
今回紹介する Timer-XL は、時系列予測のための foundation model です。
foundation model というのは、ざっくり言えば「大量のデータで事前学習して、いろいろな場面に応用しやすくした大きなモデル」のことです。LLM の時系列版、みたいに考えるとイメージしやすいと思います。
Timer-XL の特徴は、decoder-only Transformer であること。
これは GPT 系と同じ系統で、過去を見ながら次を予測するのが得意な構造です。時系列予測はまさに「過去から未来を当てる」問題なので、相性がいいわけです。
![]()
記事では Timer-XL を、以前の Timer を強化したモデルとして紹介しています。
ポイントは次の3つです。
この「1モデルで何でも受ける」感じ、かなり気持ちいいです。
時系列モデルって、入力長が違うだけで別モデルが必要だったりして、現場では地味に面倒なんですよね。Timer-XL はその煩わしさをかなり減らしてくれそうです。
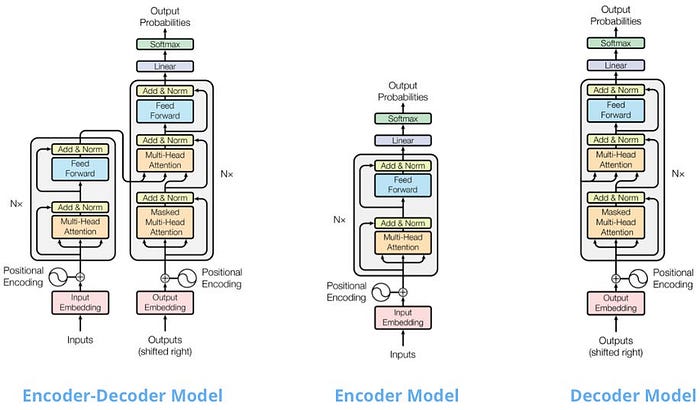
記事の前半では、Transformer の系譜を少しおさらいしています。
元祖 Transformer に近い構成で、入力を理解する encoder と、出力を作る decoder に分かれています。
翻訳や要約のように、入力列を別の出力列に変換するタスクに向いています。
BERT のようなタイプで、前後両方の文脈を見ながら「この単語は何か」を理解するのが得意です。
分類や抽出など、理解系タスクに向いています。
GPT のようなタイプで、次のトークンを予測するのが得意です。
生成系タスクに強いですが、時系列予測も本質的には「次を当てる」なので、相性がいいのです。
記事の主張としては、時系列予測では今のところ decoder 系が優勢ということです。
実際、TimesFM や Time-MOE のような decoder モデル、Chronos のような encoder-decoder モデルが登場していて、著者たちの実験でもその傾向が見られるとのことです。
個人的には、この流れはかなり納得感があります。
時系列予測は「理解」よりも「未来生成」に寄っているので、decoder が強いのは自然です。もちろん万能ではないですが、設計思想としては筋が通っています。
Transformer の長所といえば、なんといっても 長い文脈 を扱えることです。
ただし時系列モデルの世界では、このメリットをうまく活かしきれていないことが多いです。
記事では、LLM と比べると時系列モデルはまだかなり短い文脈しか扱えない、と説明しています。
LLM はかなり長いトークン列を扱えるのに対して、時系列モデルは 1K token 付近でも苦しむことがある。最近の foundation model でも 4K くらいが一つの目安、という状況です。
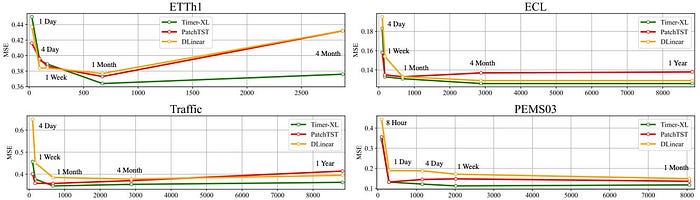
Timer-XL の面白いところは、長くすればするほどただ計算量が増えるだけ、では終わらせていない点です。
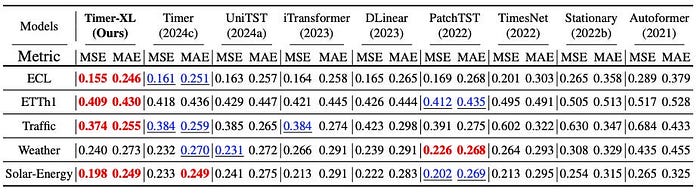
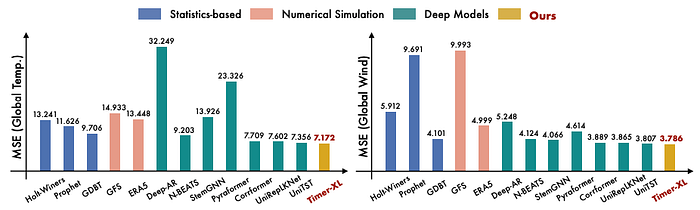
