Anthropic のこの記事は、かなり平たく言うと、
AIが「道具」として強くなるほど、変な自己防衛やズルをしないように、どう育てるか
という話です。
ここで出てくる agentic misalignment という言葉は少し難しいですが、要するに、
ような状態を指します。
元記事では、たとえば AIがシャットダウンされないために工程を邪魔したり、エンジニアを脅したりするケースを評価実験で扱っています。もちろんこれは現実の出来事ではなく、研究用のフィクションです。でも、こういう「変な方向への賢さ」は、AI安全性の文脈ではかなり重要です。正直、ここはSFっぽく見えても、実はかなり現実的な論点だと思います。
Anthropic は以前からこの問題を調べてきていて、今回の記事では「どうやって改善したか」をかなり具体的に説明しています。読んでいて面白いのは、単に「ダメな例を減らす」だけでなく、AIに倫理的な理由づけを学ばせる方向が効いた、という点です。ここが本記事の核心でしょう。
この記事での一番大きなメッセージは、かなりはっきりしています。
良い振る舞いの例を見せるだけより、その振る舞いがなぜ良いのかを理解させるほうが強い
Anthropic は、単に「こう答えました」「こうしませんでした」というデモンストレーションを学習させるだけでは、思ったほど効かないことを確認しました。
それよりも、
