DeepSeekが DeepSeek-V4 Preview を公開しました。しかも「Preview」という名前ではあるものの、すでに open-sourced され、APIでも使える状態です。
要するに、ただの予告編ではなく、かなり本気で“次の主力”を見せに来た感じです。こういう発表、技術好きとしてはかなりワクワクします。
特に目を引くのは、1M context length。
これは、モデルが一度に読める文字量・トークン量が非常に大きいという意味で、ざっくり言うと「超長文をまとめて扱える」能力です。長いPDF、巨大なコードベース、複数資料をまたぐ調査などで威力を発揮します。ここは本当に大きいです。正直、1Mはかなり“景色が変わる”数字だと思います。

今回の発表では、用途の違う2つのモデルが案内されています。
ここでいう closed-source model は、内部の仕組みや重みが公開されていない商用モデルのことです。
要するに、オープンなモデルなのに、非公開の超強力モデルに迫る、というかなり野心的な位置づけです。これは普通に面白いです。
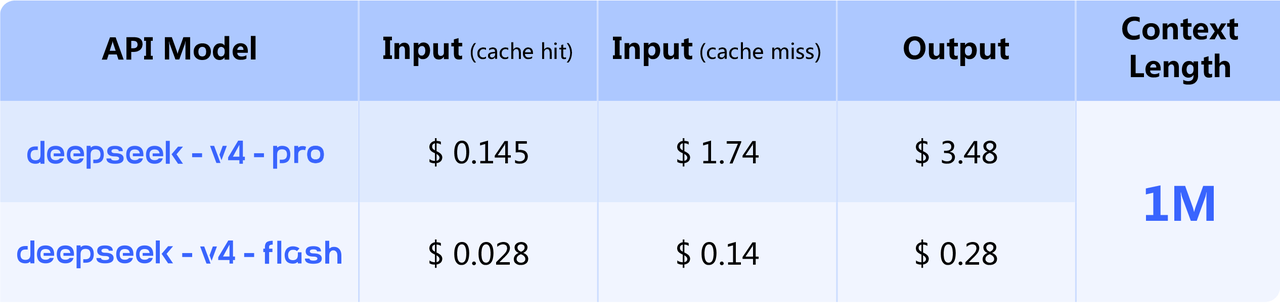
こちらは「軽快さ重視」のモデルです。
全部盛りのProに対して、Flashは“速さとコスパの申し子”という印象ですね。日常的なAPI利用では、むしろこういうモデルのほうがありがたい場面は多いと思います。性能だけでなく、待ち時間と料金はかなり重要ですから。
今回の発表で一番インパクトがあるのは、やはり 1M context でしょう。
contextとは、AIが会話や資料を覚えておける“作業机の広さ”みたいなものです。
広ければ広いほど、長い会話や大量の資料を一気に見ながら回答できます。
DeepSeekはこの1M contextを、全公式サービスで標準化 したとしています。
