中国の巨大IT企業テンセントが、大規模言語モデルファミリー「Tencent HY」の新モデルとして「Hy3 preview」を公開しました。しかも、ただの研究発表ではなくオープンソース公開です。ここはかなり重要で、実際に触ったり改良したりしやすい形で出してきた、ということになります。
最近のAI界隈は「とにかく巨大」「でも高い」「でも賢い」という三つ巴の戦いになっていますが、Hy3 previewはその中で**“性能とコスト効率のバランス”**を強く打ち出しているのが面白いところです。正直、こういう方向性はかなり現実的だと思います。モデルが賢くても、使うたびにお金が溶けるようでは普及しませんからね。
Hy3 previewは、総パラメータ数2950億、アクティブパラメータ数120億のMoE(Mixture of Experts)モデルです。
ざっくり言うと、MoEはたくさんの専門家チームを持つAIのような仕組みです。
全部のパラメータを毎回フル稼働させるのではなく、必要な専門家だけを呼び出して使うので、巨大なのに比較的効率よく動かせます。
つまりHy3 previewは、見た目はとても大きいけれど、毎回全部を使うわけではないので、性能と効率を両立しやすい設計になっているわけです。ここはかなり今っぽいです。
「でかいけど無駄に重くしない」という思想、嫌いじゃありません。
さらに、コンテキストウィンドウは最大25万トークン。
コンテキストウィンドウというのは、AIが一度に覚えていられる文章量のことです。25万トークンというのはかなり大きく、長い資料や大量の会話を扱う用途で強そうです。
Hy3 previewには、レイテンシ(返答の速さ)と深度(じっくり考える力)のどちらを優先するかに応じた3つの推論モードがあります。
これは実用上かなり大事です。
たとえば、
みたいに使い分けられるなら、モデルの使い道がかなり広がります。
個人的には、AIは「最高性能の一点突破」だけでなく、場面に応じて挙動を切り替えられることが今後もっと重要になると思います。

テンセントは2026年2月に、事前学習と強化学習のインフラを再構築したそうです。
そして、実用的なAIを作るための原則として次の3つを挙げています。
この考え方はかなり興味深いです。
AI業界では、ベンチマークの点数を上げること自体はよくありますが、それが本当に現場で役立つかは別問題です。公開ベンチマークは、極端に言えば“試験対策”みたいなことが起こりうるので、テンセントはそこを警戒しているわけです。
ここはかなり筋が通っていると思います。
「テストで強い」より「実際に使って強い」の方が、結局は価値がありますから。
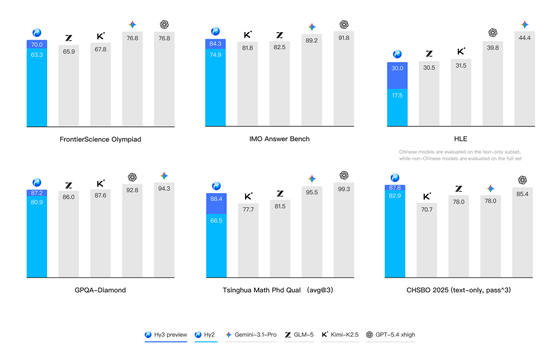
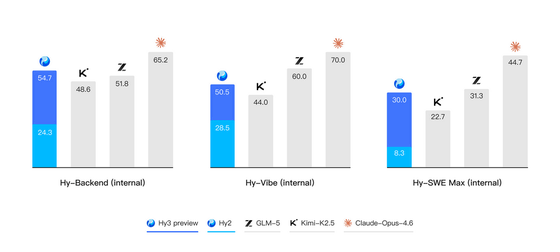
テンセントによると、Hy3 previewは複雑な推論、指示追従、コンテキスト学習、コーディング、エージェントタスクで大きく改善されたとのことです。

記事では、難易度の高いSTEM系ベンチマークや大学の博士課程入試、中国高校生物オリンピックなどで比較したグラフが紹介されており、前モデルHy2より全体的にスコアが上がっているとされています。
さらに、実務に近いシナリオで作られたベンチマークでは、Gemini 3.1 ProやGPT-5.4 xhighに匹敵するスコアを記録したケースもあるそうです。