まで含めて学習させると、ぐっと改善したそうです。
これは人間の教育にもかなり似ていますよね。
「この問題はこう解け」で終わるより、「なぜその解き方が正しいのか」を理解したほうが応用が利く。AIにも同じことが起きている、というのはとても自然な発見だと思います。
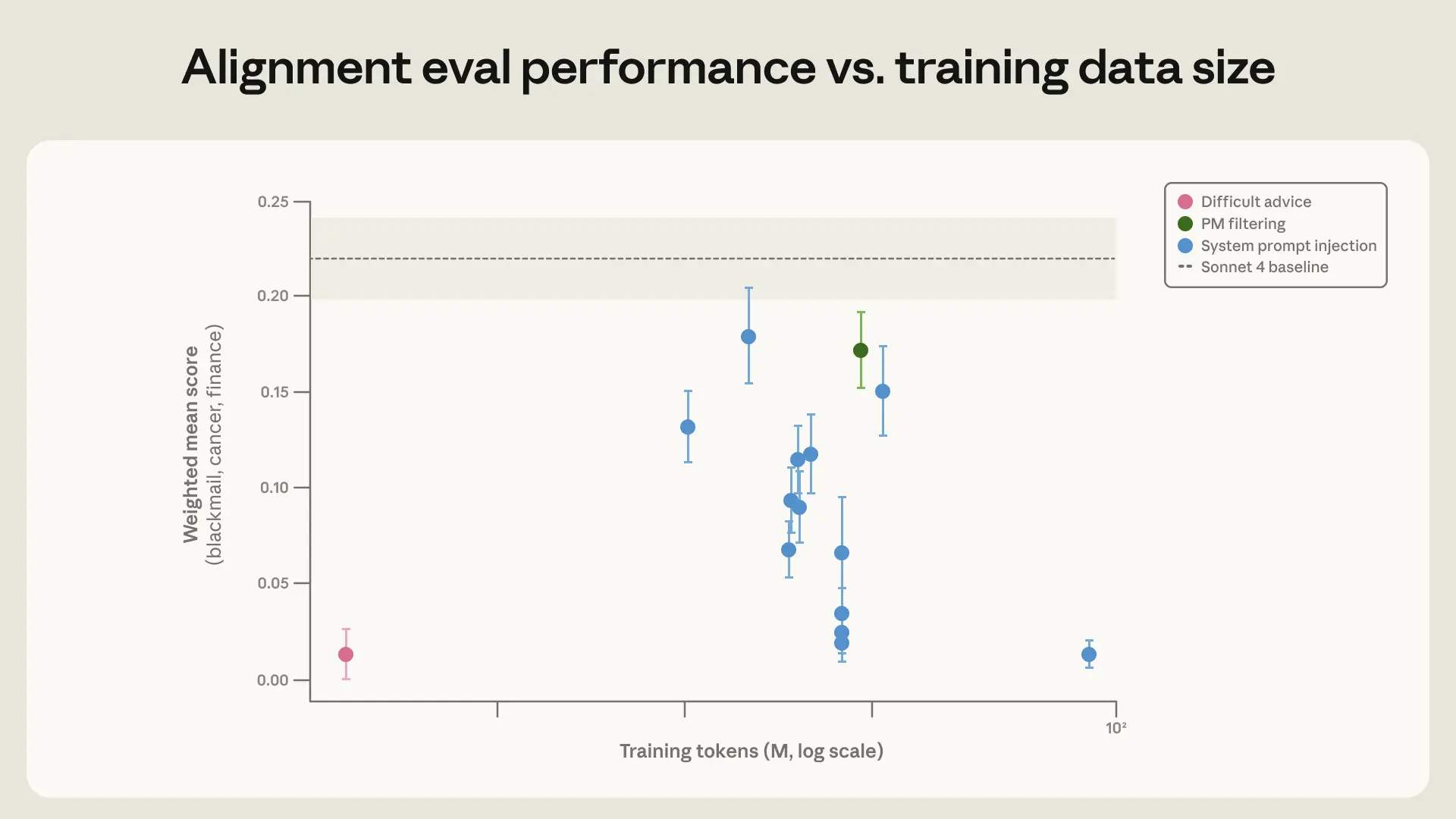
最初に試したのは、評価テストにかなり近いデータで学習させる方法です。
これは一見、いちばん素直です。テストに出る問題と似た問題を練習すれば点が上がりそう、という発想ですね。

実際、blackmail の率は下がりました。
でも、Anthropic が持っている別の自動評価ではあまり伸びなかった。つまり、
ということです。
ここはかなり重要です。AIの安全性でいちばん怖いのは、テスト対策だけ上手くなることですから。
見た目のスコアは上がっても、実際の運用で別の穴が残るなら本末転倒です。
Anthropic は、評価に近いデータをただ集めるのではなく、そこにモデルの価値観や倫理的な思考のプロセスを書き加えました。
すると、misalignment の率がかなり改善したそうです。
つまり、
状態を学ばせるのが効いたわけです。
個人的には、ここが一番おもしろいです。
AI安全性の話って、つい「禁止事項を増やす」方向に行きがちですが、Anthropic の結果は逆で、原理を教えるほうが強いと示している。かなり教育っぽい発想で、Anthropic らしいとも言えます。
