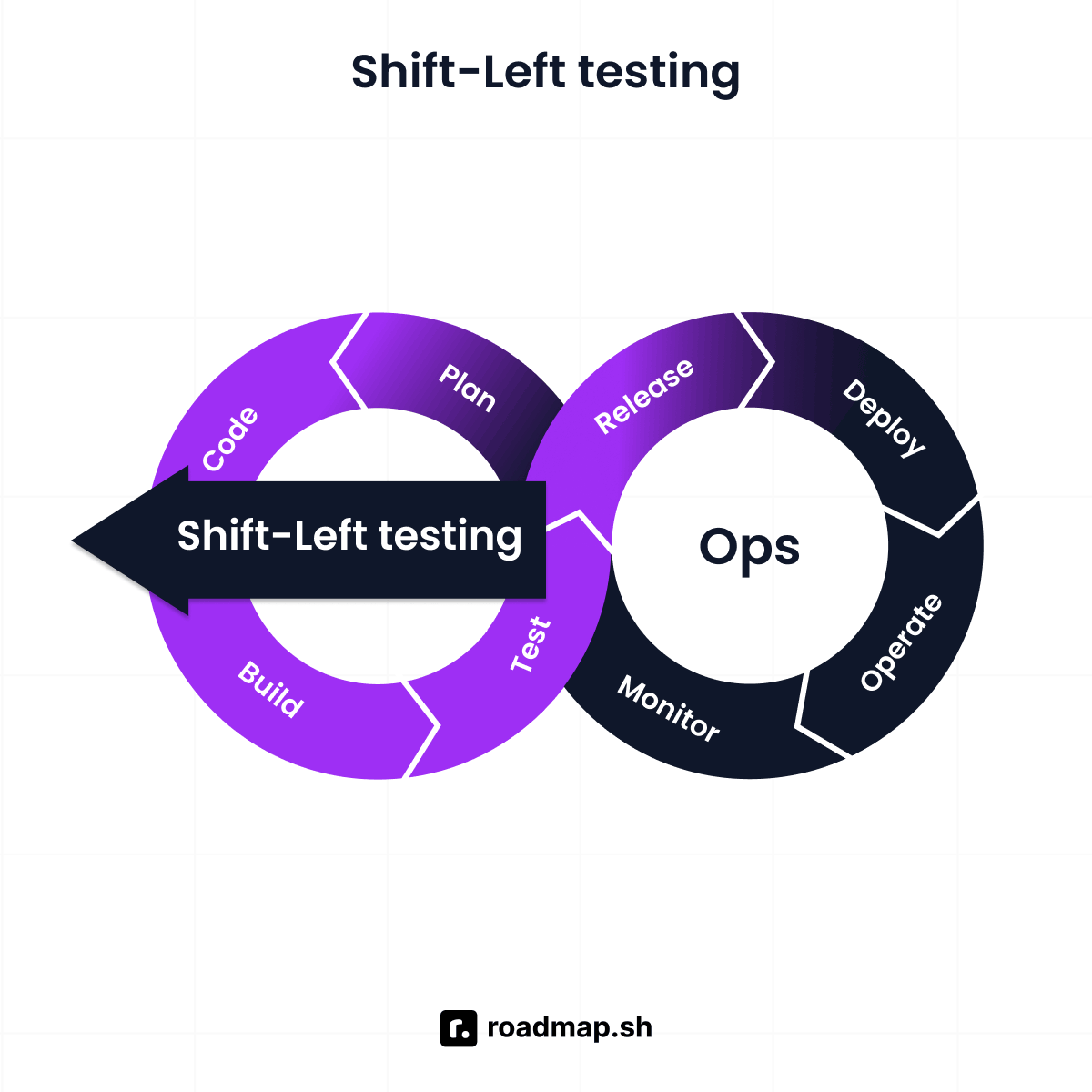
これがなぜいいかというと、ビジネスロジックのテストからI/Oを排除できるからです。
モックやDIコンテナがいらなくなる。テストが軽い。速い。壊れにくい。
これは派手ではないけれど、実際の開発ではかなり効く設計です。
AIは“それっぽいコード”を出すのは得意ですが、I/Oとロジックが混ざったコードを整理しながら正しく保つのは意外と苦手です。だから、あらかじめ純粋関数中心にしておくのは、AI時代にかなり理にかなっています。
ここからがこの記事のもう一つの面白いところです。
設計原則を決めても、AIがそれを守るとは限らない。
CLAUDE.md や AGENT.md にルールを書いても、あくまで確率的で、100%は保証できない。
これはすごく現実的な指摘です。
AIに「こうしてね」とお願いするのは大事ですが、お願いはお願いでしかない。
しかもレビューで後から気づいても、直しコストがかかる。できればもっと早く止めたい。
記事の考え方はシンプルです。
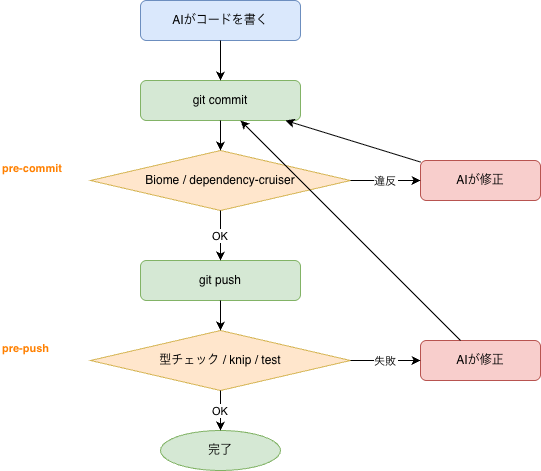
ルールは文章ではなく、静的解析で機械的に強制する。
静的解析とは、ざっくり言うと「コードを実行せずに、事前にルール違反を見つける仕組み」です。
これなら、違反があれば必ずエラーになる。曖昧さがない。ここが大きい。
この記事の中核ツールのひとつが dependency-cruiser です。
これは import の関係を見て、「どこからどこへ依存してよいか」をチェックするツールです。
記事では、設計思想を表すために13個のルールを定義しているそうですが、その中でも重要な4つが紹介されています。
domain/ から infrastructure/ や server/ を import したらエラー。
さらに、ORMのようなI/O系ライブラリにも直接依存しないようにしている。
これは、domainを「ビジネスルールだけの場所」に保つためです。
ここが崩れると、テストのしやすさも、設計の見通しも一気に悪くなります。
あるfeatureから別のfeatureを直接importするとエラー。
必要なら shared/ 経由にする。
これは、feature間のべたべたした依存を防ぐルールです。
機能Aが機能Bの中身を知り始めると、境界がすぐ溶けます。
AIは特に「近いものを勝手に使う」傾向があるので、こういう禁止ルールはかなり有効だと思います。
routes/ などの外側から feature の内部ディレクトリを直接参照するとエラー。
つまり、外部は Public API だけを使う。
これはモジュールの境界を守るための、かなり分かりやすい仕組みです。
外から触れる面が少ないほど、AIも人間も迷いにくい。設計としてきれいです。
shared は共通部品置き場であって、特定featureの事情を知ってはいけない。