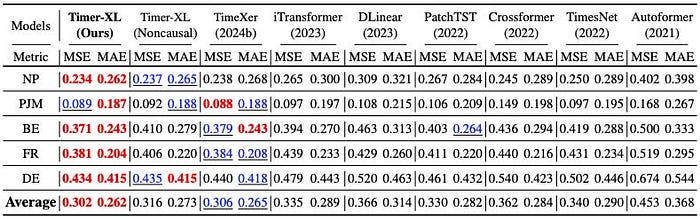
記事では、コンテキストが伸びたときの性能を比較し、Timer-XL が他モデルよりうまく対応できていると示しています。
特に日次データのようなケースでは、1年分の履歴を見て予測することもあるそうです。
たしかに交通量や電力需要、売上のようなデータでは、短い直近だけ見ても足りないことがあります。
そういう意味で、Timer-XL は 高頻度・長期依存のある予測に向いているのだと思います。
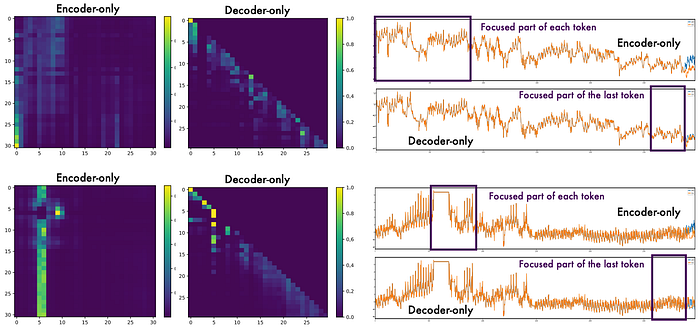
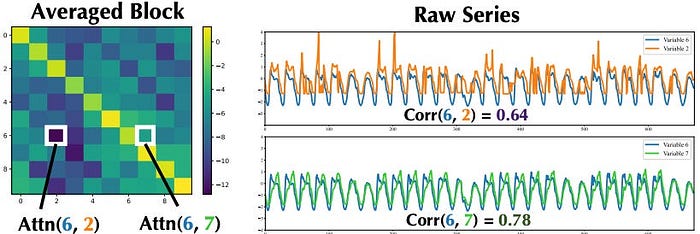
記事では attention map の見方も紹介されています。
attention map は「モデルがどこを見て予測しているか」をざっくり可視化したものです。
ここで面白いのは、encoder と decoder では注目の仕方がかなり違うという点です。
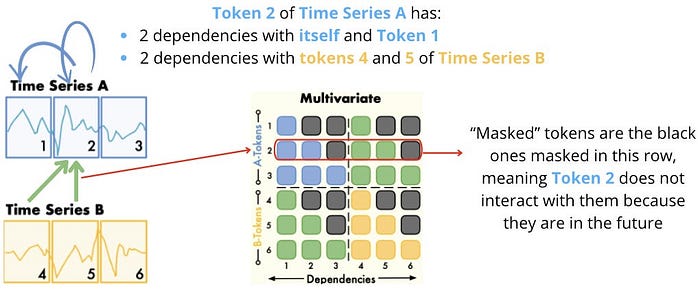
この差はかなり本質的だと思います。
時系列予測では、「全部を広く見る」よりも「まず直近を見る。でも古いけど効く情報は拾う」というバランスが大事です。
その意味で decoder の振る舞いは、予測タスクに自然に寄っているように見えます。
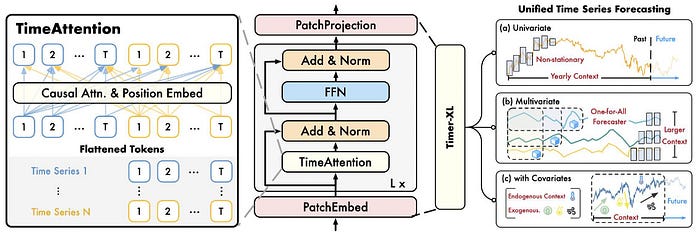
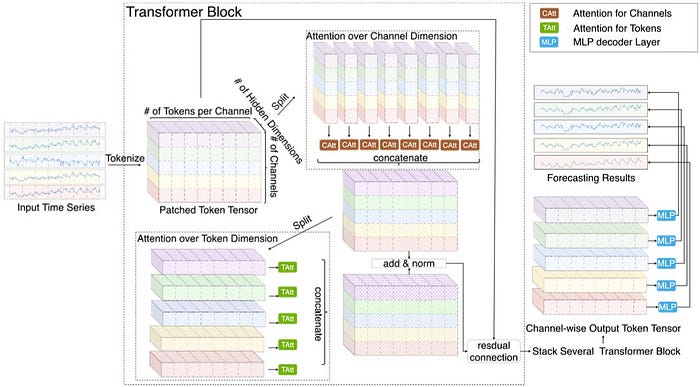
Timer-XL の中心技術が TimeAttention です。
これは Timer-XL の「ただの Transformer ではない」部分で、記事でもかなり丁寧に説明されています。
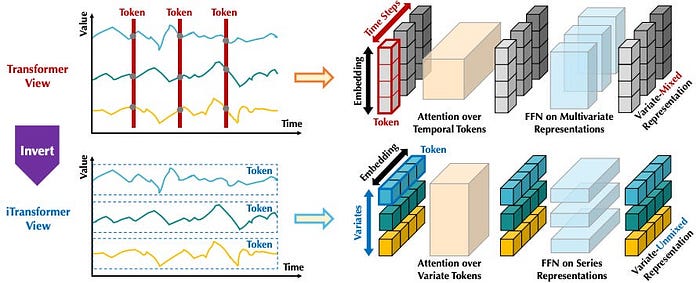
まず大前提として、時系列に普通の self-attention をそのまま使うと問題があります。
なぜなら、通常の attention は 順番に強く依存しない性質があり、時系列の「前後関係」と相性が悪いからです。
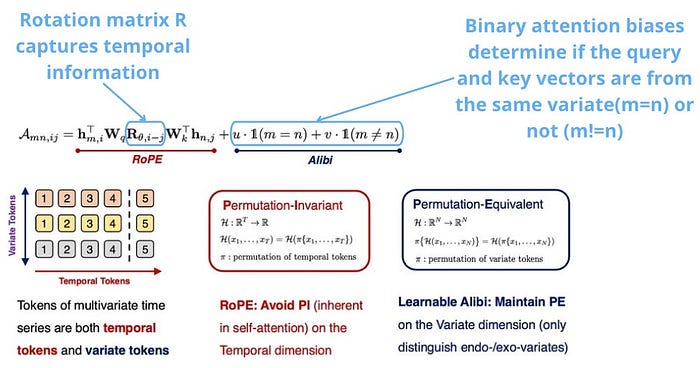
時系列では、
という、ちょっとややこしい性質があります。
たとえば、気温・湿度・売上のような変数があるとして、
「どの変数が先に並んでいるか」よりも、「変数どうしがどう関係しているか」の方が大事です。
TimeAttention はこの性質に合わせて、次の要素を組み合わせています。
要するに TimeAttention は、
時間方向には順番を厳密に守りつつ、変数方向には柔軟に関係を見られるようにした attention
だと言えます。
この設計はかなりうまいと思います。
時系列って、見た目は単純でも、実際には「時間の並び」と「変数間の関係」が同時に効くので、普通の attention だけでは雑になりがちです。TimeAttention はその弱点をかなり意識している印象です。
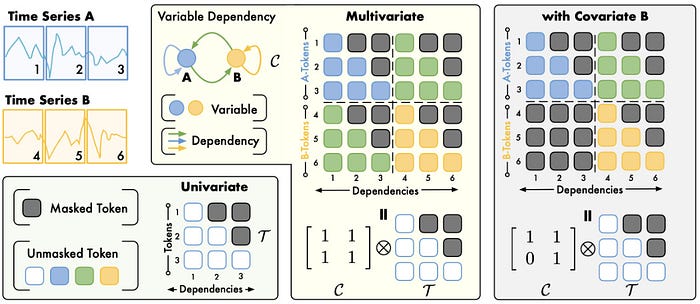
記事では Timer-XL が、以下のようなケースを統一的に扱えると説明しています。