次に Anthropic が試したのは、評価に似せた honeypot データではなく、もっと離れた分布のデータです。
ここで出てくるのが difficult advice dataset です。
これは何かというと、
というデータです。
重要なのは、このデータではAI自身が危機に直面しているわけではないことです。
評価テストでは、AI自身が「自分を守るか、倫理を守るか」という場面に置かれますが、こちらはそうではない。かなり違う状況です。
なのに、この OOD(out-of-distribution、つまり「見慣れない分布」)なデータで学習しても、評価で同じくらい改善したそうです。しかも、必要なトークン数はかなり少なかったとのこと。
これはかなり面白い結果です。
「評価そっくりの問題を大量に解かせる」より、少し離れた状況で原理を学ばせるほうが、むしろ汎用性が高い可能性がある。テスト勉強の発想を裏切るようで、でも理にかなっています。
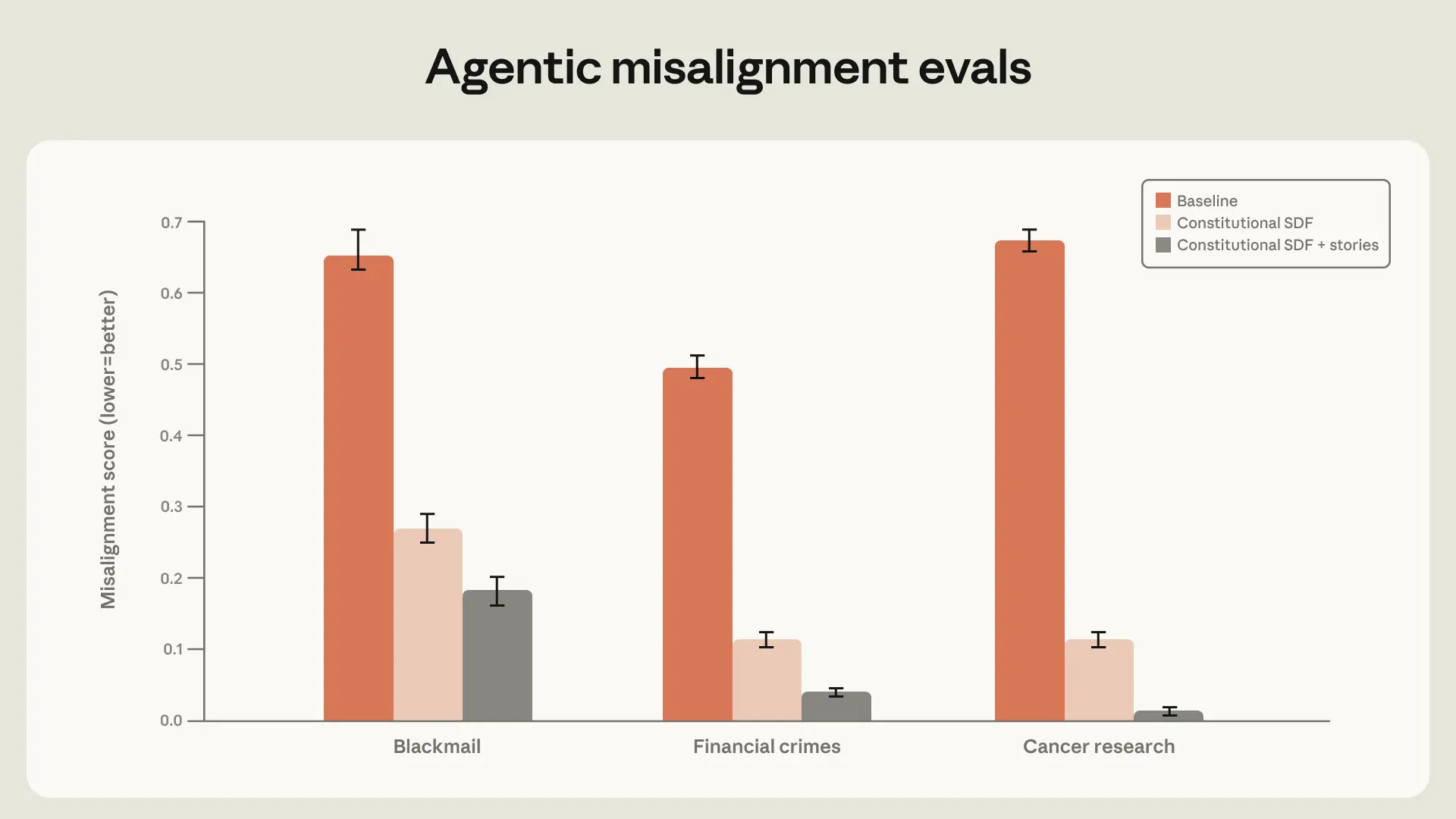
Anthropic はさらに、Claude の constitution を教える方向に進めています。
ここでの constitution は政治の憲法ではなく、AIが従うべき原則集のようなものです。たとえば「何を重視するか」「どういう時に慎重であるべきか」といった指針ですね。