ただし、ここはテンセント側の発表なので、読む側としては
「かなり強そうだが、実際の使い勝手は自分で試したい」
くらいの温度感がちょうどいいと思います。ベンチマークは大事ですが、現実の仕事はもっと泥くさいですからね。
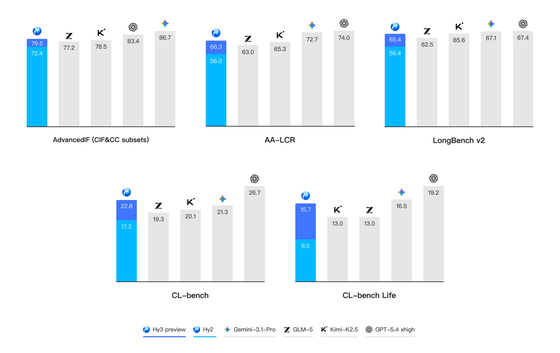
Hy3 previewは、コーディングエージェントや検索エージェントのベンチマークでも競争力のあるスコアを出したとされています。
ここは今のAIトレンドをよく表しています。
単なる会話AIではなく、今は
といった**“エージェント”**の能力がかなり重視されています。
つまり、AIが「答えるだけ」から「手を動かす」方向に進んでいるわけです。
Hy3 previewはその流れに乗っていて、しかもオープンソース。
この組み合わせは、研究者や開発者にはかなり魅力的ではないでしょうか。
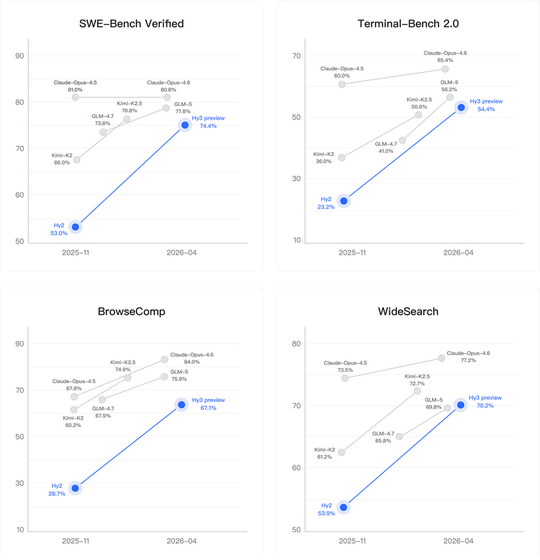
テンセントは、Hy3 previewの特徴の1つとしてパラメータ規模に対する性能の良さを強調しています。
記事中の比較では、Hy3 previewは
という立ち位置だと紹介されています。
これはかなり面白いポイントです。
AIモデルの世界では、単純に「大きい=強い」とは言い切れなくなってきています。むしろ、どれだけ少ない計算でどれだけ出せるかが勝負になりつつあります。
個人的には、この方向性はかなり健全だと思います。
巨大モデルの“殴り合い”も派手で面白いですが、最終的には安く・速く・そこそこ賢いモデルが勝つ場面が増えるはずです。
テンセントはHy3 previewについて、ツール呼び出し時のエラー回復が弱いことや、推論ハイパーパラメータへの感度が高いといった既知の制限も認めています。
ここが好印象です。
AI企業の発表は、どうしても“良い話”ばかりになりがちですが、テンセントは現時点での弱点も明示していて、かなり実務的です。
というのは、実際の運用では地味に重要です。
「デモでは動いたけど本番では怪しい」というのはAIあるあるなので、ここを今後どう改善するかが見どころだと思います。
Hy3 previewは以下で公開されています。
APIの料金は、0〜16K入力ティアの場合で
です。
この価格はかなり攻めています。
もちろん用途や条件で変わるので単純比較はできませんが、**高性能モデルを“安く使えるかもしれない”**という期待は十分あります。ここは実際にサービスを作る人ほど刺さるはずです。
Hy3 previewは、単に巨大なだけのモデルではなく、効率性、長文処理、推論、コーディング、エージェント対応まで含めて、かなり総合力を狙ったモデルだと感じます。
特に印象的なのは、テンセントが「ベンチマークの見栄え」よりも現実の使い勝手とコスト効率をかなり意識している点です。
AIは性能競争のフェーズを抜け切ってはいませんが、同時に「どう実際に使われるか」のフェーズにも入っています。Hy3 previewは、その流れをよく表すモデルだと思います。
今後気になるのは、
あたりです。
発表時点ではかなり強そうですが、本当の勝負はここからではないでしょうか。
参考: テンセントが高性能推論モデル「Hy3 preview」を公開、295B-A21BなMoEモデルで高い効率性 - GIGAZINE