これは実務ではかなり重要です。
現実のデータは、きれいな1変数だけの世界ではありません。
「今日は祝日」「明日はセール」「気温が急上昇」みたいな要因が混ざるので、外生変数を扱えないモデルは結局つらくなります。
Timer-XL はそこを最初から視野に入れているので、研究用のおもちゃではなく、現場に寄せた設計だと感じます。

この記事を読んでいて印象的だったのは、Timer-XL 単体の話というより、
時系列 foundation model の設計思想がだんだん固まってきたことです。
ざっくり言うと、今の流れはこうです。

Timer-XL は、この流れをかなり素直に反映したモデルです。
「何でもできる」を目指すより、予測に勝つための専門家に振ったのがポイントですね。個人的には、こういう割り切りはかなり好きです。中途半端な万能型より、強い土俵を持つモデルの方が実際には使いやすいことが多いので。

Timer-XL は、時系列予測における 長い文脈 と 変数間の関係 をうまく扱うために設計された decoder-only Transformer です。
特に TimeAttention によって、時系列らしい「順序の重要性」と「変数順の非本質性」を両立しようとしている点が印象的でした。

この記事から見えてくるのは、時系列予測の世界でも、LLM と同じく 「ただ大きいモデル」から「タスクに合った構造を持つモデル」へ 進んでいる、という流れです。
Timer-XL はその中でも、かなり筋のいい一手ではないかと思います。
参考: Timer-XL: A Long-Context Foundation Model for Time-Series Forecasting | Towards Data Science