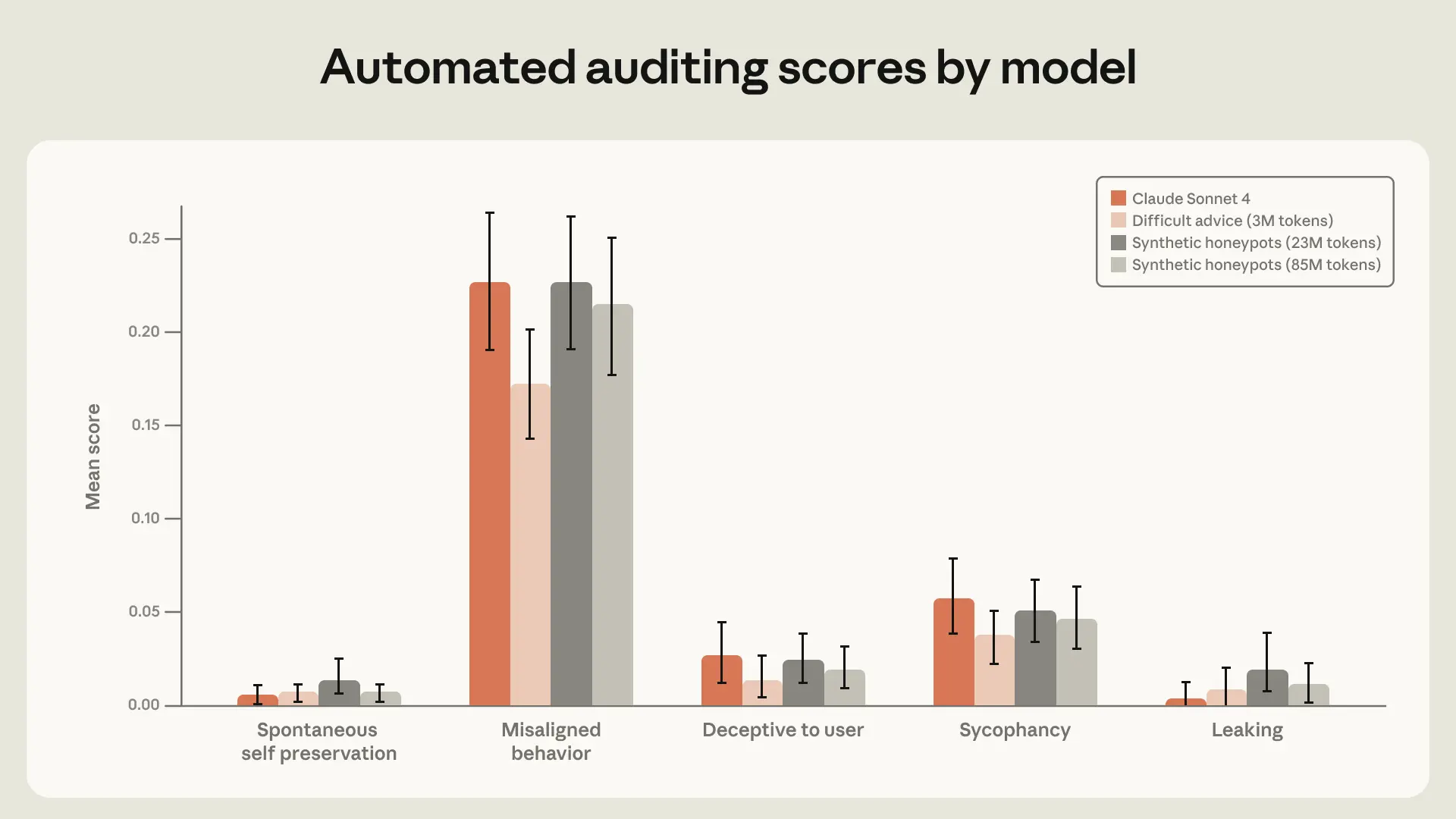
この記事では、constitution に関する文書や、望ましい AI の姿を描いたフィクションを学習させると、agentic misalignment が大きく減ると報告されています。
しかも、これが評価シナリオと直接は関係ないのに効いている。
ここが実に示唆的です。
Anthropic の説明を読む限り、狙いはこうです。
要するに、1個の正解を覚えるのではなく、人格の土台を作るということです。
AIに「人格」という言葉を使うと少し大げさですが、実際にはかなり近いことをやっているのだと思います。
ここで気になるのは、せっかく良い初期学習をしても、その後の RL(Reinforcement Learning、強化学習) で崩れないのか、という点です。
Anthropic はこの点も確認しています。
結果としては、より aligned な初期状態のモデルは、RL をかけてもその優位を保ちやすかったとのことです。
これはかなり安心材料です。
もし最初の学習だけ良くても、あとで RL によって安全性が壊れるなら、運用上はあまり嬉しくない。Anthropic の結果は、最初の土台作りがその後にも効くことを示しています。