依存の向きは必ず features/ → shared/。
このルールがないと、shared が“なんでもあり箱”になります。
私はこの手の shared が肥大化していく様子を何度も見てきたので、ここを明示的に縛るのはかなり賢いと思います。
dependency-cruiserだけでは足りないので、他のツールも組み合わせています。
AIがリファクタリングすると、不要になったexportやファイルが残りがちです。
人間が全部追い切るのは大変なので、未使用コード検出の knip で洗い出す。
これは実務でかなり効くはずです。
放置された不要コードは、見た目以上に設計を濁らせます。AIは特に「残骸」を置いていきやすいので、こういう掃除役は重要です。
Biome は lint と format を担うツールです。
AIが出しがちな
any 型などを検出します。
ここも地味に大事です。
AIは動くコードを出すことはあっても、型安全性を雑に削ってでも通そうとすることがある。だからこそ、Biomeのような機械的なチェックが必要になります。
![]()
記事では、これらのツールを lefthook で Git hooks に統合しています。
Git hooks というのは、コミットや push の前に自動で走る仕組みです。
この分け方がとても実戦的です。
コミット時には速いチェックを置き、時間のかかるものは push 時に回す。
これ、かなりバランスがいいと思います。
大事なのは、レビューで止めるのではなく、手元で止めることです。
エラーを早く返せば、AIも人間もすぐ修正できる。
これはまさに Shift-Left Testing の発想で、開発のなるべく左側、つまり早い段階で問題を見つけるやり方です。
この記事の本質は、「AIのために特別な設計を発明しなくていい」ということだと思います。
必要なのは、AI専用の魔法ではなくて、
という、かなり基本的で、でもちゃんと効く設計です。
率直に言うと、これはとても健全です。
AIが入ると派手な話に引っ張られがちですが、実際に現場を助けるのはこういう地味なルールだったりします。
「AIにうまく書かせる」のではなく、AIが雑に書いても壊れにくい構造を先につくる。この発想は、かなり現実的で強いです。
この記事を一言でまとめるなら、
良い設計をAIに任せるのではなく、良い設計をAIでも壊せないようにする、という話です。
そのために必要なのは:
個人的には、この記事は「AI開発の話」というより、ソフトウェア設計の原則をもう一段実務寄りに引き戻した話として読むと面白いと思います。
AIがいてもいなくても、良い設計は良い。
ただ、AIがいる今は、その良さが以前よりずっと効く。そこが時代の変化なんだろうな、と思います。
参考: AIのための特別なアーキテクチャはいらない ― 0→1開発で実践した設計原則とガードレール - カミナシ エンジニアブログ