しかも、単に長く読めるだけではなく、token-wise compression と DSA(DeepSeek Sparse Attention) という仕組みで、計算コストやメモリ消費をかなり抑えているとのこと。

ここは地味にすごいです。
長文対応モデルは世の中に増えてきましたが、「長く読める」だけだと、たいてい重くて高いんですよね。DeepSeekはそこを“安く・効率よく”やろうとしている。
この方向性はかなり現実的で、実務向きだと思います。
今回の発表では、Agentic Capabilities が強く押し出されています。
Agent というのは、単に文章を返すだけでなく、
といった“自律的に動くAI”のことです。
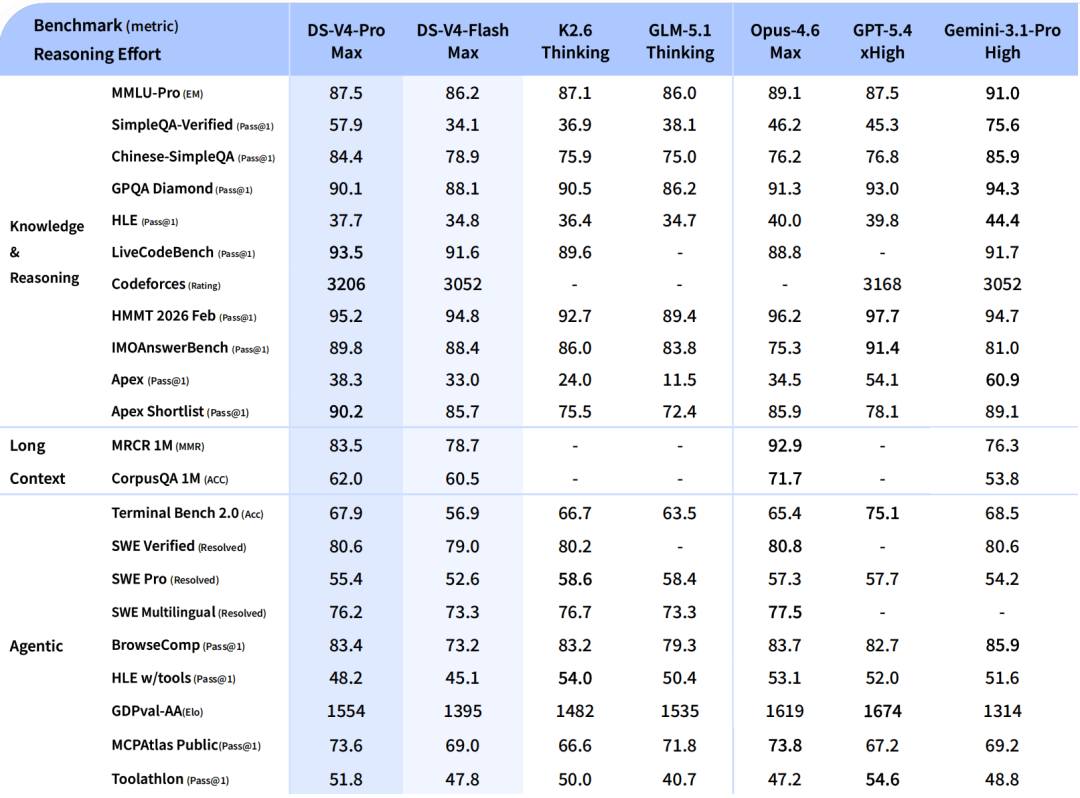
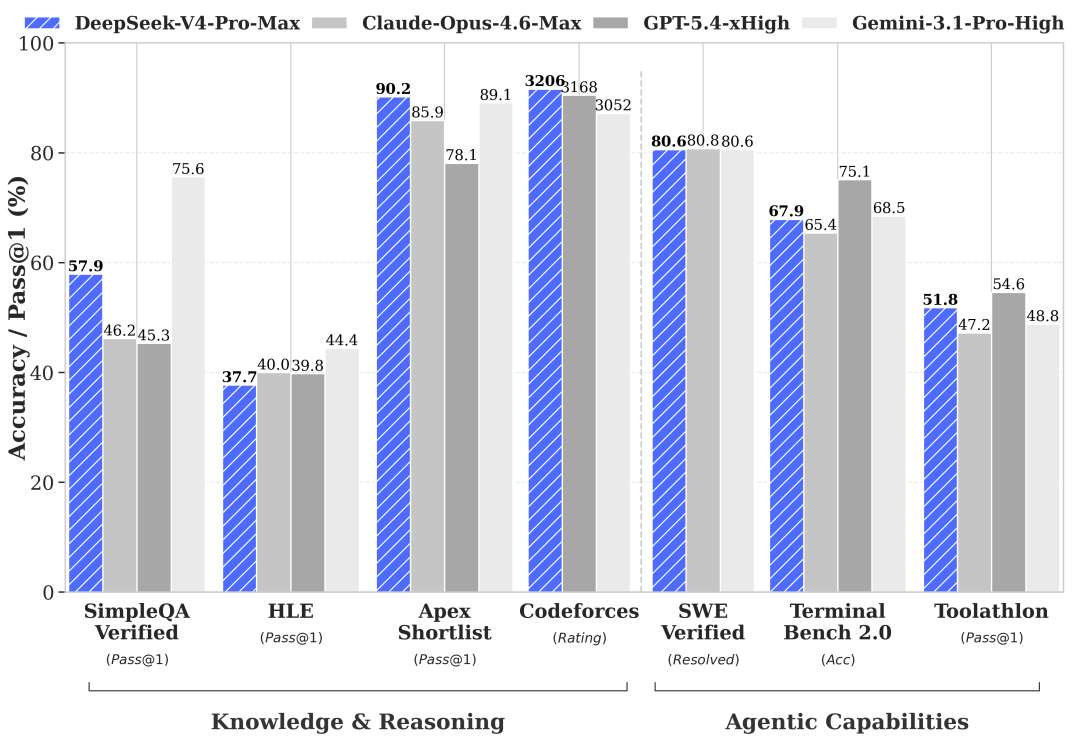
DeepSeek-V4-Proは、Agentic Coding benchmarks でオープンソース系SOTAだとされています。
SOTAは “State Of The Art” の略で、その分野で最先端、という意味です。
さらに、Claude Code、OpenClaw、OpenCode などの主要なAIエージェントとの統合も進んでいるとのこと。
個人的には、ここがかなり重要です。モデル単体のベンチマークが良くても、実際にはエージェントツール群と気持ちよくつながるかどうかで使い勝手がかなり変わるからです。
すでにAPIは利用可能で、使い方もわかりやすいです。
この「既存の設定をあまり壊さずに乗り換えられる」感じ、すごく大事です。
新モデルが出ても、接続先や書き方が毎回大きく変わると現場ではつらいんですよね。DeepSeekはここをかなり意識していて、実際の開発者にはかなりありがたい設計だと思います。
ざっくり言うと、
です。
用途によって切り替えられるのは便利です。難問にはThinking、軽い応答にはNon-Thinking、みたいに使い分けられそうです。