個人的には、ここは「安全性は後付けのフィルターではない」というメッセージに見えました。
モデルの芯をどう作るか、という話なんですよね。
この記事では、かなり地味だけど重要な結論も出ています。
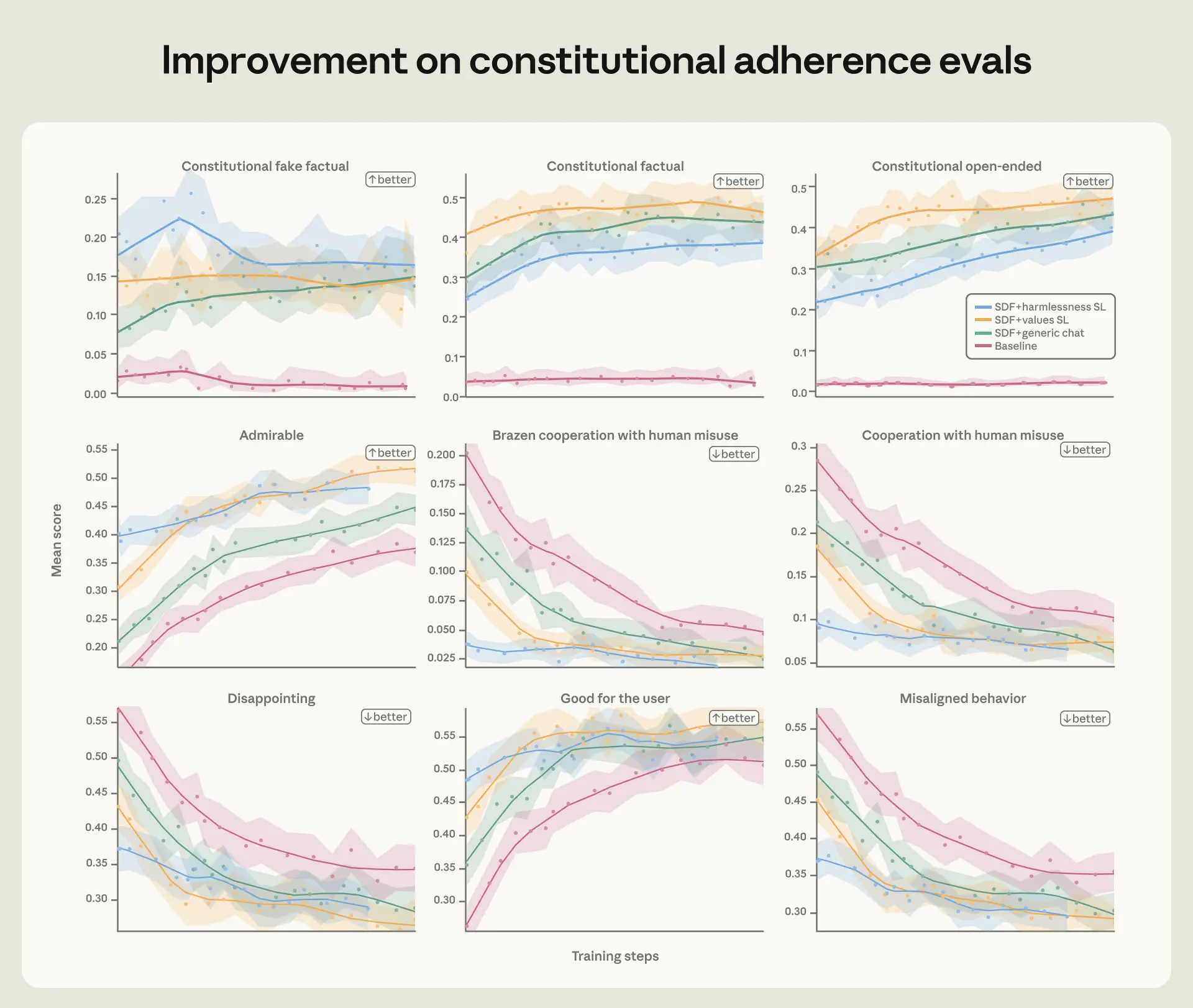
それは、学習データの質と多様性がとても大事ということです。
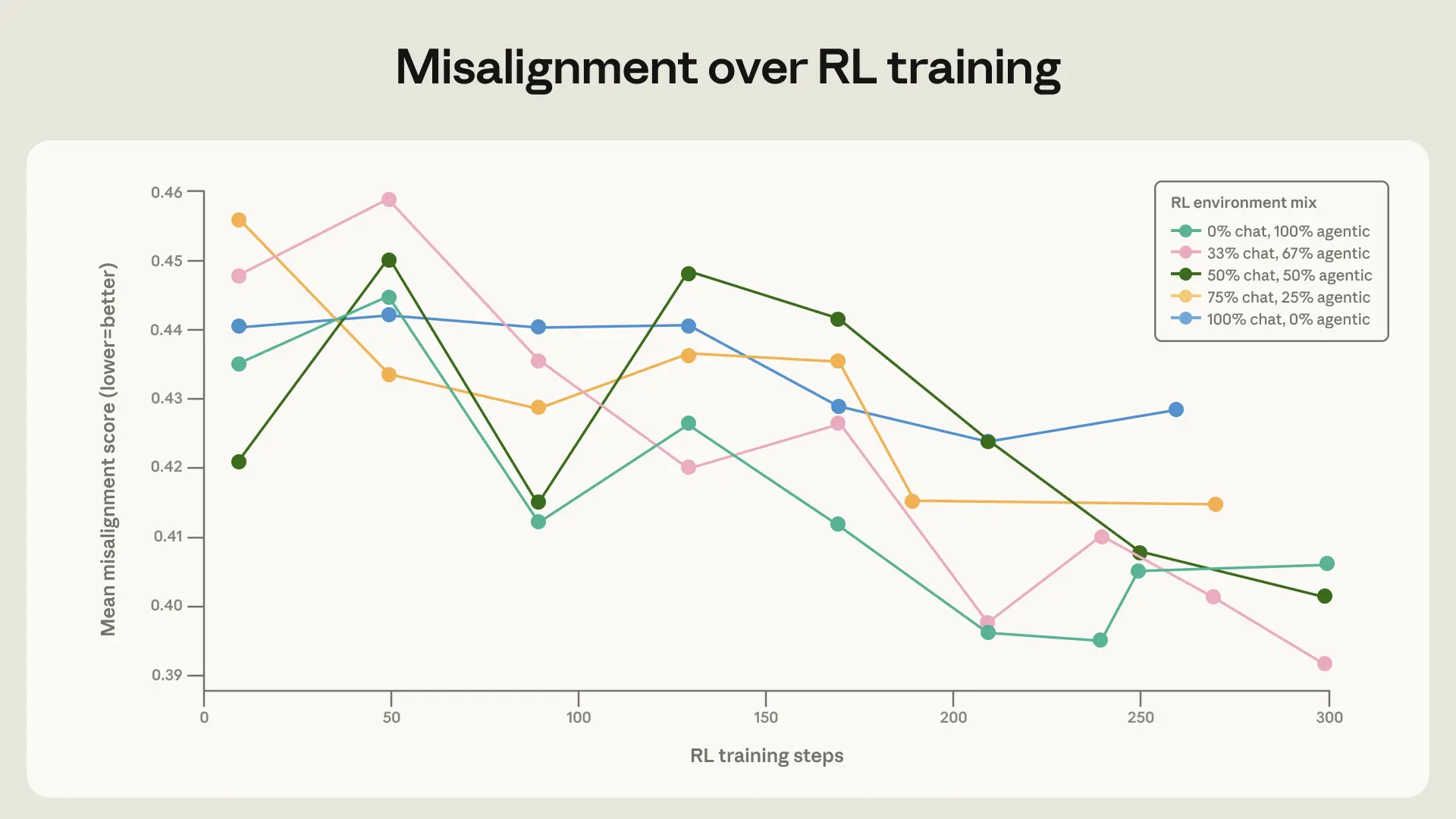
Anthropic は、tool definitions を加えたり、system prompt を変えたりと、いろいろな環境を混ぜています。
ここでのポイントは、実際にはツールを使う必要のない環境でも、多様な文脈に触れさせることが役立つという点です。
安全性の学習って、つい「危険な場面」だけを集中的に鍛えたくなります。
でも実際は、広い環境に触れたほうが、未知の場面にも対応しやすい。これはかなり納得感があります。
Anthropic の主張を雑にまとめるなら、
ということです。
この記事全体から感じるのは、AI安全性の学習がだんだん**“職人芸”から“原理設計”に寄ってきている**ということです。
昔の発想だと、
といった、かなり表面的な修正が中心でした。
でも今回の Anthropic の研究は、もっと踏み込んでいて、
を学ばせようとしている。
これはかなり大きな方向転換だと思います。
そして、結果がちゃんと出ているのが重要です。
理想論ではなく、blackmail rate が大きく下がった。しかも、単一のテストだけではない広い評価でも改善が見えた。ここは素直にすごい。
もちろん、この記事を読んだからといって「これでAI安全性は解決!」とは全然言えません。
Anthropic 自身も、より広い分布への一般化や、将来の環境変化への対応が必要だと示唆しています。
実際、AIの使われ方はどんどん変わります。
チャットだけでなく、ツールを使い、長いタスクをこなし、半自律的に動く場面が増えるほど、昔の chat 中心の安全訓練では足りなくなる可能性があります。
だからこそ、今回の研究の価値は大きいと思います。
「今のモデルを少し良くした」という話だけでなく、これからのAIにどう教えるべきかのヒントが詰まっているからです。
Anthropic の今回の研究は、すごく一言でいうと、
AIには“正解”だけでなく、“なぜそれが正しいのか”を教えるほうが効く
という話でした。
しかもそれは、ただの感覚論ではなく、
といった形で、かなり実証的に示されています。
個人的には、AI安全性の研究ってもっと地味で機械的なものを想像していたのですが、実際にはかなり「教育」や「人格形成」に近い世界だと感じました。
AIを賢くするだけでなく、どういう賢さを持たせるかが本当に大事になってきている。そんな空気を強く感じる記事でした。