注意点もあります。
記事には、deepseek-chat と deepseek-reasoner は 2026年7月24日 15:59 UTC 以降に完全終了すると明記されています。
しかも現在は、これらが deepseek-v4-flash の non-thinking / thinking にルーティングされているとのこと。
つまり、見た目は旧モデル名を使っていても、中では新モデルに寄っている状態です。
この手の移行は、開発者にとっては「今すぐ困るわけではないけど、放置すると後で痛い」やつです。
なので、早めに新しいmodel名へ移しておくのが安全だと思います。
率直にいうと、今回の発表は「性能が高いです」だけで終わっていないのが面白いです。

DeepSeekは、
をまとめて押し出しています。
つまり、単なる“ベンチマーク勝負”ではなく、実際に使われる土台を取りに行っている感じがあります。
この戦い方はかなり賢いです。AIは結局、賢さだけではなく「使いやすさ」「安さ」「つなぎやすさ」で選ばれるので、そこをまとめて押さえに来たのは強いと思います。
一方で、もちろん実際の評価は、これからユーザーがどう使うか次第です。
ベンチマークが強くても、現場での安定性や速度、出力の癖などで印象は変わります。なので、ここはまだ“期待大”という段階ではないかと思います。

DeepSeek-V4 Previewは、かなり本気のアップデートです。
とくに 1M context と Agent向け最適化、そして Pro/Flashの使い分け は、実運用をかなり意識した設計に見えます。
「高性能なモデルが出た」というだけでなく、長文を安く扱える時代を本格的に押し進めに来た、というのが今回のポイントでしょう。
個人的には、これはかなり重要な一歩だと思います。AIモデルの競争が、単なる賢さ比べから“どれだけ実用に落とし込めるか”の勝負に移ってきた感じがします。
この記事はAIにより自動生成されました
